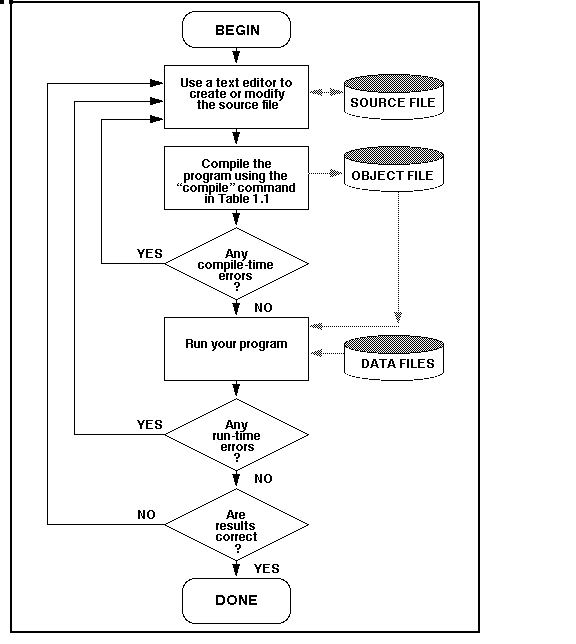
 As everyone knows, life in all its countless instances (organisms) involves internal instructions, as well as processors that run them. Without these instructions, no organism would be able to originate in the first place, let alone develop or survive. The discovery of these instructions – contained in DNA/RNA macromolecules and the molecular machinery that reads and writes them in biological cells – has been hailed as one of the greatest theoretical and experimental breakthroughs of the 20th century. The ID movement claims that these scientific findings have only served to highlight the weaknesses and inconsistencies of the neo-Darwinian theory of macro-evolution, according to which all species have evolved from a common ancestor, as a result of random mutation and natural selection.
As everyone knows, life in all its countless instances (organisms) involves internal instructions, as well as processors that run them. Without these instructions, no organism would be able to originate in the first place, let alone develop or survive. The discovery of these instructions – contained in DNA/RNA macromolecules and the molecular machinery that reads and writes them in biological cells – has been hailed as one of the greatest theoretical and experimental breakthroughs of the 20th century. The ID movement claims that these scientific findings have only served to highlight the weaknesses and inconsistencies of the neo-Darwinian theory of macro-evolution, according to which all species have evolved from a common ancestor, as a result of random mutation and natural selection.
The discovery of complex information processing in biology invites the question of whether there are any significant similarities between bio-informatics and the artificial informatics of computers, i.e. so-called computer science. Given that in both fields information has to be managed and processed, some similarities must of course exist. In this post, I will attempt to outline some conclusions on this topic, which lead us inexorably to the conclusion that Darwinian theory is incapable in principle of explaining the mystery of the origin of life and of species, as it claims to do.
When we consider the development of organisms and their complex internal organs and biological systems, we can easily see that these developmental sequences – and here I am talking about both ontogenetic and phylogenetic sequences – must involve complex programs, which embody decision logic about what has to be assembled, and also when and where it should be assembled. In other words, the right things need to be put in the right place at the right time, according to a precise schedule which is in some respects even more rigorous than schedules used in human engineering. For example, the development of an embryo is a process whose countless steps need to be choreographed in their most minute details by a program that is oriented towards the final result. Any error in the execution of this program may have severely deleterious consequences. The same thing can be said regarding the alleged macroevolution of new kinds of organs or even new body plans.
Given that biology and informatics both make use of programs, it will be necessary for me to say a few things about computer programming, in order to explain as clearly as possible exactly what a program is. I know that a lot of UD readers are software developers, so the points I will be making below will be very obvious to them. However, I’ll have to ask them to bear with me, as some of our readers are laypeople in these fields.
