One of the rhetorical gambits we are currently encountering is an attempt to drive a wedge between Dembski’s use of “Specified Complexity” and Orgel’s. Accordingly, I noted as below at 83 in VJT’s CSI thread:
_____________
>> I have always emphasised functionally specific complex organisation and associated information, FSCO/I, which is what is directly relevant to the world of life, and is pretty directly observable, starting with text and technology.
When objectors can bring themselves to acknowledge that observable phenomenon ant the linked constraint on possible configurations imposed by interactions required to produce functionality, then we can begin to analyse soundly.
Orgel actually spoke in the direct context of biofunction, and Wicken used the term, as well as identifying that wiring diagram organisation is informational.
[U/D, Dec 10:] It is worth clipping from Orgel, 1973 in an extended form:
>>. . . In brief, living organisms are distinguished by their specified complexity. Crystals are usually taken as the prototypes of simple well-specified structures, because they consist of a very large number of identical molecules packed together in a uniform way. Lumps of granite or random mixtures of polymers are examples of structures that are complex but not specified. The crystals fail to qualify as living because they lack complexity; the mixtures of polymers fail to qualify because they lack specificity . . . .
[HT, Mung, fr. p. 190 & 196:] These vague idea can be made more precise by introducing the idea of information. Roughly speaking, the information content of a structure is the minimum number of instructions needed to specify the structure. [–> this is of course equivalent to the string of yes/no questions required to specify the relevant “wiring diagram” for the set of functional states, T, in the much larger space of possible clumped or scattered configurations, W, as Dembski would go on to define in NFL in 2002, also cf here, here and here (with here on self-moved agents as designing causes).] One can see intuitively that many instructions are needed to specify a complex structure. [–> so if the q’s to be answered are Y/N, the chain length is an information measure that indicates complexity in bits . . . ] On the other hand a simple repeating structure can be specified in rather few instructions. [–> do once and repeat over and over in a loop . . . ] Complex but random structures, by definition, need hardly be specified at all . . . .
Paley was right to emphasize the need for special explanations of the existence of objects with high information content, for they cannot be formed in nonevolutionary, inorganic processes.
[The Origins of Life (John Wiley, 1973), p. 189, p. 190, p. 196. Of course, that immediately highlights OOL, where the required self-replicating entity is part of what has to be explained (cf. Paley here), a notorious conundrum for advocates of evolutionary materialism; one, that has led to mutual ruin documented by Shapiro and Orgel between metabolism first and genes first schools of thought, cf here. Behe would go on to point out that irreducibly complex structures are not credibly formed by incremental evolutionary processes and Menuge et al would bring up serious issues for the suggested exaptation alternative, cf. his challenges C1 – 5 in the just linked. Finally, Dembski highlights that CSI comes in deeply isolated islands T in much larger configuration spaces W, for biological systems functional islands. That puts up serious questions for origin of dozens of body plans reasonably requiring some 10 – 100+ mn bases of fresh genetic information to account for cell types, tissues, organs and multiple coherently integrated systems. Wicken’s remarks a few years later as already were cited now take on fuller force in light of the further points from Orgel at pp. 190 and 196 . . . ] >>
