It is time to move on from preliminary logical considerations to key foundational issues relevant to design theory.
Of these, the challenge of complexity, information and functionally specific organisation is first and foremost. Hence this post.
We live in a technological age, and one that increasingly pivots around information. One in which we are surrounded by trillions of technological entities showing how what we can describe as functionally specific, complex organisation and/or associated information (FSCO/I for short) is a characteristic result and highly reliable indicator of intelligently directed configuration. That is, of design.
For simple illustration, we may examine the exploded view of a 6500 C3 baitcasting reel:
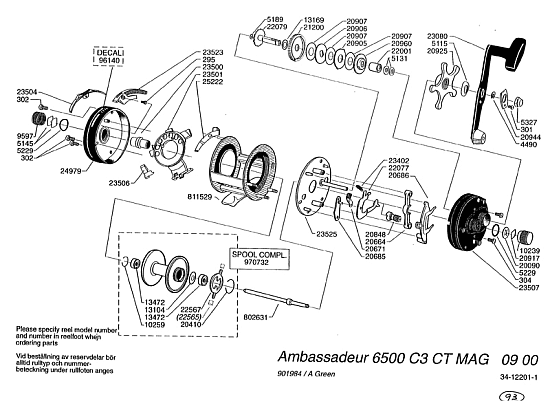 . . . which shows the characteristic pattern of a network of highly specific parts, correctly oriented and arranged in a nodes-and-arcs pattern per what J S Wicken described as a “wiring diagram” that is contrived to result in the relevant function.
. . . which shows the characteristic pattern of a network of highly specific parts, correctly oriented and arranged in a nodes-and-arcs pattern per what J S Wicken described as a “wiring diagram” that is contrived to result in the relevant function.
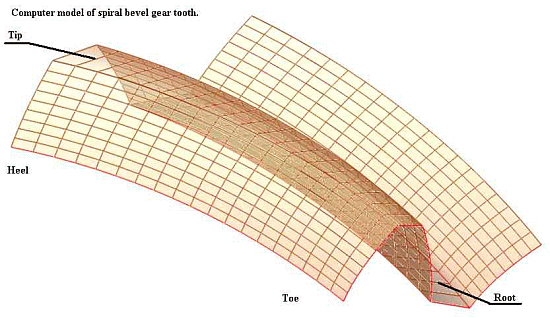
That pattern, can be further illustrated by the gearing, which itself shows how precise and organised even components may need to be for function to result:

 Likewise, we may examine a petroleum refinery in outline as an example of a process-flow network that also exemplifies FSCO/I:
Likewise, we may examine a petroleum refinery in outline as an example of a process-flow network that also exemplifies FSCO/I:

Patently, such a pattern reflecting FSCO/I — recall, this is a description — is highly informational, and may be expressed in terms of a chain of yes/no questions in accord with the rules and conventions of a description language that specifies components, arrangement and coupling etc. (Indeed, that is what AutoCAD and other applications packages for engineering design do.)
In such a context, with reasonable coding, description length is an index of degree of complexity.
In effect, simple frameworks are easy to describe and quite complicated ones are hard to describe.
Further to such, composite or configured entities like the above are inherently contingent and as they become ever more complex, there is a combinatorial explosion of the number of abstractly possible description strings of a given length, in accord with p = 2^n. For 500 bits, there are 3.27 *10^150 possibilities from 000 . . . 0 to 111 . . . 1, and for 1,000, there are 1.07*10^301. Obviously, of these only a relative few are relevantly functional, leading to an increasingly difficult search challenge in the possibility space.