In order to process information – i.e. create software – it is necessary to create data and programs. Data is passive information: it cannot change or decide anything by itself. For example, let’s say I have a string variable (called $a) and I set it to contain the value “something” – or maybe I have a numeric variable $b which I set to contain the value 3.14. In these cases, I am neither specifying what should be done with the set values, nor when it should be done. Hence if I were to confine my work as a programmer to simply declaring the values of passive data, I would never be able to actively run a program or control any of its processes. Putting it another way: a program, in its simplest concept, is a blueprint specifying the reiteration of basic decision structures, about what to do and when to do it. A program must specify conditions and actions forming a control structure:
conditions (when to do it)
{
actions (what to do)
}
In other words, a program is active information. Since it determines conditions and actions, it has to be able to decide and organize things, and it also has to be able to create and change data. A program implies a decision hierarchy – in a word, a “logic”. It states what to do, when certain particular conditions arise. Once a program is designed, its execution by a processor can be used to control data and processes of any kind.
The simple structure described above can be repeated many times and can also be nested to create very complex structures with multiple nesting layers, such as the following example, with three nesting levels (the indentations and carriage returns have been inserted to help the reader understand the program flow, but are irrelevant per se at the level of machine code):
conditions
{
actions
conditions;
{actions;
conditions;
{actions;
conditions;
{actions;
}
}
}
}
Another important concept of programming is that of the sub-function or sub-routine:
function
{
…
}
The main program can reference and run a sub-function as follows:
conditions
{
actions
&function
}
where “&” is the symbol for referencing.
A sub-routine is a sub-program (or “child” program) of the parent program (usually called “main”) that invokes it, which can be referenced (i.e. used indirectly, thanks to a pointer that points to it). Two important things to note about sub-functions are that they work only if they exist somewhere within the software (a very obvious point) and that they are “called” by the main program. In other words, even if we have entire libraries of sub-functions, they will be useless if they are never called: they will be “dormant software”. Thus in a sense, dormant sub-functions constitute passive information. They are passive because they still require a caller that can run them. A sub-function which is never called does absolutely nothing.
From another point of view, programming can be defined as whatever implements control of a process. Since – as Michel Behe says – the fundamental problem of biochemistry and molecular biology (and, in the final analysis, of systems biology) is the problem of control, it follows that programming is indispensable in biology, where countless complex and concurrent processes are involved. Because multiple processes are running at the same time in biological systems – a property that scientists refer to as concurrency – there must be some higher level of direction that governs them all.
It should be noted that the conclusions obtained above hold quite independently of whether an organism’s biological instructions are completely contained within its genome, or only partially. There are many (and I would count myself among them) who suspect that the genome, by itself, does not contain enough information to account for the overall biological complexity of an organism. However one thing is certain: the assembly instructions of living beings must exist somewhere, and the science of generating instructions (computer science) can help us understand their organization and fabrication.
Modern evolutionary theory proposes several unguided mechanisms in order to explain the alleged global macroevolution of species from a single common ancestor: random genetic mutations, sexual genetic recombination, horizontal gene transfer, gene duplication, genetic drift, and so on. According to evolutionary theory, the output of all of these blind processes is subsequently processed (or filtered) by natural selection, which allows only the fittest to survive and reproduce. However, as we will see below, not one of these processes is capable of generating programs. Hence they are also incapable of creating new organs, new body plans, or even new species.
The concept of the gene is fundamental to evolutionary theory in particular, and to genetics and biology in general. Despite its importance, we are still a long way from a clear definition of what a gene is. From the old definition of “recipe for a protein” to the new definition of “functional unit of the genome,” the concept of gene has evolved to the point where some researchers now openly declare that “a gene is a unit of both structure and function, whose exact meaning and boundaries are defined by the scientist in relation to the experiment he or she is doing.” In practice, this means that a gene is whatever a particular scientist has in mind when he/she is doing a particular experiment.