And from Wicken:
>>‘Organized’ systems are to be carefully distinguished from ‘ordered’ systems. Neither kind of system is ‘random,’ but whereas ordered systems are generated according to simple algorithms [[i.e. “simple” force laws acting on objects starting from arbitrary and common- place initial conditions] and therefore lack complexity, organized systems must be assembled element by element according to an [[originally . . . ] external‘wiring diagram’ with a high information content . . . Organization, then, is functional complexity and carries information. It is non-random by design or by selection, rather than by the a priori necessity of crystallographic ‘order.’[[“The Generation of Complexity in Evolution: A Thermodynamic and Information-Theoretical Discussion,” Journal of Theoretical Biology, 77 (April 1979): p. 353, of pp. 349-65. (Emphases and notes added. Nb: “originally” is added to highlight that for self-replicating systems, the blue print can be built-in.)] >>
Let’s use an outline view of a petroleum refinery to illustrate:

Now, compare a similarly outline view of cellular metabolism:
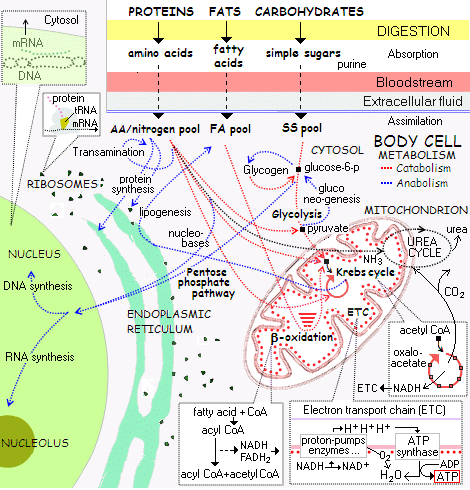
[U/D Dec 13:]The Abu 6500 C3 reel gives another example showing how functionally specific complex organisation and associated information comes out in a wiring diagram that can be viewed as allowing description of assembly instructions to achieve a functional entity from the field — configuration space — of possible clumped or scattered combinations of identified parts (notice, use of part numbers and a perspective like drawing to describe location and orientation, with connectors to indicate node-arc coupling to achieve function . . . ):
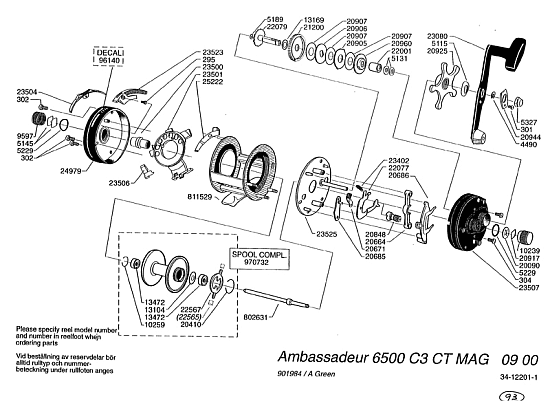
Yes, FSCO/I is real and observable, even measurable per a structured chain of Y/N q’s that specify location, orientation and coupling of parts to make, e.g. a functional reel. Which is tantamount to saying, we have a configuration description language, and can compose a program in it for putting together a functional reel, etc. The reasonably minimal length such description is a measure of the information content of the functionally specific organisation, in bits if all questions are Y/N.
Specified Complexity, in this wiring diagram context, is informational, and Dembski’s metric model is a superset based on abstracting specification to a generalised, independently and “simply” describable zone in a relevant configuration space, W.
Unfortunately, such is fairly abstract and mathematical, in an era where the abstract is often misunderstood, twisted into pretzels, despised, dismissed.
That is probably why GP has focussed down on a subset of FSCO/I, digitally coded, functionally specific coded information, dFSCI, such as we find in text, computer programs and D/RNA. As in, in action in the Ribosome to assemble proteins:
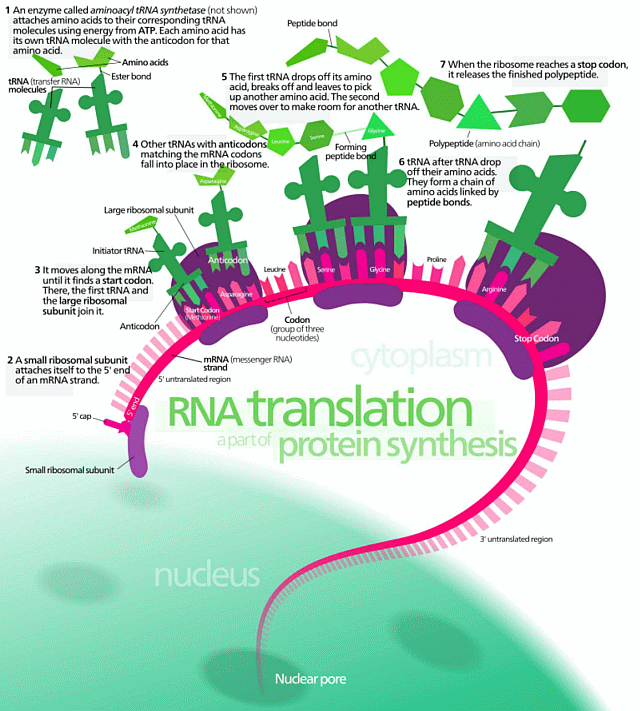
But even this is stoutly resisted.
