With headlines like “Caveman from 2m years ago may be missing link“, the world’s media made a field day of some recent work on Australopithecus sediba. For those with a memory, it has all happened previously in 2010. The announcement was made in the journal Science that the evolutionary path “From Australopithecus to Homo” had been found. Consequently, the media trumpeted the significance of the bones to their readers (see here). You had to read carefully to realize that hype and science were being confused. Move on to the present and the newly reported research: the journal Science carried three News Focus stories and five scientific papers on the fossils. This was picked up by the popular science journals (New Read More ›
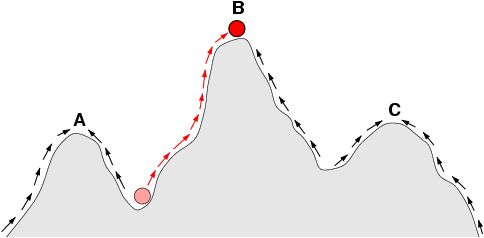
Ever since Dawkins’ Mt Improbable analogy, a common argument of design objectors has been that such complex designs as we see in life forms can “easily” be achieved incrementally, by steps within plausible reach of chance processes, that are then stamped in by success, i.e. by hill-climbing. Success, measured by reproductive advantage and what used to be called “survival of the fittest.”
[Added, Oct 15, given a distractive strawmannisation problem in the thread of discussion: NB: The wide context in view, plainly, is the Dawkins Mt Improbable type hill climbing, which is broader than but related to particular algorithms that bear that label.]
Weasel’s “cumulative selection” algorithm (c. 1986/7) was the classic — and deeply flawed, even outright misleading — illustration of Dawkinsian evolutionary hill-climbing.
To stir fresh thought and break out of the all too common stale and predictable exchanges over such algorithms, let’s put on the table a key remark by Stanley and Lehman, in promoting their particular spin on evolutionary algorithms, Novelty Search:
. . . evolutionary search is usually driven by measuring how close the current candidate solution is to the objective. [ –> Metrics include ratio, interval, ordinal and nominal scales; this being at least ordinal] That measure then determines whether the candidate is rewarded (i.e. whether it will have offspring) or discarded. [ –> i.e. if further moderate variation does not improve, you have now reached the local peak after hill-climbing . . . ] In contrast, novelty search [which they propose] never measures progress at all. Rather, it simply rewards those individuals that are different.
Instead of aiming for the objective, novelty search looks for novelty; surprisingly, sometimes not looking for the goal in this way leads to finding the goal [–> notice, an admission of goal- directedness . . . ] more quickly and consistently. While it may sound strange, in some problems ignoring the goal outperforms looking for it. The reason for this phenomenon is that sometimes the intermediate steps to the goal do not resemble the goal itself. John Stuart Mill termed this source of confusion the “like-causes-like” fallacy. In such situations, rewarding resemblance to the goal does not respect the intermediate steps that lead to the goal, often causing search to fail . . . .
Although it is effective for solving some deceptive problems, novelty search is not just another approach to solving problems. A more general inspiration for novelty search is to create a better abstraction of how natural evolution discovers complexity. An ambitious goal of such research is to find an algorithm that can create an “explosion” of interesting complexity reminiscent of that found in natural evolution.
While we often assume that complexity growth in natural evolution is mostly a consequence of selection pressure from adaptive competition (i.e. the pressure for an organism to be better than its peers), biologists have shown that sometimes selection pressure can in fact inhibit innovation in evolution. Perhaps complexity in nature is not the result of optimizing fitness, but instead a byproduct of evolution’s drive to discover novel ways of life.
While their own spin is not without its particular problems in promoting their own school of thought — there is an unquestioned matter of factness about evolution doing this that is but little warranted by actual observed empirical facts at body-plan origins level, and it is by no means a given that “evolution” will reward mere novelty — some pretty serious admissions against interest are made.
Anyway if they do rename the modern era after us, can’t we just tell the guys who say that humans are insignificant to go get themselves another beer and then sit at another table? Read More ›
The benefit of a tall stock with single ears of abundant kernels is evident forhumans (and incidentally agricultural pests), not to teosinte. Read More ›
"If it turns out that chaotic inflation is correct, then much of what we observe in nature will be due to the accident of our particular location ... " Read More ›
It has been brought to my attention that a previous entry of mine cited / linked to the wrong paper regarding the hybridization of twenty-one different chromosome-specific human alpha satellite DNA probes. This has now been corrected.
Reporter Parry, it must be charitably said, cannot imagine a world in which neuroscience is not dominated by celebrity poseurs, social engineers, and hucksters. Read More ›
The problem with Ridley's columns such as this weekend's is that he is under the illusion that he's giving us science when (as in this case) it's common or garden psychology dressed up in evolutionist terms. Read More ›
Dawkins is clearly a fading star in a world in which modern science, technology — and especially computational and information theory — have relegated him to the status of a vestigial remain of the 19th century. Richard Dawkins: Science doesn’t yet know how everything started. And as I said last time, they’re working on it. Dawkins’ logic and grammar are strangely confused. Science is not a person, and therefore doesn’t “know” anything. Of course, “they” are still “working on” how inanimate matter spontaneously generated complex information-processing software and hardware, just as the alchemists were “working on” how chemical reactions could turn lead into gold. The only problem is, lead can’t be turned into gold with chemical reactions; it doesn’t work Read More ›