In the when it comes thread, an exchange has developed with GD, and I think it helpful to headline an argument at comment 49:
__________
>>I [KF] found an elementary introduction to statistical entropy very helpful, from the Russian authors Yavorsky and Pinski, in their Physics, vol I [1974]: as we consider a simple model of diffusion, let us think of ten white and ten black balls in two rows in a container.
[Inserted image, red used for convenience, rather than white:]
There is of course but one way in which there are ten whites in the top row; the balls of any one colour being for our purposes identical. But on shuffling, there are 63,504 ways to arrange five each of black and white balls in the two rows, and 6-4 distributions may occur in two ways, each with 44,100 alternatives.
So, if we for the moment see the set of balls as circulating among the various different possible arrangements at random, and spending about the same time in each possible state on average, the time the system spends in any given state will be proportionate to the relative number of ways that state may be achieved. Immediately, we see that the system will gravitate towards the cluster of more evenly distributed states. In short, we have just seen that there is a natural trend of change at random, towards the more thermodynamically probable macrostates, i.e the ones with higher statistical weights.
So “[b]y comparing the [thermodynamic] probabilities of two states of a thermodynamic system, we can establish at once the direction of the process that is [spontaneously] feasible in the given system. It will correspond to a transition from a less probable to a more probable state.” [p. 284.] This is in effect the statistical form of the 2nd law of thermodynamics.
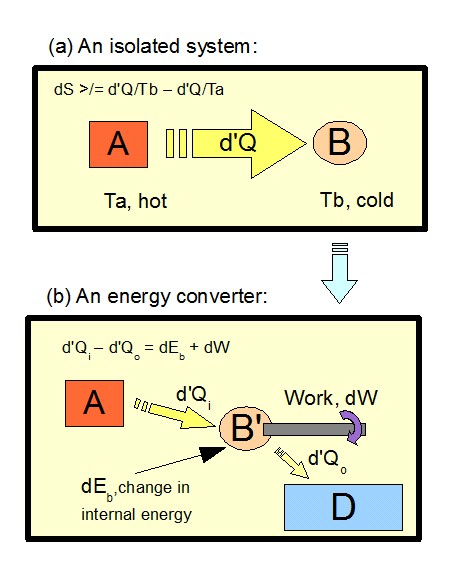
Thus, too, the behaviour of the Clausius isolated system of A and B with d’Q of heat moving A –> B by reason of B’s lower temperature is readily understood:
First, -d’Q/T_a is of smaller magnitude than + d’Q/T_b, as T_b is less than T_a and both are positive values; so we see why if we consider the observed cosmos as an isolated system — something Sears and Salinger pointed out as philosophically loaded in their textbook, the one from which I first seriously studied these matters — then a transfer or energy by reason of temperature difference [i.e. heat] will net increase entropy [here, dS]. [Note as well the added diagram panel that shows a heat engine.]
Second, we bridge to the micro view if we see how importing d’Q of random molecular energy so far increases the number of ways energy can be distributed at micro-scale in B, that the resulting rise in B’s entropy swamps the fall in A’s entropy. That is, we have just lost a lot more information about B’s micro-state than we gained about A’s.
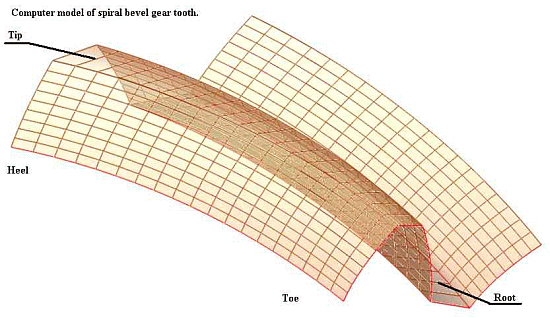
Moreover, given that FSCO/I-rich micro-arrangements [FSCO/I = “functionally specific complex organisation and/or associated information”] are relatively rare in the set of possible arrangements, we can also see why it is hard to account for the origin of such states by spontaneous processes in the scope of the observable universe.
[Insert, a favourite illustration of FSCO/I:]
[Where, just the gear teeth are already FSCO/I — observe the precise nodes-arcs mesh:]
(Of course, since it is as a rule very inconvenient to work in terms of statistical weights of macrostates [i.e W], we instead move to entropy, through [Boltzmann’s] s = k ln W or Gibbs’ more complex formulation. Part of how this is done can be seen by imagining a system in which there are W ways accessible, and imagining a partition into parts 1 and 2. W = W1*W2, as for each arrangement in 1 all accessible arrangements in 2 are possible and vice versa, but it is far more convenient to have an additive measure, i.e we need to go to logs. The constant of proportionality, k, is the famous Boltzmann constant and is in effect the universal gas constant, R, on a per molecule basis, i.e we divide R by the Avogadro Number, NA, to get: k = R/NA. The two approaches to entropy, by Clausius, and Boltzmann, of course, correspond. In real-world systems of any significant scale, the relative statistical weights are usually so disproportionate, that the classical observation that entropy naturally tends to increase, is readily apparent.)
Third, the diffusion model is a LINEAR space, a string structure.
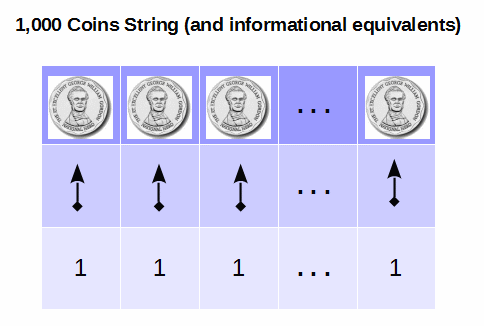
This allows us to look at strings thermodynamically and statistically. Without losing force on the basic issue, let us consider the simplest case, equiprobability of position, with an alphabet of two possibilities [B vs. W balls]. Here, we see that special arrangements that may reflect strong order or organisation are vastly rarer in the set of possibilities than those that are near the peak of this distribution. For 1,000 balls, half B and half W, the peak is obviously going to be with the balls spread out in such a way that the next ball has 50-50 odds of being B or W, maximum uncertainty.