Which, we can usefully picture as a search for islands of function in a much larger sea of non-functional configurations:
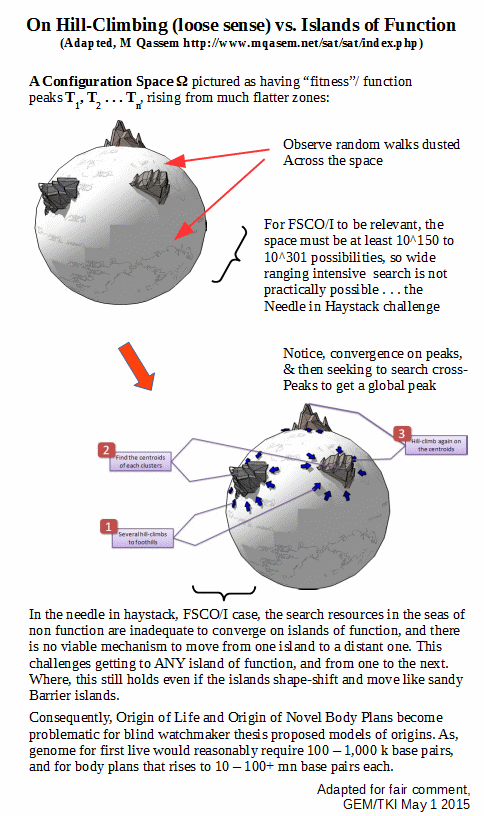
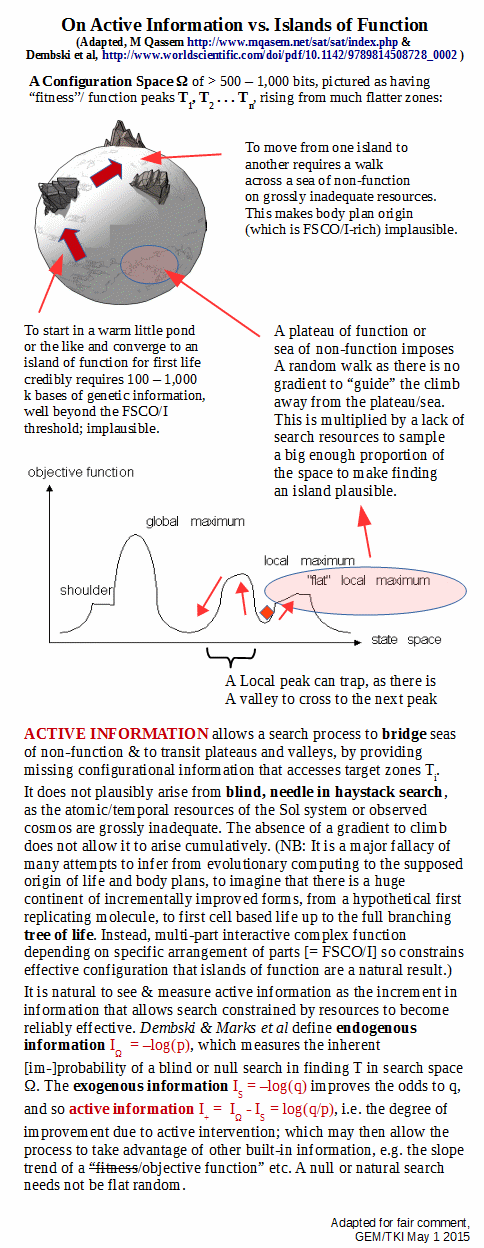
Further to this, there are challenges to “island-finding” (or, needle in haystack search) and to “hill-climbing” in the broad sense once there is a possibility of roughness in the functional islands:
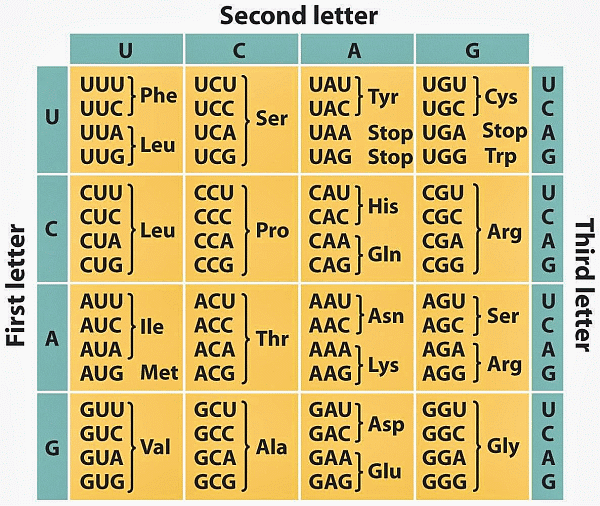
This is immediately relevant to the world of life, as we can see from the genetic code-based cellular protein synthesis process (in which the R/DNA is a molecular, string data structure bearing coded machine language level information at up to two bits per four-state base . . . G/C/A/T or U . . . used to control protein assembly):
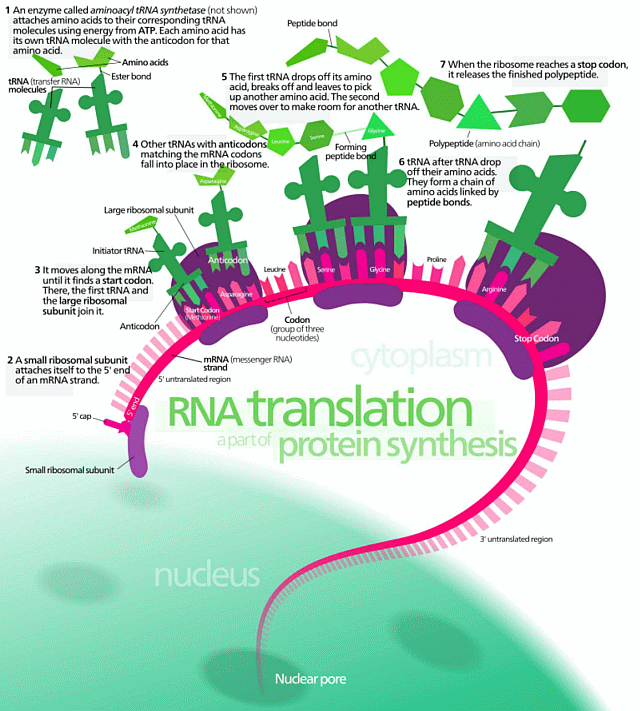