I draw the conclusion that the problem is not CSI, or FSCO/I or dFSCI, but with where they point . . . which is where many will not go.
On long observation, some objectors have been willing to burn down self evident first principles of right reason and first, self-evident truths. Inductive conclusions and empirically grounded discussions will have no effect on such, until and unless — and here I have the Marxists in mind — their system crashes and burns.
As to the the definition of CSI begs the question assertion, I say, fallacious.
We have concrete cases, showing what CSI is about. The abstracted superset is reasonable in that context.
As for, it cannot be empirically tested, that is false.
Take the design inference process in hand — notice, how many objectors simply will not deal with design thought as it is, but persistently erect strawman caricatures — . . . and examine an aspect of an object or phenomenon. If it shows low contingency regularity under similar initial conditions, then the reasonable explanation is mechanical necessity acting by law.
Where there is high contingency under similar initial conditions, there are two known alternatives. As default, chance acting through stochastic contingency. As is well known from statistical studies, reasonable samples from a population of possibilities tend to reflect its bulk [the legitimate point behind the layman’s “law of averages”], but is unlikely to capture rare clusters such as the far-tails of a classic bell distribution. As samples scale up likelihood of picking up such rises.
Indeed, this is the basic point behind Fisher’s statistical testing and the 5% or 1% far tails. Likewise, statistical process control and manufacturing quality management. (And yes, I recall astonishing ding-dong rhetorical battles with objectors who found every hyperskeptical device to try to dismiss this commonplace. Sad.)
The design inference is linked to that point, as well as to the stat thermo-d concept of macroscopically identifiable clusters of microstates that are termed macrostates (and recall, that was the road I came to design theory from). The relative statistical weight of states tends to drive observability under reasonable chance driven contingency hyps. Indeed, that is the statistical underpinning of the second law of thermodynamics. But, again, I recall the ding-dong rhetorical battles when Professor Granville Sewell said the otherwise obvious thing that we do not expect to observe the stochastically utterly implausible when a system is opened up, save if something is crossing the boundary that makes it not implausible.
It seems to me there is a policy of zero concessions to IDiots, that reminds me uncomfortably of Plato’s warning on the implications of radical relativism and nihilism that so often flow from evolutionary materialist ideology, then and now: “hence arise factions.”
Sorry, but fair comment.
Now, there are things such as FSCO/I, which are highly contingent but are stochastically implausible. Moreover, on the evidence of trillions of actually observed cases, such consistently results from intelligently directed configuration. Where this post is adding another case in point.
So, on induction we are entitled to infer the best current explanation to be design. Not by begging questions or imposing circular definitions or the like, but by inductive reasoning. Where, “current” implues alternatives are considered, are classified and are addressed on the merits. And, that should future evidence say otherwise, the matter will be changed to reflect that.
As in, similar to Newton in Query 31 in Opticks, which is probably the root source on the Grade School “Scientific Method” summary we are often taught:
As in Mathematicks, so in Natural Philosophy, the Investigation of difficult Things by the Method of Analysis [–> inductive empirical analysis], ought ever to precede the Method of Composition. This Analysis consists in making Experiments and Observations, and in drawing general Conclusions from them by Induction, and admitting of no Objections against the Conclusions, but such as are taken from Experiments, or other certain Truths. For [–> speculative] Hypotheses are not to be regarded in experimental Philosophy. And although the arguing from Experiments and Observations by Induction be no Demonstration of general Conclusions; yet it is the best way of arguing which the Nature of Things admits of, and may be looked upon as so much the stronger, by how much the Induction is more general. And if no Exception occur from Phaenomena, the Conclusion may be pronounced generally. But if at any time afterwards any Exception shall occur from Experiments, it may then begin to be pronounced with such Exceptions as occur. By this way of Analysis we may proceed from Compounds to Ingredients, and from Motions to the Forces producing them; and in general, from Effects to their Causes, and from particular Causes to more general ones, till the Argument end in the most general. This is the Method of Analysis: And the Synthesis consists in assuming the Causes discover’d, and establish’d as Principles, and by them explaining the Phaenomena proceeding from them, and proving the Explanations
Yes, Sci Methods, 101.