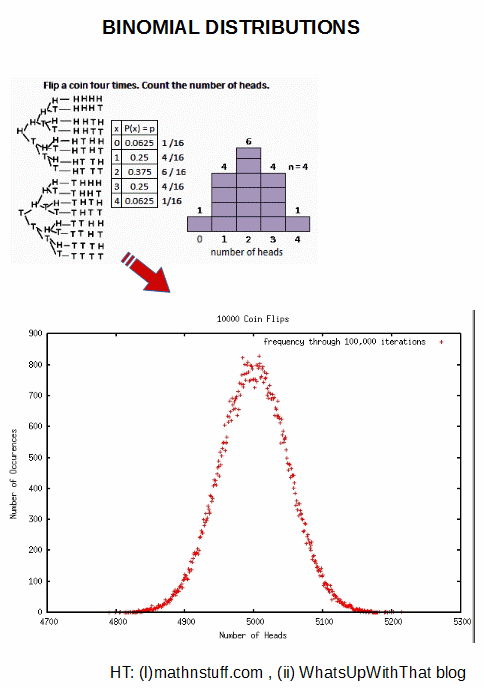
Now, let us follow L K Nash and Mandl, and go to a string of 1,000 coins or a string of paramagnetic elements in a weak field. (The latter demonstrates that the coin-string model is physically relevant.) [Insert illustration:]
We now have binary elements, and a binomial distribution with a field of binary digits, so we know there are 1.07 *10^301 possibilities from 000 . . . 0 to 111 . . . 1 inclusive. But if we cluster possibilities by proportions that are H and T, we see that there is a sharp peak near 500:500, and that by contrast there are much fewer possibilities as we approach 1,000:0 or 0:1,000. At the extremes, as the coins are identical, there is but one way each. Likewise for alternating H, T — a special arrangement, there are just two ways, H first, T first. [Insert illustration:]
[Cf. WUWT discussion, courtesy Google Images, here. Note the exercise in view: coin flips 4k – 6k H, +$1 mn, outside the band, your life. Would you take the bet? Why or why not? (Hint, it is not unrelated to see that the fluctuations around the mean are essentially unobservable beyond +/- 200 on 5,000, where the range is from 0 to 10,000. Where, SQRT (10,000) = 100. We here see a more or less empirical illustration of reasonably expected scales of fluctutations for a case like the binomial distribution. if N is of order 10^22, a typical number for molecules, we are seeing sqrt n of order 10^11, which will be unobservably sharp. [Cf. Discussion here.])]]
We now see how order accords with compressibility of description — more or less, algorithmic compressibility. To pick up one of the “typical” values near the peak, we essentially need to cite the string, while for the extremes, we need only give a brief description. this was Orgel’s point on info capacity being correlated with length of description string. Now, as we know Trevors and Abel in 2004 pointed out that code-bearing strings [or aperiodic functional ones otherwise] will resist compressibility but will be more compressible than the utterly flat random cases. This defines an island of function. [Insert, illustration:]
Trevors and Abel (pub. 2005), Three subsets of sequence complexity and their relevance to biopolymeric information, Fig 4
And we see that this is because any code or functionally specific string will naturally have in it some redundancy, there will not be a 50-50 even distribution in all cases.
There is a statistically dominant cluster, utterly overwhelmingly dominant, near 500-500 in no particular pattern or organised functional message-bearing framework. [As is illustrated.]
We can now come back to the entropy view, the peak is the high entropy, low information case. That is, if we imagine some nano-bots that can rearrange coin patterns, if they act at random, they will utterly likely produce the near-500-500 no particular order result. But now, if we instruct them with a short algorithm, they can construct all H or all T, or we can give them instructions to do HT-HT . . . etc.
Or, we can feed in ASCII code or some other description language based information.
It is conceivable that the robots could generate such codes by chance, but the degree of isolation in the space of possibilities is such that effectively these are unobservable on the scale of the observed cosmos. As, a blind random search of the space of possibilities will be maximally unlikely to hit on the highly informational patterns.
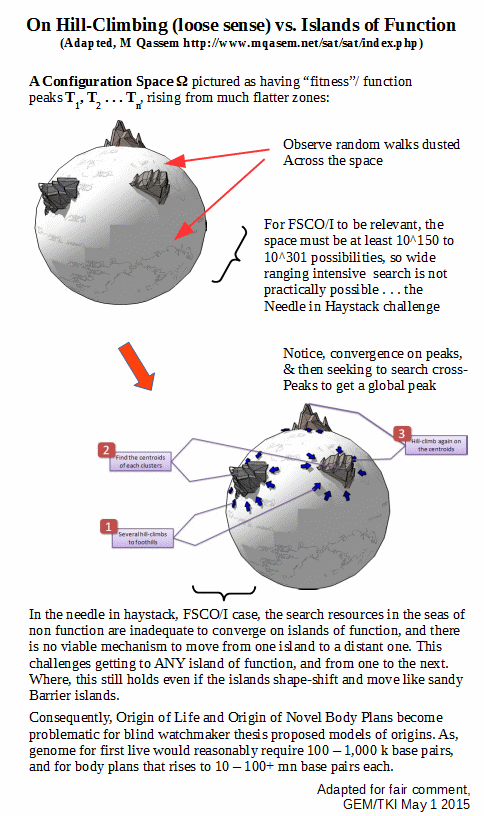
[Insert, on islands of function is a search space:]
[ –> Notice, the illustration of the implications of cumulative, step by step causally connected stages dominated by a random walk in a config space dominated by seas of non-function such that hill-climbing reinforcement cannot kick in until one hits an island of function. Where, such are quite rare in the overall space. Make the search hard enough and islands of function are unobservable. For Sol system scale, that kicks in at ~ 500 bits, and for the observable cosmos, 1,000.]
It does not matter if we were to boost the robot energy levels and speed them up to a maximum reasonable speed, that of molecular interactions and it does not matter if in effect the 10^80 atoms of the observed cosmos were given con strings and robots to flip so the strings could be flipped and read 10^12 – 14 times per s for 10^17s. Which is the sort of gamut we have available.
We can confidently infer that if we see a string of 1,000 coins in a meaningful ordered or organised pattern, they were put that way by intelligently directed work, based on information. By direct import of the statistical thermodynamic reasoning we have been using.
That is, we here see the basis for the confident and reliable inference to design on seeing FSCO/I.