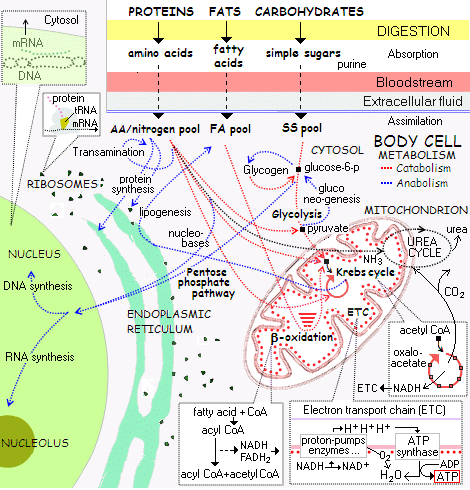
. . . and from the wider metabolic process (where, the above is a bit in the upper left corner):
To underscore the force of this, I add, a clip (HT, CH) from eminent Chemist James Tour on making Chemical sense of evolutionary claims at OOL and for origin of body plan level co-ordinated features:
[youtube _TAUw4pvbug]
Where also, the code-based protein assembly system immediately implies the existence of irreducibly complex communication networks and linked codes:
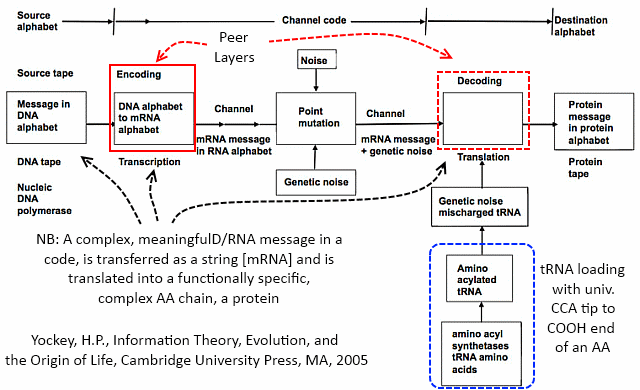
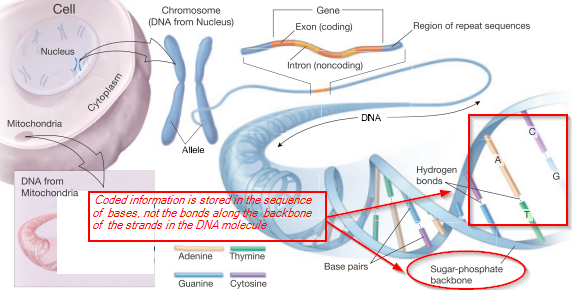
This system or its equivalent is an integral part of cell based life as we observe it.Which,per the vera causa principle, is what is to be causally explained on the evidence of observed adequate cause for the FSCO/I involved.
