Okay, the thread of discussion needs to pick up from here on.
To motivate discussion, let me clip here comment no 795 in the continuation thread, which I have marked up:
_________
>> 795Jerad October 23, 2012 at 1:18 am
KF (783):
At this point, with all due respect, you look like someone making stuff up to fit your predetermined conclusion.
I know you think so.
[a –> Jerad, I will pause to mark up. I would further with all due respect suggest that I have some warrant for my remark, especially given how glaringly you mishandled the design inference framework in your remark I responded to earlier.]
{Let me add a diagram of the per aspect explanatory filter, using the more elaborated form this time}
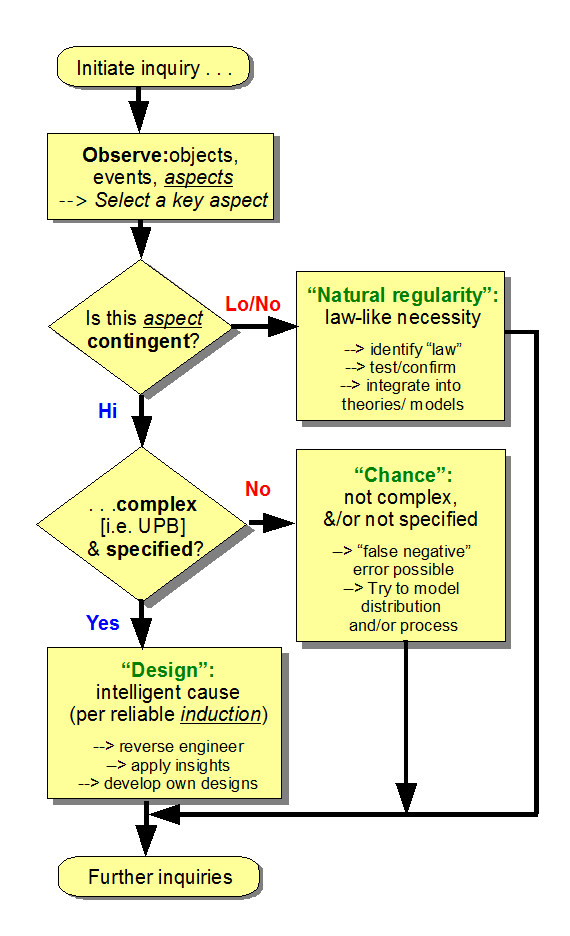
You have for sure seen the per apsect design filter and know that the first default explanaiton is that something is caused by law of necessity, for good reason; that is the bulk of the cosmos. You know similarly that highly contingent outcomes have two empirically warrantged causal sources: chance and choice.
You kinow full well that he reason chance is teh default is to give the plain benefit of the doubnt to chance, even at the expense of false negatives.
I suppose. Again, I don’t think of it like that. I take each case and consider it’s context before I think the most likely explanation to be.
[b –> You have already had adequate summary on how scientific investigations evaluate items we cannot directly observe based on traces and causal patterns and signs we can directly establish as reliable, and comparison. This is the exact procedure used in design inference, a pattern that famously traces to Newton’s uniformity principle of reasoning in science.]
I think SETI signals are a good example of really having no idea what’s being looked at.
[c –> There are no, zip, zilch, nada, SETI signals of consequence. And certainly no coded messages. But it is beyond dispute that if such a signal were received, it would be taken very seriously indeed. In the case of dFSCI, we are examining patterns relevant to coded signals. And, we have a highly relevant case in point in the living cell, which points to the origin of life. Which of course is an area that has been highlighted as pivotal on the whole issue of origins, but which is one where you have determined not to tread any more than you have to.]
I suppose, in that case, they do go through something like you’re steps . . . first thing: seeing if the new signals is similar to known and explained stuff.
[d –> If you take off materialist blinkers for the moment and look at what the design filter does, you will see that it is saying, what is it that we are doing in an empirically based, scientific explanation, and how does this relate to the empirical fact that design exists and affects the world leaving evident traces? We see that the first thing that is looked for is natural regularities, tracing to laws of mechanical necessity. Second — and my home discipline pioneered in this in C19 — we look at stochastically distributed patterns of behaviour that credibly trace to chance processes. Then it asks, what happens if we look for distinguishing characteristics of the other cause of high contingency, design? And in so doing, we see that there are indeed empirically reliable signs of design, which have considerable relevance to how we look at among other things, origins. But more broadly, it grounds the intuition that there are markers of design as opposed to chance.]