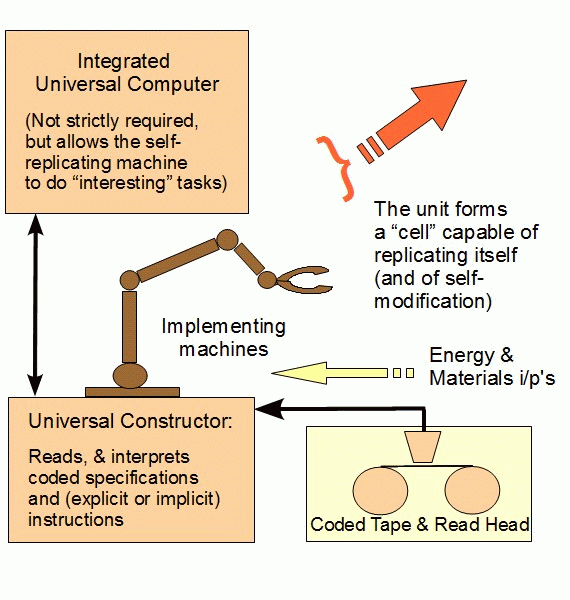
Going further, we can see that codes includes descriptions of functional organisation as per AutoCAD etc, and that such can specify any 3-d organisation of components that is functional. Where also, we can readily follow the instructions using a von Neumann universal constructor facility [make it to be self replicating and done, too] and test for observable function. Vary the instructions at random, and we soon enough see where the limits of an island of function are as function ceases.
Alternatively, we can start with a random string, and then allow our nanobots to assemble. If something works, we preserve and allow further incremental, random change.
That is, we have — as a thought exercise — an evolutionary informatics model.
And, we have seen how discussion on strings is without loss of generality, as strings can describe anything else of relevance and such descriptions can be actualised as 3-d entities through a universal constructor. Which can be self-replicating, thus the test extends to evolution. (And yes, this also points tot he issue of the informational description of the universal constructor and self replication facility as the first threshold to be passed. Nor is this just a mind-game, the living cell is exactly this sort of thing, through perhaps not yet a full bore universal constructor. [Give us a couple of hundred years to figure that out and we will likely have nanobot swarms that will be just that!])
The inference at this point is obvious: by the utter dominance of non-functional configurations, 500 – 1,000 bits of information is a generous estimate of the upper limit for blind mechanisms to find functional forms.
This then extends directly into looking at the genome and to the string length of proteins as an index of find-ability, thence the evaluation of plausibility of origin of life and body plan level macro-evo models.
Origin of life by blind chance and/or mechanical necessity is utterly implausible. Minimal genomes are credibly 100 – 1,000 k bases, corresponding to about 100 times the size of the upper threshold.
Origin of major body plans, similarly, reasonably requires some 10 – 100+ mn new bases. We are now 10 – 100 thousand times the threshold.
Inference: the FSCO/I in first cell based life is there by design. Likewise that in novel body plans up to our own.
And, such is rooted in the informational context of such life.>>
___________
I think this allows us to further discuss. END
Comments
BA77 @ 31: You did an excellent job exposing the hypocrisy. Thank you.Truth Will Set You Free
January 7, 2017
January
01
Jan
7
07
2017
08:49 AM
8
08
49
AM
PDT
TA
You won’t change a deliberate rewording of someone else’s paper. OK.
Where I come from, that is called dishonest,
It's what's known as a marginal comment. KF explains.
But I think you know that already!Silver Asiatic
January 7, 2017
January
01
Jan
7
07
2017
08:16 AM
8
08
16
AM
PDT
kf, I'm not upset. I'm merely pointing out hypocrisy.
But don't worry. I will comment no further on your thread.bornagain77
January 7, 2017
January
01
Jan
7
07
2017
07:13 AM
7
07
13
AM
PDT
BA77, I think you need to take a little while to think and cool down a bit. KFkairosfocus
January 7, 2017
January
01
Jan
7
07
2017
07:06 AM
7
07
06
AM
PDT
kf, thanks for the advice, but I just as soon leave the bracketed quote as it is, and continue to cite it as such, just so as to upset timothya further.
My pleasures are simple! :)bornagain77
January 7, 2017
January
01
Jan
7
07
2017
07:00 AM
7
07
00
AM
PDT
timothya, perhaps you would like to write Zimmer, or the countless other Darwinists, who purposely misrepresent the overwhelming evidence for design by adding the unwarranted Darwinian narrative on top of the evidence?
Perhaps you should write Zimmer, as I did, informing him that he had dishonestly misrepresented current empirical evidence with his 'barely constrained randomness' remark?
Was not his article far more malicious in its dishonesty than my bracketed quip supposedly was?
If his article was not blatantly dishonest in its representation of current evidence, what is?
Or is it only when a well warranted quip of Design is added, in brackets, that you all of the sudden have a hyper-selective problem with 'dishonesty'?
Frankly, I find your feigned problem with my supposed dishonesty to be itself dishonest and disingenuous to the evidence at hand!
Moreover, I repeat, if you really think the inference to design was not warranted, i.e. 'was dishonest', then provide empirical evidence of happenstance processes producing such astonishing precision and complexity. Precision and complexity on the order of millions upon millions of interacting pieces performing such a well choreographed, even breath-taking, ballet.
To re-cite the article:
Proteins put up with the roar of the crowd – June 23, 2016
Excerpt: It gets mighty crowded around your DNA, but don’t worry: According to Rice University researchers, your proteins are nimble enough to find what they need.
Rice theoretical scientists studying the mechanisms of protein-DNA interactions in live cells showed that crowding in cells doesn’t hamper protein binding as much as they thought it did.,,,
If DNA can be likened to a library, it surely is a busy one. Molecules roam everywhere, floating in the cytoplasm and sticking to the tightly wound double helix. “People know that almost 90 percent of DNA is covered with proteins, such as polymerases, nucleosomes that compact two meters into one micron, and other protein molecules,” Kolomeisky said.,,,
That makes it seem that proteins sliding along the strand would have a tough time binding, and it’s possible they sometimes get blocked. But the Rice team’s theory and simulations indicated that crowding agents usually move just as rapidly, sprinting out of the way.
“If they move at the same speed, the molecules don’t bother each other,” Kolomeisky said. “Even if they’re covering a region, the blockers move away quickly so your protein can bind.”
In previous research, the team determined that stationary obstacles sometimes help quicken a protein’s search for its target by limiting options. This time, the researchers sought to define how crowding both along DNA and in the cytoplasm influenced the process.
“We may think everything’s fixed and frozen in cells, but it’s not,” Kolomeisky said. “Everything is moving.”,,,
Floating proteins appear to find their targets quickly as well. “This was a surprise,” he said. “It’s counterintuitive, because one would think collisions between a protein and other molecules on DNA would slow it down. But the system is so dynamic (and so well designed?), it doesn’t appear to be an issue.”
bornagain77
January 7, 2017
January
01
Jan
7
07
2017
06:42 AM
6
06
42
AM
PDT
F/N: Went over by TSZ to follow up Mung.
First article on page just now, by AF, leads: "There’s no question in my mind the “Intelligent Design” movement has lost all its arguments with Science."
