In the still active discussion thread on failure of compensation arguments, long term maverick ID (and, I think, still YEC-sympathetic) supporter SalC comments:
SalC, 570: . . . I’ve argued against using information theory type arguments in defense of ID, it adds way too much confusion. Basic probability will do the job, and basic probability is clear and unassailable.
The mutliplicities of interest to ID proponents don’t vary with temperature, whereas the multiplicities from a thermodynamic perspective change with temperature. I find that very problematic for invoking 2LOT in defense of ID.
Algorithmically controlled metabolisms (such as realized in life) are low multiplicity constructs as a matter of principle. They are high in information content. But why add more jargon and terminology?
Most people understand “complex-computer-like machines such a living creatures are far from the expected outcome of random processes”. This is a subtle assertion of LLN [ –> The Law of Large Numbers in Statistics]. This is a different way of posing the Humpty Dumpty problem.
There are an infinite number of ways to make lock-and-key or login/password systems, but just because there are infinite number of ways to do this does not make them highly probable from random processes . . . . Why invoke 2LOT? Why invoke fancy terms that add confusion? One deliberately uses unclear arguments when one wishes to obfuscate, but why be unclear when evidence is on one’s side? . . . .
LLN and variations of Jonathan Wells Humpty Dumpty argument I think have proven themselves in the arena of debate. Maybe even more tersely, extrapolating Pasteur, “life does not come from non-life.”
In response, while SalC has a point where a basic and non-controversial exchange is in hand, we usually do not have this luxury and must address the technical issues to some significant extent. When we do so all of the above factors at once come out as differing facets of the same issue.
Facets, that inextricably interact as parts of a whole.
In short, once we begin to probe beneath the surface, design thought shows itself to be . . . irreducibly complex.
Accordingly, I responded as follows at 592 , which I think I should headline and augment:
_______________
KF, 592: >>Pardon, but I have a different take: on years of observing, any serious design argument will be twisted into pretzels, strawmannised, confused, clouded and generally distorted and dismissed by the sort of ruthlessly determined and too often amoral or outright nihilistic, truth and fairness disregarding objectors we frequently face.
This is because, too many such are “any means necessary”/”ends justify means” committed ideologues full of agit-prop talking points and agendas.
That’s exactly how the trained, indoctrinated Marxist agitators of my youth operated. Benumbed in conscience, insensitive to truth, fundamentally rage-blinded [even when charming], secure in their notion that they were the vanguard of the future/progress, and that they were championing pure victims of the oppressor classes who deserved anything they got.
(Just to illustrate the attitude, I remember one who accused me falsely of theft of an item of equipment kept in my lab. I promptly had it signed over to the Student Union once I understood the situation, then went to her office and confronted her with the sign off. How can you be so thin skinned was her only response; taking full advantage of the rule that men must restrain themselves in dealing with women, however outrageous the latter, and of course seeking to further wound. Ironically, this champion of the working classes was from a much higher class-origin than I was . . . actually, unsurprisingly. To see the parallels, notice how often not only objectors who come here but the major materialist agit-prop organisations — without good grounds — insinuate calculated dishonesty and utter incompetence to the point that we should not have been able to complete a degree, on our part.)
I suggest, first, that the pivot of design discussions on the world of life is functionally specific, complex interactive Wicken wiring diagram organisation of parts that achieve a whole performance based on particular arrangement and coupling, and associated information. Information that is sometimes explicit (R/DNA codes) or sometimes may be drawn out by using structured Y/N q’s that describe the wiring pattern to achieve function.
FSCO/I, for short.
{Aug. 1:} Back to Reels to show the basic “please face and acknowledge facts” reality of FSCO/I , here the Penn International Trolling Reel exploded view:
. . . and a video showing the implications of this “wiring diagram” for how it is put together in the factory:
. . . just, remember, the arm-hand system is a complex, multi-axis cybernetic manipulator-arm:
This concept is not new, it goes back to Orgel 1973:
. . . In brief, living organisms [–> functional context] are distinguished by their specified complexity. Crystals are usually taken as the prototypes of simple well-specified structures, because they consist of a very large number of identical molecules packed together in a uniform way. Lumps of granite or random mixtures of polymers are examples of structures that are complex but not specified. The crystals fail to qualify as living because they lack complexity; the mixtures of polymers fail to qualify because they lack specificity . . . .