Therefore, in looking at discussions as to how CSI is defined and the like, or how design inferences are made,
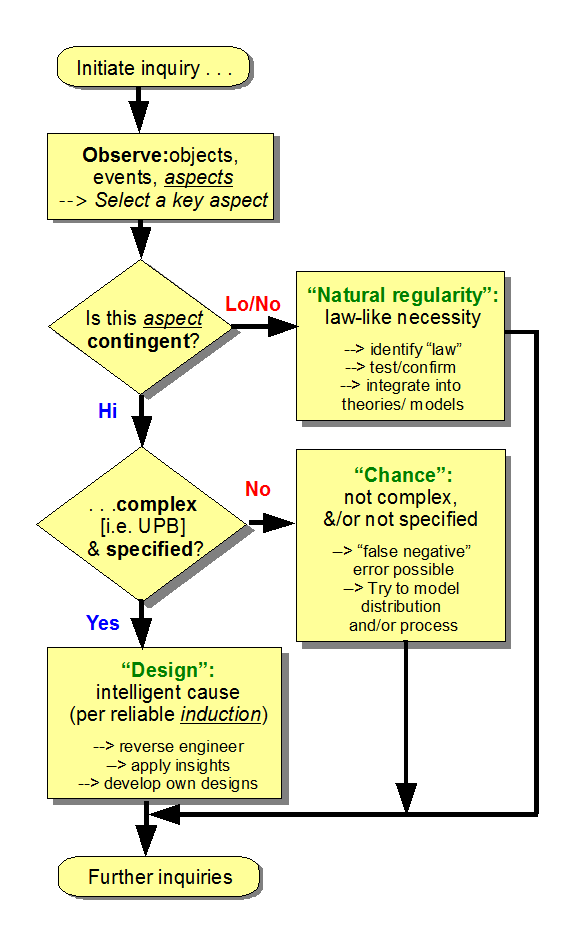
. . . that should be borne in mind. And, particularly, should FSCO/I be observed to reasonably reliably or just observably come from blind chance and mechanical necessity, then that would decisively undermine the design inference on FSCO/I.
Not, that that is plausibly likely to happen. We are talking here of sparse blind search for needles in very large haystacks. For 1,000 bits, the search potential of 10^80 atoms for 10^17 s at 10^14 searches of configs for 1,000 coins per second each, stands as one straw picked to a cubical haystack that would swallow up the 90 bn LY across observed cosmos.
Under these circumstances, we have reason only to expect to catch the bulk.
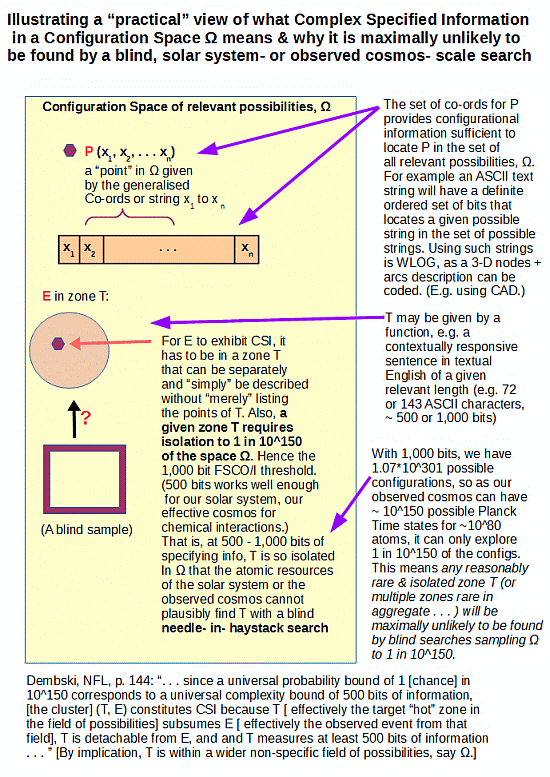
Now, perhaps the best thing is to start from Dembski’s actual definition of CSI in NFL, as I have cited, including in the infographic I have been repeatedly posting for months which obviously is being studiously ignored by too many objectors:
p. 148: “The great myth of contemporary evolutionary biology is that the information needed to explain complex biological structures can be purchased without intelligence. My aim throughout this book is to dispel that myth . . . . Eigen and his colleagues must have something else in mind besides information simpliciter when they describe the origin of information as the central problem of biology.
I submit that what they have in mind is specified complexity, or what equivalently we have been calling in this Chapter Complex Specified information or CSI . . . .