Such a pattern and the principle of restraining speculation regarding traces from the remote past of origins on observed adequate cause, therefore raises the question as to whether the technological entities we see being caused all around us and the world of cell based life from its root in cells and their origin up, have a similar root-cause process, intelligently directed configuration, aka design. In effect, is the presence of FSCO/I (beyond 500 – 1,000 bits) or the like a reliable sign of design as most credible causal explanation?
That is the context in which Steve Laufmann recently argued:
Evolutionary biology was very much like other sciences up until the 1950s, when the information-bearing capabilities of DNA and RNA were discovered inside living cells.
These discoveries fundamentally changed biology. And as the information payload is increasingly unraveled, we’re seeing ever more complex and interdependent assembly instructions, activation circuits, programming sequences, and message payloads. This information is decoded and operated on by molecular machines of similar complexity, and the whole (information + machines) is self-generating, self-sustaining, and self-replicating . . . .
Further, based on the observed functionality in living organisms, there are many undiscovered types of information that must be present in a living cell, but which haven’t been decoded or understood yet.
Kinesin offers a fascinating example of undiscovered information in action. What programs and machinery are required to assemble the structure and function of kinesin? What information is needed for kinesin to achieve its “runtime” functions? How does kinesin know where to go to pick up a load, what load to pick up, what path to take, and where to drop its load? How does it know what to do next? All this functionality takes information, which must be encoded somewhere.
Indeed, the level of complexity is monotonically increasing, with no end in sight.
With no possibility that new discoveries will ever decrease the observed complexity, it may not be long before we see a seismic shift in the research paradigm — from the study of biological systems that happen to contain information, to the study of information systems that happen to be encoded in biology . . . [“Evolution’s Grand Challenge,” ENV, July 10 2015.]
Later in the article, he challenges:
The origin of life is perhaps the most obvious example of information’s formidable hurdle to evolutionary explanations. First life requires all of the following:
- Sufficient complex programs and sequencing to support first life’s complete lifecycle (i.e., the directions have to be complete and correct).
- Sufficient machinery to interpret the programs and to operate life (i.e., the directions must have proper effect).
- Sufficient programs and machinery to replicate both the programs and the machinery (i.e., the directions must be passed to the next generation).
And all this must be present at the same time, in the same place, in at least one instant in history, at which point the whole must somehow be animated to create life. And all this must occur, by definition, before an organism can reproduce. Without reproduction, there is no possibility to accumulate function, from simple to complex, as required by evolution. Hence, the programs must have contained all the complexity required for first life at inception.
By definition, then, the minimal programs and machinery required for first life must have predated any creative capabilities (real or imagined) of Darwinian processes.
Further, since the information necessary for first life must have been assembled prior to the animation of first life, the minimal information payload must have predated first life. And it must therefore have derived from a source beyond biology as we know it . . .