And you know the stringency of the criterion of specificity (especially functional) JOINED TO complexity beyond 500 or 1,000 bits worth, as a pivot to show cases where the only reasonable, empirically warranted explanation is design.
I still think you’re calling design too early.
[e –> Give a false positive, or show warrant for the dismissal. Remember, just on the solar system scope, we are talking about a result that identifies that by using the entire resources of the solar system for its typically estimated lifespan to date, we could only sample something like 1 straw to a cubical haystack 1,000 light years across. If you think that he sampling theory result that a small but significant random sample will typically capture the bulk of a distribution is unsound, kindly show us why, and how that affects sampling theory in light of the issue of fluctuations. Failing that, I have every epistemic right to suggest that what we are seeing instead is your a priori commitment to not infer design peeking through.]
And, to be honest, the only things I’ve seen the design community call design on is DNA and, in a very different way, the cosmos.
[f –> Not so. What happens is that design is most contentious on these, but in fact the design inference is used all the time in all sorts of fields, often on an intuitive or semi intuitive basis. As just one example, consider how fires are explained as arson vs accident. Similarly, how a particular effect in our bodies is explained as a signature of drug intervention vs chance behaviour or natural mechanism. And of course there is the whole world of hypothesis testing by examining whether we are in the bulk or the far skirt and whether it is reasonable to expect such on the particularities of the situation.]
The real problem, with all respect, as already highlighted is obviously that this filter will point out cell based life as designed. Which — even though you do not have an empirically well warranted causal explanation for otherwise, you do not wish to accept.
I don’t think you’ve made the case yet.
[f –> On the evidence it is plain that there is a controlling a priori commitment at work, so the case will never be perceived as made, as there will always be a selectively hyperskeptical objection that demands an increment of warrant that is calculated or by unreflective assertion, unreasonable to demand, by comparison with essentially similar situations. Notice, how ever so many swallow a timeline model of the past without batting an eye, but strain at a design inference that is much more empirically reliable on the causal patterns and signs that we have. That’s a case of straining at a gnat while swallowing a camel.]
I don’t think the design inference has been rigorously established as an objective measure.
[g –> Dismissive assertion, in a context where “rigorous’ is often a signature of selective hyperskepticism at work, cf, the above. The inference on algorithmic digital code that has been the subject of Nobel Prize awards should be plain enough.]
I think you’ve decided that only intelligence can create stuff like DNA.
[h –> Rubbish, and I do not appreciate your putting words in my mouth or thoughts in my head that do not belong there, to justify a turnabout assertion. You know or full well should know, that — as is true for any significant science — a single well documented case of FSCO/I reliably coming about by blind chance and/or mechanical necessity would suffice to break the empirical reliability of the inference that eh only observed — billions of cases — cause of FSCO/I is design. That you are objecting on projecting question-begging (that is exactly what your assertion means) instead of putting forth clear counter-examples, is strong evidence in itself that the observation is quite correct. That observation is backed by the needle in the haystack analysis that shows why beyond a certain level of complexity joined to the sort of specificity that makes relevant cases come from narrow zones T in large config spaces W, it is utterly unlikely to observe cases E from T based on blind chance and mechanical necessity.]
I haven’t seen any objective way to determine that except to say: it’s over so many bits long so it’s designed.
[i –> Strawman caricature. You know better, a lot better. You full well know that we are looking at complexity AND specificity that confines us to narrow zones T in wide spaces of possibilities W such that the atomic resources of our solar system or the observed cosmos will be swamped by the amount of haystack to be searched. Where you have been given the reasoning on sampling theory as to why we would only expect blind samples comparable to 1 straw to a hay bale 1,000 light years across (as thick as our galaxy) will reliably only pick up the bulk, even if the haystack were superposed on our galaxy near earth. Indeed, just above you had opportunity to see a concrete example of a text string in English and how easily it passes the specificity-complexity criterion.]