Biological specification always refers to function . . . In virtue of their function [[a living organism’s subsystems] embody patterns that are objectively given and can be identified independently of the systems that embody them. Hence these systems are specified in the sense required by the complexity-specificity criterion . . . the specification can be cashed out in any number of ways [[through observing the requisites of functional organisation within the cell, or in organs and tissues or at the level of the organism as a whole] . . .”
p. 144: [[Specified complexity can be defined:] “. . . since a universal probability bound of 1 [[chance] in 10^150 corresponds to a universal complexity bound of 500 bits of information, [[the cluster] (T, E) constitutes CSI because T [[ effectively the target hot zone in the field of possibilities] subsumes E [[ effectively the observed event from that field], T is detachable from E, and and T measures at least 500 bits of information . . . ”
That should be quite plain enough, and has been highlighted and brought to attention enough times across years that there is no excuse for twisting it into strawman caricatures.
He says, on the method of inferring design:
We know from experience that intelligent agents build intricate machines that need all their parts to function [[–> i.e. he is specifically discussing “irreducibly complex” objects, structures or processes for which there is a core group of parts all of which must be present and properly arranged for the entity to function; which is a subset of FSCO/I], things like mousetraps and motors. And we know how they do it — by looking to a future goal and then purposefully assembling a set of parts until they’re a working whole. Intelligent agents, in fact, are the one and only type of thing we have ever seen doing this sort of thing from scratch. In other words, our common experience provides positive evidence of only one kind of cause able to assemble such machines. It’s not electricity. It’s not magnetism. It’s not natural selection working on random variation. It’s not any purely mindless process. It’s intelligence . . . .
When we attribute intelligent design to complex biological machines that need all of their parts to work, we’re doing what historical scientists do generally. Think of it as a three-step process: (1) locate a type of cause active in the present that routinely produces the thing in question; (2) make a thorough search to determine if it is the only known cause of this type of thing; and (3) if it is, offer it as the best explanation for the thing in question.
[[William Dembski and Jonathan Witt, Intelligent Design Uncensored: An Easy-to-Understand Guide to the Controversy, pp. 20-21, 53 (InterVarsity Press, 2010). HT, CL of ENV & DI.]
Meyer, who was denigrated by an objector above, in replying to a critic of his Signature in the Cell, noted:
The central argument of my book is that intelligent design—the activity of a conscious and rational deliberative agent—best explains the origin of the information necessary to produce the first living cell. I argue this because of two things that we know from our uniform and repeated experience, which following Charles Darwin I take to be the basis of all scientific reasoning about the past. First, intelligent agents have demonstrated the capacity to produce large amounts of functionally specified information (especially in a digital form) [–> notice the terms he uses here]. Second, no undirected chemical process has demonstrated this power. Hence, intelligent design provides the best—most causally adequate—explanation for the origin of the information necessary to produce the first life from simpler non-living chemicals. In other words, intelligent design is the only explanation that cites a cause known to have the capacity to produce the key effect in question . . . . In order to [[scientifically refute this inductive conclusion] Falk would need to show that some undirected material cause has [[empirically] demonstrated the power to produce functional biological information apart from the guidance or activity a designing mind. Neither Falk, nor anyone working in origin-of-life biology, has succeeded in doing this . . . .
The central problem facing origin-of-life researchers is neither the synthesis of pre-biotic building blocks (which Sutherland’s work addresses) or even the synthesis of a self-replicating RNA molecule (the plausibility of which Joyce and Tracey’s work seeks to establish, albeit unsuccessfully . . . [[Meyer gives details . . . ]). Instead, the fundamental problem is getting the chemical building blocks to arrange themselves into the large information-bearing molecules (whether DNA or RNA) . . . .