1 --> For science read, a priori evolutionary materialism smuggled in through the back door of methodological naturalism. The self-referential incoherence of the first is disregarded, and the ideological question-begging imposed by the second comes out in the ill-advised triumphalism.
2 --> As for its focus, while I normally do not indulge debates over "climate change" I simply note from a comment I made earlier today to RVB8:
What is “climate,” apart from a 30 or so year moving average of weather day by day [so it necessarily must move and has been in general on a warming trend for the past some thousands of years, with dips such as the little ice age and bumps such as the medieval warming]?
And, what are the relevant forcings and cycles, and how well are they understood, starting with solar behaviour?
Also, given that weather is known to exhibit sensitive dependence on initial and intervening conditions with both positive and negative feedback factors at work, how well should we regard the various climate models in terms of their validation as ability to project decades and centuries in advance?
What about the recent trend plateau that extended for about 18+ years?
How much do we really know about climate, an observational science dependent on quality of long term trend observations and data proxies?
Should we not balance relevant dynamics such as the implications of crashing the global economy through energy starvation or imposing long term stagnation, which tends to foster major wars?
What about moving on despatchable potentially large scale energy sources such as molten salt thorium reactors and pebble bed modular reactors?
What of fusion and its potential?
(How do we deal with the plague of ever so many renewables, intermittency and fluctuations?)
What is your response to something like Marcin Jakubowski’s idea of a global village construction set?
What about solar system colonisation?
What about research?
In short, I am asking us to pause the rhetoric of polarisation and agenda pushing and rethink the whole energy- technology- economy- development- geopolitics- climate debate then have a responsible discussion.
Maybe, that will open up a way to think afresh instead of the stale — and, frankly, inexcusably hateful — rhetorical loading of phrases like” climate change DENIER,” deliberately echoing “Holocaust denier.”
3 --> I trust this may help open up some minds to think more broadly, more deeply and more reasonably.
I thought I would be able to readily find comments regarding the thermodynamics and search challenge issues above, but no luck.
KFkairosfocus
January 7, 2017
January
01
Jan
7
07
2017
06:15 AM
6
06
15
AM
PDT
TA, BA77 is not an academic, that is why I took the approach as just indicated. KFkairosfocus
January 7, 2017
January
01
Jan
7
07
2017
03:29 AM
3
03
29
AM
PDT
BA77, could I suggest putting each word in its own quote marks and perhaps with a phrase between: "counterintuitive" and "a surprise." We deal with hypercritics willing to pounce on anything to distract and distort so TA has a point. While UD is not a journal, we need to be very careful given the hostility we face and the general duty of care to truth and fairness. For comments,to make it clear that this is a marginal comment I suggest use square brackets and something like [--> BA77: abcdiary], or cutting the text and using blockquote to indent a similar comment if it is longer. And yes, I know there are those who object to having annotated snippets, too bad for them, just link the original or give enough source data that today's wonder tool search engines, can find it. What I would have done for that in days when I had to research and write as a student! KF
PS: Notice the high hits to comments ratio and absence of adverse critics here in this thread; though it seems they are swarming over at TSZ. That tells us something.kairosfocus
January 7, 2017
January
01
Jan
7
07
2017
03:28 AM
3
03
28
AM
PDT
You won't change a deliberate rewording of someone else's paper. OK.
Where I come from, that is called dishonest,timothya
January 7, 2017
January
01
Jan
7
07
2017
03:15 AM
3
03
15
AM
PDT
actually, there are 3 physorg papers in 16
If your objection is to my 'counterintuitive surprise' rewording, and my bracketed 'so well designed?" quip, well what can I say, I'm guilty as charged and I am not gonna change it:
me: finding a lack of ‘random collisions’ in a crowded cell was a ‘counterintuitive surprise’ for researchers in their paper:
paper: Floating proteins appear to find their targets quickly as well. “This was a surprise,” he said. “It’s counterintuitive, because one would think collisions between a protein and other molecules on DNA would slow it down. But the system is so dynamic (and so well designed?), it doesn’t appear to be an issue.”
If you object to my observation of it being well designed, perhaps you can provide an example of happenstance processes constructing interacting assemblies of over a billion pieces,, with formula1 racecar precision? Anyone not impressed with such amazing design needs to shut away for his own, and others, safety.bornagain77
January 7, 2017
January
01
Jan
7
07
2017
01:30 AM
1
01
30
AM
PDT
timothya, there are two physorg papers in 16, which one are you taking exception to? and What specifically are you objecting to?bornagain77
January 7, 2017
January
01
Jan
7
07
2017
01:08 AM
1
01
08
AM
PDT
BA77 - why did you alter the text of the phys.org paper that you referenced in comment 16?timothya
January 6, 2017
January
01
Jan
6
06
2017
09:21 PM
9
09
21
PM
PDT
Mung,
Sounds like they need to test their faith commitments against reality.
If you have a blind search for isolated islands of function, the scope of the config space is patently directly relevant. In this case, we are looking at a minimal genome of scope 100k - 1 mn base pairs.
2^100,000 ~ 9.99*10^30,102
(Let me add, there is a reason why there is a common metaphor about searching for needles in haystacks.)
The import of trying to suggest no it is not is that one of two things are happening: you are repeatedly being deposited on shores of function and/or there is a vast continent of functional forms accessible from a first form. The first is in effect repeated golden search, where as a search in a space is a subset, a space of scope n has a space of searches of order of the power set of scope 2^n. Golden searches are harder than direct searches.
As for the claim of an implied continent of incrementally accessible functional forms, that is an implication of the tree of life metaphor.
It has many problems, which begins with, show this in our observation in the face of for example the known deep isolation of many protein sequences in AA space, etc.
In general, we are talking of things that depend on multiple, well-matched, correctly arranged and coupled parts to achieve relevant configuration-specific functions.
This naturally sharply confines functional possibilities in the space of scattered vs clumped at random vs functional forms.
A simple way to put this, is to ask, is it plausible that there is a pathway of a few step changes each stage that has functional code all the way from a Hello world to an operating system?
On long experience, the underlying issue is gross extrapolation from incremental changes within an island of function -- micro-evo -- to origin of body plans. Multiplied by a consistent refusal to take seriously in this context the challenge of getting to the first functional from on the physics and chemistry of some Darwin's pond or the like.
The truth is, the best explanation for first cellular life is design, and design is present as a resource from the root up. Only by artificial exclusion is it possible to hold that there is no good evidence pointing to such design.
As I have said, DNA is text, complex text exhibiting codes and algorithms in the heart of the cell. text is LANGUAGE, as strong a sign of intelligence of at least human level as we want. That is the first thing to be explained, language without a speaker, alphabetic code without design, thus, a designer of such; algorithms without design and a a designer; execution machines similarly without design and thus a designer.