The argument which I am putting forward here cuts through these definitional controversies, because from my informatics-based perspective there are really only two possibilities, which can be summarized as follows: either (a) genes are data (which corresponds to the above old definition of a gene); or (b) genes are functions (which corresponds to the new definition). The key point to understand here is that the development of new organs or body-plans (macroevolution) necessarily involves new decision logic, i.e. new hierarchies of nested control structures. Specifically, the architectural complexity (at the system level) of new organs or body-plans and their embryogenesis involves assembly instructions which require advanced-level control, and hence advanced programming.
Let’s suppose that the first option is correct, and that genes are data. In this case, it can easily be demonstrated that point random mutations, sexual recombination, horizontal gene transfer and data duplication are all incapable of creating the hierarchical decision logic of the main program. In fact, data is what the main program elaborates. Data is passive, while the program is active. What is passive cannot create what is active. This is just as true for intelligently designed data as it is for the data upon which the random operations of Darwinian evolution are applied.
We can illustrate this point from another perspective, by using the analogy of the bricks in a building. If genes are data containing only “recipes for proteins,” and proteins are the “bricks” of the organism “building,” then it is obvious that genes/bricks (and the random Darwinian operations performed upon them) cannot account for the construction and assembly of the organism/building – that is, the set of rules and instructions specifying the way in which the various bricks have to assemble together, in order to yield the unity of a complete system. The building construction metaphor also helps us understand why different organisms can have almost the same genetic patrimony. Just as the same bricks can be used to construct entirely different buildings, the same genes can be used to develop entirely different organisms. In other words, in both biology and architecture, what matters are not the basic building blocks, but rather the higher-level instructions which operate upon them.
Now let’s consider the second alternative, which is that genes are equivalent to software sub-functions. This is quite a generous assumption for evolutionists to make, because it implies that genes possess their own internal decision logic, without explaining how they acquired it. In reality, the so-called “regulatory regions” of genes probably don’t warrant being described as true algorithms. But even if genes were the equivalent of software functions, then once again, random mutations, sexual recombination, horizontal gene transfer and duplication of functions would still be incapable of creating hierarchical decision logic. Why not? Because the decision logic contained in the main program is what invokes the functions (by referencing them). Just as a hammer or a drill cannot create a carpenter, the above operations on functions are incapable of creating their user.
Let us note in passing that the classic evolutionist objection that a mutation involving only a few bits (or even a single bit) is capable of triggering major changes (evolutionists typically cite homeobox genes that control some configurations of the body plan, etc.) contains another misunderstanding. For the active information for these changes still has to exist somewhere, and it must be as large as the changes require it to be. It is true that a programmer can write a very short “wrapper program” to trigger large changes, but that doesn’t mean that the changes themselves require only a little information to specify. For example, I can write a short piece of code which I choose to run on my computer – say, a word processor or a chess program. This code is a few bits long, but the word processor and the chess program are really large programs. All the function does is point to or reference them. However, the function doesn’t create the active information contained in the word processor or chess program software; rather, it simply switches control between the two. Hence there is no free-lunch creation of information whatsoever here.
Leaving aside the problems associated with defining what a gene is, it can still be shown that the random processes which evolutionary theory claims are capable of generating biological complexity, simply don’t work. They don’t work because they are, by their very nature, incapable of generating the top-down functional hierarchy of nested decision structures that is responsible for making the whole system. Since this objection to the adequacy of random processes is an in-principle objection, it is useless for evolutionists to attempt to counter it by resorting to vast amounts of time or huge probabilistic resources. The fundamental problem of Darwinism is that the greater cannot come from the less.
To sum up: Darwinism, from an informatics point of view, has absolutely zero credibility. This explains, among other things, why so many computer programmers who are interested in the ID/evolution debate are on the ID side. In their own job they have never seen a single bit of software arise gratis. Rather they have to create, bit by bit, the active information of the software applications they develop. These people are justifiably perplexed when they encounter the evolutionist claim that God did not have to write a single line of code, because biological complexity (which is far greater than any computer software) arose naturalistically. “Why no work for Him and so much work for me?” they may ask. In this post, I hope I have helped explain that God, also in this case, expects far less from us than what He Himself did and does.