For nearly sixty years origin-of-life researchers have attempted to use pre-biotic simulation experiments to find a plausible pathway by which life might have arisen from simpler non-living chemicals, thereby providing support for chemical evolutionary theory. While these experiments have occasionally yielded interesting insights about the conditions under which certain reactions will or won’t produce the various small molecule constituents of larger bio-macromolecules, they have shed no light on how the information in these larger macromolecules (particularly in DNA and RNA) could have arisen. Nor should this be surprising in light of what we have long known about the chemical structure of DNA and RNA. As I show in Signature in the Cell, the chemical structures of DNA and RNA allow them to store information precisely because chemical affinities between their smaller molecular subunits do not determine the specific arrangements of the bases in the DNA and RNA molecules. Instead, the same type of chemical bond (an N-glycosidic bond) forms between the backbone and each one of the four bases, allowing any one of the bases to attach at any site along the backbone, in turn allowing an innumerable variety of different sequences. This chemical indeterminacy is precisely what permits DNA and RNA to function as information carriers. It also dooms attempts to account for the origin of the information—the precise sequencing of the bases—in these molecules as the result of deterministic chemical interactions . . . .
[[W]e now have a wealth of experience showing that what I call specified or functional information(especially if encoded in digital form) does not arise from purely physical or chemical antecedents [[–> i.e. by blind, undirected forces of chance and necessity]. Indeed, the ribozyme engineering and pre-biotic simulation experiments that Professor Falk commends to my attention actually lend additional inductive support to this generalization. On the other hand, we do know of a cause—a type of cause—that has demonstrated the power to produce functionally-specified information. That cause is intelligence or conscious rational deliberation. As the pioneering information theorist Henry Quastler once observed, “the creation of information is habitually associated with conscious activity.” And, of course, he was right. Whenever we find information—whether embedded in a radio signal, carved in a stone monument, written in a book or etched on a magnetic disc—and we trace it back to its source, invariably we come to mind, not merely a material process. Thus, the discovery of functionally specified, digitally encoded information along the spine of DNA, provides compelling positive evidence of the activity of a prior designing intelligence. This conclusion is not based upon what we don’t know. It is based upon what we do know from our uniform experience about the cause and effect structure of the world—specifically, what we know about what does, and does not, have the power to produce large amounts of specified information . . . .
[[In conclusion,] it needs to be noted that the [[now commonly asserted and imposed limiting rule on scientific knowledge, the] principle of methodological naturalism [[ that scientific explanations may only infer to “natural[[istic] causes”] is an arbitrary philosophical assumption, not a principle that can be established or justified by scientific observation itself. Others of us, having long ago seen the pattern in pre-biotic simulation experiments, to say nothing of the clear testimony of thousands of years of human experience, have decided to move on. We see in the information-rich structure of life a clear indicator of intelligent activity and have begun to investigate living systems accordingly. If, by Professor Falk’s definition, that makes us philosophers rather than scientists, then so be it. But I suspect that the shoe is now, instead, firmly on the other foot. [[Meyer, Stephen C: Response to Darrel Falk’s Review of Signature in the Cell, SITC web site, 2009. (Emphases and parentheses added.)]
Such have long been on record and have repeatedly been brought to the attention of objectors. I find little to show those who have insisted on setting up and knocking over strawman caricatures in any positive light.>>
[U/D, Dec 10:] The idea-roots of the term “functionally specific complex organisation and associated information” [FSCO/I] are plain:
“Organization, then, is functional[[ly specific] complexity and carries information.“
And,
” living organisms are distinguished by their specified complexity . . . . Roughly speaking, the information content of a structure is the minimum number of instructions needed to specify the structure.“
Where, it is plain from Dembski’s point that in biological contexts, specification is cased out as function, that CSI is a superset of FSCO/I, indeed Orgel spoke of specified complexity and how a specifying description is an index of information content. Taking in Wicken’s wiring diagram concept and reckoning it in terms of a network of nodes and arcs, we can see that the chain length of a structured set of yes/no questions that identifies the configuration in the wiring diagram will be a basic information measure in bits.
This is exactly what AutoCAD and the like do.
Therefore, FSCO/I and CSI are organically connected to Orgel’s context of meaning when in 1973 he spoke of specified complexity.
The attempt to drive a wedge between Dembski’s complex specified information and Orgel’s specified complexity collapses.
______________
So, again. FSCO/I and CSI are reasonable discussions in light of the empirical fact. Dembski sought to create a metric model starting with analysing zones T in a possibility space W, and that model feeds into a log reduction and informational analysis. Where as information may be directly empirically investigated, that is reasonable. The bottomline being that the Wicken wiring diagram is informational and is amenable to a y/n q analysis of a nodes and arcs framework which quantifies the information involved at first level. Refinements can be made, but they are refinements. FTR again, so onward discussion is elsewhere. END