KFkairosfocus
January 6, 2017
January
01
Jan
6
06
2017
08:40 PM
8
08
40
PM
PDT
Over at TSZ they are trying to get a new meme going according to which the size of sequence space is irrelevant.
Wow. Just wow.Mung
January 6, 2017
January
01
Jan
6
06
2017
04:27 PM
4
04
27
PM
PDT
And it is also of interest to note that in quantum mechanics it is information that is primarily conserved, not necessarily matter and energy that are primarily conserved,,,
Quantum no-hiding theorem experimentally confirmed for first time - 2011
Excerpt: In the classical world, information can be copied and deleted at will. In the quantum world, however, the conservation of quantum information means that information cannot be created nor destroyed. This concept stems from two fundamental theorems of quantum mechanics: the no-cloning theorem and the no-deleting theorem. A third and related theorem, called the no-hiding theorem, addresses information loss in the quantum world. According to the no-hiding theorem, if information is missing from one system (which may happen when the system interacts with the environment), then the information is simply residing somewhere else in the Universe; in other words, the missing information cannot be hidden in the correlations between a system and its environment.
http://www.physorg.com/news/2011-03-quantum-no-hiding-theorem-experimentally.html
Quantum no-deleting theorem
Excerpt: A stronger version of the no-cloning theorem and the no-deleting theorem provide permanence to quantum information. To create a copy one must import the information from some part of the universe and to delete a state one needs to export it to another part of the universe where it will continue to exist.
http://en.wikipedia.org/wiki/Quantum_no-deleting_theorem#Consequence
As well, quantum entanglement/information is a non-local, beyond space and time, effect that refuses to be reduced to any conceivable matter-energy cause:
Looking beyond space and time to cope with quantum theory – 29 October 2012
Excerpt: “Our result gives weight to the idea that quantum correlations somehow arise from outside spacetime, in the sense that no story in space and time can describe them,”
http://www.quantumlah.org/highlight/121029_hidden_influences.php
Experimental test of nonlocal causality – August 10, 2016
DISCUSSION
Previous work on causal explanations beyond local hidden-variable models focused on testing Leggett’s crypto-nonlocality (7, 42, 43), a class of models with a very specific choice of hidden variable that is unrelated to Bell’s local causality (44). In contrast, we make no assumptions on the form of the hidden variable and test all models ,,,
Our results demonstrate that a causal influence from one measurement outcome to the other, which may be subluminal, superluminal, or even instantaneous, cannot explain the observed correlations.,,,
http://advances.sciencemag.org/content/2/8/e1600162.full
Besides providing direct empirical falsification of neo-Darwinian claims that say information is emergent from a material basis, the implication of finding 'non-local', beyond space and time, and ‘conserved’, quantum information in molecular biology on such a massive scale, in every DNA and protein molecule, is fairly, and pleasantly, obvious.
That pleasant implication, or course, being the fact that we now have strong physical evidence suggesting that we do indeed have an eternal soul that lives beyond the death of our material bodies.
“Let’s say the heart stops beating. The blood stops flowing. The microtubules lose their quantum state. But the quantum information, which is in the microtubules, isn’t destroyed. It can’t be destroyed. It just distributes and dissipates to the universe at large. If a patient is resuscitated, revived, this quantum information can go back into the microtubules and the patient says, “I had a near death experience. I saw a white light. I saw a tunnel. I saw my dead relatives.,,” Now if they’re not revived and the patient dies, then it's possible that this quantum information can exist outside the body. Perhaps indefinitely as a soul.”
- Stuart Hameroff - Quantum Entangled Consciousness - Life After Death - video (5:00 minute mark)
https://youtu.be/jjpEc98o_Oo?t=300
Verses:
John 1:1-4
In the beginning was the Word, and the Word was with God, and the Word was God. He was in the beginning with God. All things were made through Him, and without Him nothing was made that was made. In Him was life, and the life was the light of men.
Mark 8:37
“Is anything worth more than your soul?”
bornagain77
January 6, 2017
January
01
Jan
6
06
2017
07:58 AM
7
07
58
AM
PDT
As well, it is important to note that discrete digital information, such as that which is encoded in DNA, is found to be a subset of quantum information by the following:
Quantum knowledge cools computers: New understanding of entropy – June 2011
Excerpt: No heat, even a cooling effect;
In the case of perfect classical knowledge of a computer memory (zero entropy), deletion of the data requires in theory no energy at all. The researchers prove that “more than complete knowledge” from quantum entanglement with the memory (negative entropy) leads to deletion of the data being accompanied by removal of heat from the computer and its release as usable energy. This is the physical meaning of negative entropy. Renner emphasizes, however, “This doesn’t mean that we can develop a perpetual motion machine.” The data can only be deleted once, so there is no possibility to continue to generate energy. The process also destroys the entanglement, and it would take an input of energy to reset the system to its starting state. The equations are consistent with what’s known as the second law of thermodynamics: the idea that the entropy of the universe can never decrease. Vedral says “We’re working on the edge of the second law. If you go any further, you will break it.”
http://www.sciencedaily.com/releases/2011/06/110601134300.htm
Scientists show how to erase information without using energy - January 2011
Excerpt: Until now, scientists have thought that the process of erasing information requires energy. But a new study shows that, theoretically, information can be erased without using any energy at all.,,, "Landauer said that information is physical because it takes energy to erase it. We are saying that the reason it (information) is physical has a broader context than that.", Vaccaro explained.
http://www.physorg.com/news/2011-01-scientists-erase-energy.html
New Scientist astounds: Information is physical - May 13, 2016
Excerpt: Recently came the most startling demonstration yet: a tiny machine powered purely by information, which chilled metal through the power of its knowledge. This seemingly magical device could put us on the road to new, more efficient nanoscale machines, a better understanding of the workings of life, and a more complete picture of perhaps our most fundamental theory of the physical world.
https://uncommondescent.com/news/new-scientist-astounds-information-is-physical/
What is information? - animated video
“If information is not (physically) real then neither are we”
https://www.youtube.com/watch?v=2AvIOzVJMCM
Moreover, it is important to note that, in quantum mechanics, quantum information is its own distinct physical entity that is separate from matter and/or energy:
Quantum Entanglement and Information
Quantum entanglement is a physical resource, like energy, associated with the peculiar nonclassical correlations that are possible between separated quantum systems. Entanglement can be measured, transformed, and purified. A pair of quantum systems in an entangled state can be used as a quantum information channel to perform computational and cryptographic tasks that are impossible for classical systems. The general study of the information-processing capabilities of quantum systems is the subject of quantum information theory.
http://plato.stanford.edu/entries/qt-entangle/
Of related interest to quantum information being its own distinct physical entity that enables us to perform quantum computation, quantum computation provides a very viable mechanism that solves the outstanding problem of protein folding:
Physicists Discover Quantum Law of Protein Folding – February 22, 2011
Quantum mechanics finally explains why protein folding depends on temperature in such a strange way.