Noting that we can identify two major categories of observed causal forces (blind chance and/or necessity on one hand and design on the other) he then remarks:
For materialists, the first class of causal force is insufficient and the second is unacceptable. Materialist biologists are thus pressed to find a third class of causal force — one that works without purpose (required to adhere to materialist philosophy), yet produces purposeful outcomes (required to adhere to the observed world). As yet no reasonable candidate forces have been proposed.
So materialists face growing dissonance between their philosophical commitment and biology’s complex programming. As the quality and quantity of the discovered interdependent programs and processing machinery increases, the plausibility of material causation gets weaker. So the materialist position is weak, and going in the wrong direction (from their perspective).
On the other hand, for anyone not fully committed to materialist philosophy the options are much more interesting. For those willing to consider the second class of causal force, things begin to fall into place and the dissonance dissipates.
A major reason for this is illustrated by Kirk Durston in a recent ENV discussion:
Biological life requires thousands of different protein families, about 70 percent of which are “globular” proteins, with a three-dimensional shape that is unique to each family of proteins . . . This 3D shape is necessary for a particular biological function and is determined by the sequence of the different amino acids that make up that protein. In other words, it is not biology that determines the shape, but physics. Sequences that produce stable, functional 3D structures are so rare that scientists today do not attempt to find them using random sequence libraries. Instead, they use information they have obtained from reverse-engineering biological proteins to intelligently design artificial proteins.
Indeed, our 21st-century supercomputers are not powerful enough to crunch the variables and locate novel 3D structures. Nonetheless, a foundational prediction of neo-Darwinian theory is that a ploddingly slow evolutionary process consisting of genetic drift, mutations, insertions, and deletions must be able to “find” not just one, but thousands of sequences pre-determined by physics that will have different stable, functional 3D structures. So how does this falsifiable prediction hold up when tested against real data? . . . .
I downloaded 3,751 aligned sequences for the Ribosomal S7 domain, part of a universal protein essential for all life. When the data was run through the program, it revealed that the lower limit for the amount of functional information required to code for this domain is 332 Fits (Functional Bits). The extreme upper limit for the number of sequences that might be functional for this domain is around 10^92. In a single trial, the probability of obtaining a sequence that would be functional for the Ribosomal S7 domain is 1 chance in 10^100 … and this is only for a 148 amino acid structural domain, much smaller than an average protein.
For another example, I downloaded 4,986 aligned sequences for the ABC-3 family of proteins and ran it through the program. The results indicate that the probability of obtaining, in a single trial, a functional ABC-3 sequence is around 1 chance in 10^128. This method ignores pairwise and higher order relationships within the sequence that would vastly limit the number of functional sequences by many orders of magnitude, reducing the probability even further by many orders of magnitude — so this gives us a best-case estimate.
What are the implications of these results, obtained from actual data, for the fundamental prediction of neo-Darwinian theory mentioned above? If we assume 10^30 life forms with a fast replication rate of 30 minutes and a huge genome with a very high mutation rate over a period of 10 billion years, an extreme upper limit for the total number of mutations for all of life’s history would be around 10^43. Unfortunately, a protein domain such as Ribosomal S7 would require a minimum average of 10^100 trials. In other words, the sum total of mutational events for the entire theoretical history of life falls short by at least 57 orders of magnitude from what would have a reasonable expectation of “finding” any RS7 sequence — and this is only for one domain. Forget about “finding” an average sized protein, not to mention thousands. [“Computing the ‘Best Case’ Probability of Proteins from Actual Data, and Falsifying a Prediction of Darwinism,” ENV, July 28, 2015.]