And I just don’t think that’s good enough.
[j –> Knocking over a strawman. Kindly, deal with the real issue that has been put to you over and over, in more than adequate details.]
But that inference is based on what we do know, the reliable cause of FSCO/I and the related needle in the haystack analysis. (As was just shown for a concrete case.)
But you don’t know that there was an intelligence around when one needed to be around which means you’re assuming a cause.
[k –> Really! You have repeatedly been advised that we are addressing inference on empirically reliable sign per patterns we investigate in the present. Surely, that we see that reliably, where there is a sign, we have confirmed the presence of the associated cause, is an empirical base of fact that shows something that is at least a good candidate for being a uniform pattern. We back it up with an analysis that shows on well accepted and uncontroversial statistical principles, why this is so. Then we look at cases where we see traces from the past that are comparable to the signs we just confirmed to be reliable indices. Such signs, to any reasonable person not ideologically committed to a contrary position, will count as evidence of similar causes acting in the past. But more tellingly, we can point to other cases such as the reconstructed timeline of the earth’s past where on much weaker correlations between effects and putative causes, those who object to the design inference make highly confident conclusions about the past and in so doing, even go so far as to present them as though they were indisputable facts. The inconsistency is glaringly obvious, save to the true believers in the evo mat scheme.]
And you’re not addressing all the evidence which points to universal common descent with modification.
[l –> I have started form the evidence at the root of the tree of life and find that there is no credible reason to infer that chemistry and physics in some still warm pond or the like will assemble at once or incre4mentally, a gated, encapsulated, metabolising entity using a von Neumann, code based self replicator, based on highly endothermic and information rich macromolecules. So, I see there is no root to the alleged tree of life, on Darwinist premises. I look at the dFSCI in the living cell, a trace form the past, note that it is a case of FSCO/I and on the pattern of causal investigations and inductions already outlined I see I have excellent reason to conclude that the living cell is a work of skilled ART, not blind chance and mechanical necessity. thereafter, ay evidence of common descent or the like is to be viewed in that pivotal light. And I find that common design rather than descent is superior, given the systematic pattern of — too often papered over — islands of molecular function (try protein fold domains) ranging up to suddenness, stasis and the scope of fresh FSCO/I involved in novel body plans and reflected in the 1/4 million plus fossil species, plus mosaic animals etc that point to libraries of reusable parts, and more, give me high confidence that I am seeing a pattern of common design rather than common descent. This is reinforced when I see that ideological a prioris are heavily involved in forcing the Darwinist blind watchmaker thesis model of the past.]
We’re going around in circles here.
[m –> On the contrary, what is coming out loud and clear is the ideological a priori that drives circularity in the evolutionary materialist reconstruction of the deep past of origins. KF]>>
___________
GP at 796, and following, is also a good pick-up point:
__________
>>796
-
gpuccioOctober 23, 2012 at 1:39 am
Joe:
If a string for which we have correctly assesses dFSCI is proved to have historically emerged without any design intervention, that would be a false positive. dFSCI has been correctly assessed, but it does not correspond empirically to a design origin.
It is important to remind that no such example is empirically known. That’s why we say that dFSCI has 100% specificity as an indicator of design.
If a few examples of that kind were found, the specificity of the tool would be lower. We could still keep some use for it, but I admit that its relevance for a design inference in such a fundamental issue like the interpretation of biological information woudl be heavily compromised.
-
797
If you received an electromagnetic burst from space that occurred at precisely equal intervals and kept to sidereal time would that be a candidate for SCI?
-
798
Are homing beacons SCI?
-
Jerad:
As you should know, the first default is look for mechanical necessity. The neutron star model of pulsars suffices to explain what we see.
Homing beacons come in networks — I here look at DECCA, LORAN and the like up to today’s GPS, and are highly complex nodes. They are parts of communication networks with highly complex and functionally specific communication systems. Where encoders, modulators, transmitters, receivers, demodulators and decoders have to be precisely and exactly matched.
Just take an antenna tower if you don’t want to look at anything more complex.
KF>>
__________
I am fairly sure that this discussion, now in excess of 1,500 comments, lets us all see what is really going on in the debate over the design inference. END