Excerpt: To put this in perspective, a relatively small protein of only 100 amino acids can take some 10^100 different configurations. If it tried these shapes at the rate of 100 billion a second, it would take longer than the age of the universe to find the correct one. Just how these molecules do the job in nanoseconds, nobody knows.,,,
Today, Luo and Lo say these curves can be easily explained if the process of folding is a quantum affair. By conventional thinking, a chain of amino acids can only change from one shape to another by mechanically passing though various shapes in between.
But Luo and Lo say that if this process were a quantum one, the shape could change by quantum transition, meaning that the protein could ‘jump’ from one shape to another without necessarily forming the shapes in between.,,,
Their astonishing result is that this quantum transition model fits the folding curves of 15 different proteins and even explains the difference in folding and unfolding rates of the same proteins.
That's a significant breakthrough. Luo and Lo's equations amount to the first universal laws of protein folding. That’s the equivalent in biology to something like the thermodynamic laws in physics.
http://www.technologyreview.com/view/423087/physicists-discover-quantum-law-of-protein/
bornagain77
January 6, 2017
January
01
Jan
6
06
2017
07:57 AM
7
07
57
AM
PDT
To further clarify my position:
That Darwinists have no real clue how life operates, thermodynamically, is revealed by the following quote:
"We have always underestimated cells. Undoubtedly we still do today. But at least we are no longer as naïve as we were when I was a graduate student in the 1960s. Then, most of us viewed cells as containing a giant set of second-order reactions: molecules A and B were thought to diffuse freely, randomly colliding with each other to produce molecule AB -- and likewise for the many other molecules that interact with each other inside a cell. This seemed reasonable because, as we had learned from studying physical chemistry, motions at the scale of molecules are incredibly rapid. Consider an enzyme, for example. If its substrate molecule is present at a concentration of 0.5mM,which is only one substrate molecule for every 105 water molecules, the enzyme's active site will randomly collide with about 500,000 molecules of substrate per second. And a typical globular protein will be spinning to and fro, turning about various axes at rates corresponding to a million rotations per second.
But, as it turns out, we can walk and we can talk because the chemistry that makes life possible is much more elaborate and sophisticated than anything we students had ever considered. Proteins make up most of the dry mass of a cell. But instead of a cell dominated by randomly colliding individual protein molecules, we now know that nearly every major process in a cell is carried out by assemblies of 10 or more protein molecules. And, as it carries out its biological functions, each of these protein assemblies interacts with several other large complexes of proteins. Indeed, the entire cell can be viewed as a factory that contains an elaborate network of interlocking assembly lines, each of which is composed of a set of large protein machines."
- Bruce Alberts, "The Cell as a Collection of Protein Machines: Preparing the Next Generation of Molecular Biologists," Cell, 92 (February 6, 1998): 291-294) Editor-in-Chief of Science (2009-2013). Dr Alberts served two six-year terms as the president of the National Academy of Sciences
That Darwinists, in spite of Alberts admission, still today think that life is dominated by 'randomly colliding' molecules is revealed by the following:
Years ago, William Dembski use to show the following video in his speaking engagements to clearly illustrate the Intelligent Design of the cell:
Inner Life of a Cell w William Dembski commentary – video
http://www.youtube.com/watch?v=jNs5kBE66Xo
The overwhelming impression of design literally leaps out of the video.
Dr. Wells relates, in this following article from 2014, how Darwinists, trying to counter the overwhelming impression of Design that the animation ‘Inner Life of the Cell’ had created on the web, tried, with a new animation entitled 'Protein Packing', to make the cell look as chaotic and random as possible,,
Flailing Blindly: The Pseudoscience of Josh Rosenau and Carl Zimmer – Jonathan Wells April 17, 2014
Excerpt: The new animation (like the old) also includes a kinesin molecule hauling a vesicle, but this time the kinesin’s movements are characterized (in Zimmer’s words) by
“barely constrained randomness. Every now and then, a tiny molecule loaded with fuel binds to one of the kinesin “feet.” It delivers a jolt of energy, causing that foot to leap off the molecular cable and flail wildly, pulling hard on the foot that’s still anchored. Eventually, the gyrating foot stumbles into contact again with the cable, locking on once more — and advancing the vesicle a tiny step forward. This updated movie offers a better way to picture our most intricate inner workings…. In the 2006 version, we can’t help seeing intention in the smooth movements of the molecules; it’s as if they’re trying to get from one place to another. In reality, however, the parts of our cells don’t operate with the precise movements of the springs and gears of a clock. They flail blindly in the crowd.”
But that’s not what the biological evidence shows. In fact, kinesin moves quickly, with precise movements, to get from one place to another,,,
http://www.evolutionnews.org/2014/04/flailing_blindl084521.html
This following video goes over that episode between Dembski, Wells, and Zimmer, as well the following video also reveals that the cell, as far as we can tell scientifically, is not anywhere near being 'barely constrained randomness' as leading Darwinists apparently still believe:
Molecular Biology - 19th Century Materialism meets 21st Century Quantum Mechanics - video
https://www.youtube.com/watch?v=rCs3WXHqOv8&index=3&list=PLtAP1KN7ahiYxgYCc-0xiUAhNWjT4q6LD
This following article came out right after I had put together the preceding video:
Specifically, finding a lack of 'random collisions' in a crowded cell was a 'counterintuitive surprise' for researchers in their paper:
Proteins put up with the roar of the crowd - June 23, 2016
Excerpt: It gets mighty crowded around your DNA, but don't worry: According to Rice University researchers, your proteins are nimble enough to find what they need.
Rice theoretical scientists studying the mechanisms of protein-DNA interactions in live cells showed that crowding in cells doesn't hamper protein binding as much as they thought it did.,,,
If DNA can be likened to a library, it surely is a busy one. Molecules roam everywhere, floating in the cytoplasm and sticking to the tightly wound double helix. "People know that almost 90 percent of DNA is covered with proteins, such as polymerases, nucleosomes that compact two meters into one micron, and other protein molecules," Kolomeisky said.,,,
That makes it seem that proteins sliding along the strand would have a tough time binding, and it's possible they sometimes get blocked. But the Rice team's theory and simulations indicated that crowding agents usually move just as rapidly, sprinting out of the way.