He then challenges:
Could natural selection come to the rescue? As we know from genetic algorithms, an evolutionary “search” will only work for hill-climbing problems, not for “needle in a haystack” problems. There are small proteins that require such low levels of functional information to perform simple binding tasks that they form a nice hill-climbing problem that can be easily located in a search. This is not the case, however, for the vast majority of protein families. As real data shows, the probability of finding a functional sequence for one average protein family is so low, there is virtually zero chance of obtaining it anywhere in this universe over its entire history — never mind finding thousands of protein families.
What are the implications for intelligent design science? A testable, falsifiable hypothesis of intelligent design can be stated as follows:
A unique attribute of an intelligent mind is the ability to produce effects requiring a statistically significant level of functional information.
Given the above testable hypothesis, if we observe an effect that requires a statistically significant level of functional information, we can conclude there is an intelligent mind behind the effect. The average protein family requires a statistically significant level of functional, or prescriptive, information. Therefore, the genomes of life have the fingerprints of an intelligent source all over them.
So, right from the root up:
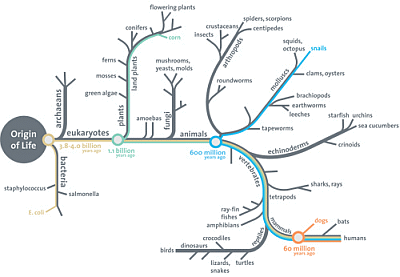
. . . the Darwin-style tree of life, far from being a triumphant icon of the power of natural selection acting on blind watchmaker engines of chance variation, is instead a profound challenge to that framework.
But, doesn’t evolution based on differential reproductive success break any imagined analogy between technology and life forms?
First, despite many insistent attempts to dismiss “information,” “codes,” “communication networks,” etc as dubious analogies, we are plainly dealing with instances of a common pattern, descriptively termed functionally specific complex organisation and/or associated information. Where also, family resemblance of similar cases is a key basis for inductive reasoning, which though defeasible can in fact be strongly warranted to moral certainty. And despite those who would now balk at acknowledging that inductive reasoning (and especially abductive inference to best explanation) is central to science, that induction is at the heart of science is patently so.
We may illustrate:
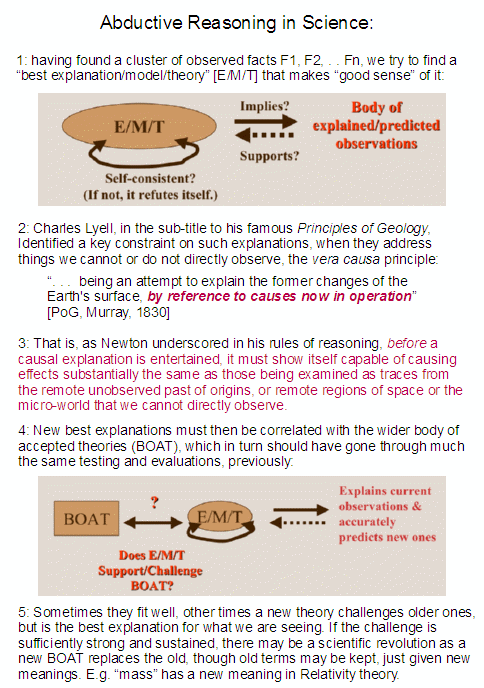 Next, it is already on the table that the root of the tree of life, i.e. DNA and protein/enzyme based, self-replicating metabolising, cell based life is the first thing to be explained. (Where, we now have a challenge that has been on the table for several years to Darwinists to submit an essay that grounds evolution from the root up, which has had s no significant answer after several years.)
Next, it is already on the table that the root of the tree of life, i.e. DNA and protein/enzyme based, self-replicating metabolising, cell based life is the first thing to be explained. (Where, we now have a challenge that has been on the table for several years to Darwinists to submit an essay that grounds evolution from the root up, which has had s no significant answer after several years.)