"If they move at the same speed, the molecules don't bother each other," Kolomeisky said. "Even if they're covering a region, the blockers move away quickly so your protein can bind."
In previous research, the team determined that stationary obstacles sometimes help quicken a protein's search for its target by limiting options. This time, the researchers sought to define how crowding both along DNA and in the cytoplasm influenced the process.
"We may think everything's fixed and frozen in cells, but it's not," Kolomeisky said. "Everything is moving.",,,
Floating proteins appear to find their targets quickly as well. "This was a surprise," he said. "It's counterintuitive, because one would think collisions between a protein and other molecules on DNA would slow it down. But the system is so dynamic (and so well designed?), it doesn't appear to be an issue."
http://phys.org/news/2016-06-proteins-roar-crowd.html
And along that line, at the 6:52 minute mark of the following video entitled 'Quantum Biology', Jim Al-Khalili states:
“To paraphrase, (Erwin Schrödinger in his book “What Is Life”), he says at the molecular level living organisms have a certain order. A structure to them that’s very different from the random thermodynamic jostling of atoms and molecules in inanimate matter of the same complexity. In fact, living matter seems to behave in its order and its structure just like inanimate cooled down to near absolute zero. Where quantum effects play a very important role. There is something special about the structure, about the order, inside a living cell. So Schrodinger speculated that maybe quantum mechanics plays a role in life”.
Jim Al-Khalili – Quantum biology – video
https://www.youtube.com/watch?v=zOzCkeTPR3Q
And to back up Jim Al-Khalili's claim that life has a certain order to it that acts like 'inanimate cooled down to near absolute zero', I reference the following paper in which the researchers are utterly puzzled that we are able to become consciously aware of a single photon when 'thermodynamic' noise should make such sensitivity impossible for a single photon:
Study suggests humans can detect even the smallest units of light – July 21, 2016
Excerpt: Research,, has shown that humans can detect the presence of a single photon, the smallest measurable unit of light. Previous studies had established that human subjects acclimated to the dark were capable only of reporting flashes of five to seven photons.,,,
it is remarkable: a photon, the smallest physical entity with quantum properties of which light consists, is interacting with a biological system consisting of billions of cells, all in a warm and wet environment,” says Vaziri. “The response that the photon generates survives all the way to the level of our awareness despite the ubiquitous background noise. Any man-made detector would need to be cooled and isolated from noise to behave the same way.”,,,
The gathered data from more than 30,000 trials demonstrated that humans can indeed detect a single photon incident on their eye with a probability significantly above chance.
“What we want to know next is how does a biological system achieve such sensitivity? How does it achieve this in the presence of noise?
http://phys.org/news/2016-07-humans-smallest.html
To further demonstrate that biology is dominated by quantum effects, as Schrödinger and Al-Khalili maintain, and is not dominated by 'the random thermodynamic jostling of atoms and molecules' as Darwinists maintain, it is now found that quantum information is ubiquitous throughout biology. Specifically, quantum information is found in proteins, in DNA, as well as in other molecules:
Quantum coherent-like state observed in a biological protein for the first time - October 13, 2015
Excerpt: If you take certain atoms and make them almost as cold as they possibly can be, the atoms will fuse into a collective low-energy quantum state called a Bose-Einstein condensate. In 1968 physicist Herbert Fröhlich predicted that a similar process at a much higher temperature could concentrate all of the vibrational energy in a biological protein into its lowest-frequency vibrational mode. Now scientists in Sweden and Germany have the first experimental evidence of such so-called Fröhlich condensation (in proteins).,,,
The real-world support for Fröhlich's theory (for proteins) took so long to obtain because of the technical challenges of the experiment, Katona said.
http://phys.org/news/2015-10-quantum-coherent-like-state-biological-protein.html
Classical and Quantum Information Channels in Protein Chain - Dj. Koruga, A. Tomi?, Z. Ratkaj, L. Matija - 2006
Abstract: Investigation of the properties of peptide plane in protein chain from both classical and quantum approach is presented. We calculated interatomic force constants for peptide plane and hydrogen bonds between peptide planes in protein chain. On the basis of force constants, displacements of each atom in peptide plane, and time of action we found that the value of the peptide plane action is close to the Planck constant. This indicates that peptide plane from the energy viewpoint possesses synergetic classical/quantum properties. Consideration of peptide planes in protein chain from information viewpoint also shows that protein chain possesses classical and quantum properties. So, it appears that protein chain behaves as a triple dual system: (1) structural - amino acids and peptide planes, (2) energy - classical and quantum state, and (3) information - classical and quantum coding. Based on experimental facts of protein chain, we proposed from the structure-energy-information viewpoint its synergetic code system.
http://www.scientific.net/MSF.518.491
"What happens is this classical information (of DNA) is embedded, sandwiched, into the quantum information (of DNA). And most likely this classical information is never accessed because it is inside all the quantum information. You can only access the quantum information or the electron clouds and the protons. So mathematically you can describe that as a quantum/classical state."
Elisabeth Rieper – Classical and Quantum Information in DNA – video (Longitudinal Quantum Information resides along the entire length of DNA discussed at the 19:30 minute mark; at 24:00 minute mark Dr Rieper remarks that practically the whole DNA molecule can be viewed as quantum information with classical information embedded within it)
https://youtu.be/2nqHOnVTxJE?t=1176
bornagain77
January 6, 2017
January
01
Jan
6
06
2017
07:56 AM
7
07
56
AM
PDT
BA77, yes, information is its own physical entity. Its presence in coded form also has some pretty serious implications. KFkairosfocus
kf????
My point is simple, "I hold that in order to fully explain life’s relationship with entropy it is necessary the recognize that (immaterial) information is it’s own distinct physical entity that is separate from matter and energy, (yet every bit as real, no pun intended)"bornagain77
January 6, 2017
January
01
Jan
6
06
2017
05:31 AM
5
05
31
AM
PDT
BA77, digital code is not self-executing. Its presence points to communication networks with parts in coherent co-ordination. It also implies codes, algorithms and languages; yes LANGUAGE and TEXT are embedded at the root of cell based life -- as strong a sign of intelligent design of a class at least comparable to humans as can be desired. All, requiring appropriate execution machinery that must be fit for purpose. And the information has to be preserved and used to correct errors to sustain life. KFkairosfocus
January 6, 2017
January
01
Jan
6
06
2017
04:49 AM
4
04
49
AM
PDT
Origines,
The temperature graph of a woman across her monthly cycle in the wiki article is apt illustration of how the set point moves over the cycle; the jump on days 14 - 18 corresponding to ovulation is dramatic. The effect of a day's sleeping-in is also seen.