As Mignea (2012) put the challenge:
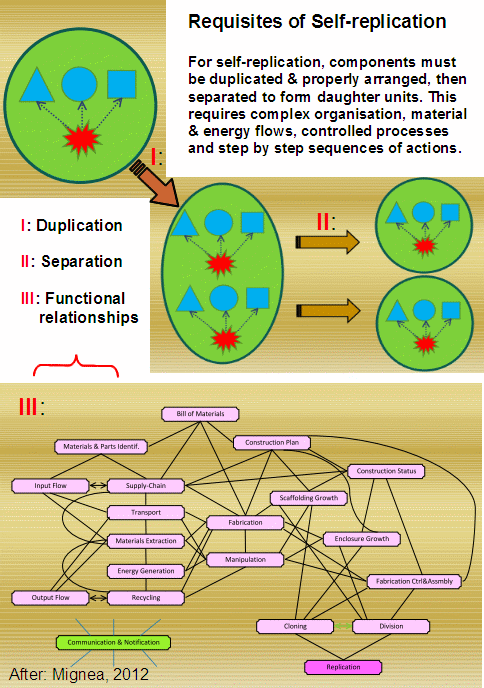
Until that origin of cell-based life [OOL] with the copious FSCO/I in it is explained on observed, demonstrated adequate blind watchmaker forces of physics and chemistry, we are fully entitled to infer to the strong evidence of the trillion member observational base and the linked needle in haystack search challenge, and hold that the best explanation of the FSCO/I in life is design.
Indeed, the challenge pre-dates Darwin.
When Paley comes up in discussions on design, his analogy of stumbling across a stone vs finding a watch in the field is often put on the table as a flawed analogy because reproduction and evolution on natural selection acting across chance variation was not taken into account.
But in fact, this is little more than a strawman caricature long since past sell-by date that pivots on our failure to simply read on, into Chapter 2 of his 1802/4 Natural Theology.
For, after the short first chapter, Paley rapidly goes on to discuss the time-keeping, self-replicating watch:
Suppose, in the next place, that the person who found the watch should after some time discover that, in addition to all the properties which he had hitherto observed in it, it possessed the unexpected property of producing in the course of its movement another watch like itself — the thing is conceivable; that it contained within it a mechanism, a system of parts — a mold, for instance, or a complex adjustment of lathes, baffles, and other tools — evidently and separately calculated for this purpose . . . .The first effect would be to increase his admiration of the contrivance, and his conviction of the consummate skill of the contriver. Whether he regarded the object of the contrivance, the distinct apparatus, the intricate, yet in many parts intelligible mechanism by which it was carried on, he would perceive in this new observation nothing but an additional reason for doing what he had already done — for referring the construction of the watch to design and to supreme art . . . . He would reflect, that though the watch before him were, in some sense, the maker of the watch, which, was fabricated in the course of its movements, yet it was in a very different sense from that in which a carpenter, for instance, is the maker of a chair — the author of its contrivance, the cause of the relation of its parts to their use.[Emphases added. (Note: It is easy to rhetorically dismiss this argument because of the context: a work of natural theology. But, since (i) valid science can be — and has been — done by theologians; since (ii) the greatest of all modern scientific books (Newton’s Principia) contains the General Scholium which is an essay in just such natural theology; and since (iii) an argument ‘s weight depends on its merits, we should not yield to such “label and dismiss” tactics. It is also worth noting Newton’s remarks that “thus much concerning God; to discourse of whom from the appearances of things, does certainly belong to Natural Philosophy [i.e. what we now call “science”].” )]
In short, Paley anticipated von Neumann’s discussion of the kinematic, self-replicator (vNSR, henceforth), which we can represent as:
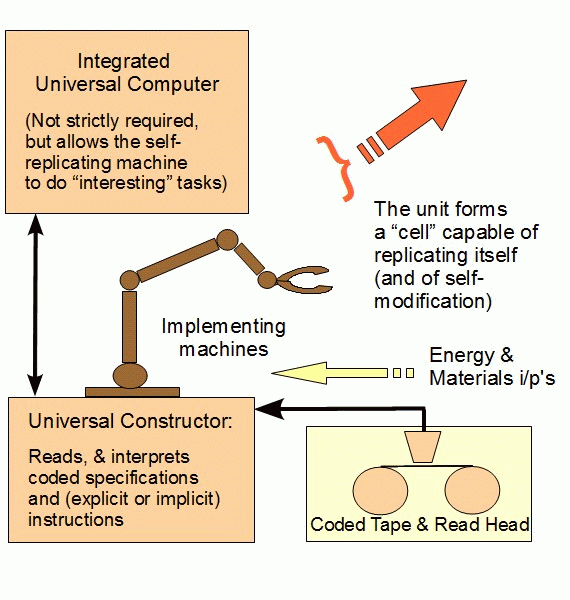 Now, following von Neumann generally (and as previously noted), such a vNSR uses . . .
Now, following von Neumann generally (and as previously noted), such a vNSR uses . . .
Immediately, as the requisites of organised function sharply constrain effective configurations in the space of possibilities, we are looking at islands of organised function for both the machinery and the information in the wider sea of possible (but mostly non-functional) configurations.
Let us recall, all of this has to be in place for a cell-based protein/enzyme using organism with the additional facility of DNA and self replication. (No, hypothetical, speculative RNA worlds etc and replicating molecules, apart from their own challenges, are not credibly relevant to the architecture of life to be explained.)
Thirdly, once design sits at the explanatory table for the tree of life as of right not grudging sufferance, from its root, it is logically present all the way to the twigs and leaves across the diverse body plans. Where, it is easy to see that such body plans will credibly require ~ 10 – 100+ mn bases, dozens of times over. And where something like the estimate for the Cambrian fossil life revolution puts a window of perhaps 10 MY for a major burst of body plans. But in fact the 13.7 BY on the conventional timeline since the big bang are nowhere near enough in an observed cosmos of ~ 10^80 atoms and fast chemical reaction rates of perhaps 10^-13 to -15 s.
Coming back full circle, we routinely observe FSCO/I as resulting from a process of intelligently directed configuration on a trillion member body of observations. Where, this is the only actually observed adequate cause. Where, further, while we show that designers capable of cr4eating FSCO/I are possible, we by no means credibly exhaust or limit the possibility of other designers, nor is our having hands, brains etc a necessary constraint on serious candidate designers.
So, we are epistemically entitled to use inductive, scientific reasoning and put at the table design — i.e. process of intelligently directed configuration as best current explanation for the FSCO/I in the world of life all around us. Where, that twerdun is logically prior to whodunit, therefore we can infer to “crime” even before we have any particular “suspects” to bring into the identification lineup.
(Believe it or not, a major line of objections to design theory runs along lines of, oh you cannot infer design without knowing a designer, or that this is smuggling in inference to the suspect supernatural into the hallowed halls of by definition necessarily naturalistic science, or you design thinkers are nothing but Creationists and right-wing would be theocratic tyrants in cheap tuxedos, and the like. In fact, 2350 years ago, in The Laws, BK X, that Bible-thumping Fundy — NOT — Plato explicitly argued in terms we can summarise as chance, necessity of nature and the ART-ificial [techne], and inferred to cosmological design on the organisation of the Cosmos.)
But is this testable and falsifiable?
Yup.
Simply show that blind chance and mechanical necessity are observed adequate causes for FSCO/I.
Needless to say, after years, and dozens of attempts that tend to be based on implicit design or on the strawman notion that the design inference must be a universal code solver algorithm or causal puzzle-solver, there are no serious candidate cases.
In sum, complexity, organisation and functionally specific information as well as the credible cause of such lie at the heart of modern design thought. END
PS: Because of demonstrated insistent side tracking, it is my intention to go though a series of BTB posts, then put up a forum post for general discussion; likely over the next fortnight or so, depending. This is the first main post. I will also likely adjust posts a bit, e.g. putting in some useful links.