Complex integrated biological feedback stabilising loops mark yet another manifestation of FSCO/I and likely of irreducibly complex systems too.
Where, just the tuning of such a loop is a case of fine tuning.
KFkairosfocus
January 6, 2017
January
01
Jan
6
06
2017
04:46 AM
4
04
46
AM
PDT
of note:
Although the recognition that a 'discrete digital code' is necessary to explain why life 'replicates with minimal information losses' and thus explain why life is able to 'act against the tendency of entropy to increase', in my honest opinion, the recognition that a 'discrete digital code' is necessary to explain life's ability to resist entropy does not go nearly far enough in explaining life's relationship with entropy.
I hold that in order to fully explain life's relationship with entropy it is necessary the recognize that information is it's own distinct physical entity that is separate from matter and energy, and to recognize that information is not merely to be defined as a particular arrangement of matter and energy. (December 2016)
https://uncommondescent.com/informatics/ud-guest-post-dr-eugen-s-on-the-second-law-of-thermodynamics-plus-vs-evolution/#comment-621625
A few notes on the physical reality of ‘immaterial’ information: (December. 2016)
Thermodynamic Content, Erasing Classical Information with Quantum Information, Quantum Teleportation
https://uncommondescent.com/intelligent-design/digg-what-is-information-a-remarkably-unstupid-vid/#comment-622155
Entropy, Information, and Christ's Resurrection from the dead – January 1, 2017
https://uncommondescent.com/philosophy/and-once-more-life-can-arise-naturally-from-chemistry/#comment-622928
bornagain77
January 6, 2017
January
01
Jan
6
06
2017
04:22 AM
4
04
22
AM
PDT
Kairosfocus: Homeostasis is a biggie …. Complex integrated feedback loops required to maintain life processes.
The organism not a statue and neither is homeostasis a rigid structure. During our lifetime, functional coherence must not only be continually maintained, it must be continually adjusted on many different levels. What is required for the homeostasis of the zygote is completely different from what is required for the homeostasis of the adult life form. Similarly, what is required for the homeostasis of a nerve cell differs from what is required for the homeostasis of a skin cell. And, given that one single cell can be said to be never the same during its lifetime, homeostasis must be constantly adjusted even wrt a single cell.
We are not talking about hitting a target once, but about hitting multiple moving targets zillion times in a row.Origenes
January 6, 2017
January
01
Jan
6
06
2017
03:49 AM
3
03
49
AM
PDT
O,
Homeostasis is a biggie, here is Wiki speaking against interest:
The metabolic processes of all living organisms can only take place in very specific physical and chemical environments. The conditions vary with each organism, and with whether the chemical processes take place inside the cell or in the fluids bathing the cells in multicellular creatures. The best known homeostats in human and other mammalian bodies are regulators that keep the composition of the extracellular fluids (or the ”internal environment”) constant, especially with regard to the temperature, pH, osmolality, and the concentrations of Na+, K+, Ca2+, glucose and CO2 and O2. However, a great many other homeostats, encompassing many aspects of human physiology, control other entities in the body.
Circadian variation in body temperature, ranging from about 37.5 °C from 10 a.m. to 6 p.m., and falling to about 36.4 °C from 2 a.m. to 6 a.m.
If an entity is homeostatically controlled it does not imply that its value is necessarily absolutely steady in health. Core body temperature is, for instance, regulated by a homeostat with temperature sensors in, amongst others, the hypothalamus of the brain.[9] However the set point of the regulator is regularly reset. For instance, core body temperature in humans varies during the course of the day (i.e. has a circadian rhythm), with the lowest temperatures occurring at night, and the highest in the afternoons (see diagram on the right). The temperature regulator's set point is also readjusted in adult women at the start of the luteal phase of the menstrual cycle (see the diagram on the right, below).[10][11] The temperature regulator's set point is also reset during infections to produce a fever.[9][12][13]
Homeostasis doesn't govern every activity in the body.[14][15] For instance the signal (be it via neurons or hormones) from the sensor to the effector is, of necessity, highly variable in order to convey information about the direction and magnitude of the error detected by the sensor.[16][17][18] Similarly the effector’s response needs to be highly adjustable to reverse the error – in fact it should be very nearly in proportion (but in the opposite direction) to the error that is threatening the internal environment.[7][8] For instance, the arterial blood pressure in mammals is homeostatically controlled, and measured by sensors in the aorta and carotid arteries. The sensors send messages via sensory nerves to the medulla oblongata of the brain indicating whether the blood pressure has fallen or risen, and by how much. The medulla oblongata then distributes messages along motor or efferent nerves belonging to the autonomic nervous system to a wide variety of effector organs, whose activity is consequently changed to reverse the error in the blood pressure. One of the effector organs is the heart whose rate is stimulated to rise (tachycardia) when the arterial blood pressure falls, or to slow down (bradycardia) when the pressure rises above set point. Thus the heart rate (for which there is no sensor in the body) is not homeostatically controlled, but is one of effector responses to errors in the arterial blood pressure. Another example is the rate of sweating. This is one of the effectors in the homeostatic control of body temperature, and therefore highly variable in rough proportion to the heat load that threatens to destabilize the body’s core temperature, for which there is a sensor in the hypothalamus of the brain.
Complex integrated feedback loops required to maintain life processes.
KFkairosfocus
January 5, 2017
January
01
Jan
5
05
2017
03:33 PM
3
03
33
PM
PDT
KF: Moreover, given that FSCO/I-rich micro-arrangements [FSCO/I = “functionally specific complex organisation and/or associated information”] are relatively rare in the set of possible arrangements, we can also see why it is hard to account for the origin of such states by spontaneous processes in the scope of the observable universe.
IMHO an even greater challenge for materialism lies in accounting for the continued existence of FSCO/I states in an organism. Given materialism, an organism, during its lifetime, is a sequence in time of countless improbable FSCO/I states. From a materialistic perspective there is no reason whatsoever for anything to continually “find” ensuing improbable states — a fluid shifting from one equilibrium to the next, despite the 2nd law.
IOWs the continued existence of an organism, the maintenance of functional coherence, is a formidable challenge for materialism.Origenes
January 5, 2017
January
01
Jan
5
05
2017
12:41 PM
12
12
41
PM
PDT
D, Diffusion is of course a fundamental molecular process, and it can be extended to many contexts. KFkairosfocus