[HT, Mung, fr. p. 190 & 196:] These vague idea can be made more precise by introducing the idea of information. Roughly speaking, the information content of a structure is the minimum number of instructions needed to specify the structure. [–> this is of course equivalent to the string of yes/no questions required to specify the relevant “wiring diagram” for the set of functional states, T, in the much larger space of possible clumped or scattered configurations, W, as Dembski would go on to define in NFL in 2002 . . . ] One can see intuitively that many instructions are needed to specify a complex structure. [–> so if the q’s to be answered are Y/N, the chain length is an information measure that indicates complexity in bits . . . ] On the other hand a simple repeating structure can be specified in rather few instructions. [–> do once and repeat over and over in a loop . . . ] Complex but random structures, by definition, need hardly be specified at all . . . . Paley was right to emphasize the need for special explanations of the existence of objects with high information content, for they cannot be formed in nonevolutionary, inorganic processes. [The Origins of Life (John Wiley, 1973), p. 189, p. 190, p. 196.]
. . . as well as Wicken, 1979:
‘Organized’ systems are to be carefully distinguished from ‘ordered’ systems. Neither kind of system is ‘random,’ but whereas ordered systems are generated according to simple algorithms [[i.e. “simple” force laws acting on objects starting from arbitrary and common- place initial conditions] and therefore lack complexity, organized systems must be assembled element by element according to an [[originally . . . ] external ‘wiring diagram’ with a high information content . . . Organization, then, is functional complexity and carries information. It is non-random by design or by selection, rather than by the a priori necessity of crystallographic ‘order.’ [[“The Generation of Complexity in Evolution: A Thermodynamic and Information-Theoretical Discussion,” Journal of Theoretical Biology, 77 (April 1979): p. 353, of pp. 349-65. (Emphases and notes added. Nb: “originally” is added to highlight that for self-replicating systems, the blue print can be built-in.)]
. . . and is pretty directly stated by Dembski in NFL:
p. 148:“The great myth of contemporary evolutionary biology is that the information needed to explain complex biological structures can be purchased without intelligence. My aim throughout this book is to dispel that myth . . . . Eigen and his colleagues must have something else in mind besides information simpliciter when they describe the origin of information as the central problem of biology.
I submit that what they have in mind is specified complexity, or what equivalently we have been calling in this Chapter Complex Specified information or CSI . . . .
Biological specification always refers to function. An organism is a functional system comprising many functional subsystems. . . . In virtue of their function [[a living organism’s subsystems] embody patterns that are objectively given and can be identified independently of the systems that embody them. Hence these systems are specified in the sense required by the complexity-specificity criterion . . . the specification can be cashed out in any number of ways [[through observing the requisites of functional organisation within the cell, or in organs and tissues or at the level of the organism as a whole. Dembski cites:
Wouters, p. 148: “globally in terms of the viability of whole organisms,”
Behe, p. 148: “minimal function of biochemical systems,”
Dawkins, pp. 148 – 9: “Complicated things have some quality, specifiable in advance, that is highly unlikely to have been acquired by ran-| dom chance alone. In the case of living things, the quality that is specified in advance is . . . the ability to propagate genes in reproduction.”
On p. 149, he roughly cites Orgel’s famous remark from 1973, which exactly cited reads:
In brief, living organisms are distinguished by their specified complexity. Crystals are usually taken as the prototypes of simple well-specified structures, because they consist of a very large number of identical molecules packed together in a uniform way. Lumps of granite or random mixtures of polymers are examples of structures that are complex but not specified. The crystals fail to qualify as living because they lack complexity; the mixtures of polymers fail to qualify because they lack specificity . . .
And, p. 149, he highlights Paul Davis in The Fifth Miracle: “Living organisms are mysterious not for their complexity per se, but for their tightly specified complexity.”] . . .”
p. 144: [[Specified complexity can be more formally defined:] “. . . since a universal probability bound of 1 [[chance] in 10^150 corresponds to a universal complexity bound of 500 bits of information, [[the cluster] (T, E) constitutes CSI because T [[ effectively the target hot zone in the field of possibilities] subsumes E [[ effectively the observed event from that field], T is detachable from E, and and T measures at least 500 bits of information . . . ”
What happens at relevant cellular level, is that this comes down to highly endothermic C-Chemistry, aqueous medium context macromolecules in complexes that are organised to achieve highly integrated and specific interlocking functions required for metabolising, self replicating cells to function.
This implicates huge quantities of information manifest in the highly specific functional organisation. Which is observable on a much coarser resolution than the nm range of basic molecular interactions. That is we see tightly constrained clusters of micro-level arrangements — states — consistent with function, as opposed to the much larger numbers of possible but overwhelmingly non-functional ways the same atoms and monomer components could be chemically and/or physically clumped “at random.” In turn, that is a lot fewer ways than the same could be scattered across a Darwin’s pond or the like.
{Aug. 2} For illustration let us consider the protein synthesis process at gross level:
. . . spotlighting and comparing the ribosome in action as a coded tape Numerically Controlled machine:
. . . then at a little more zoomed in level:
Protein Synthesis (HT: Wiki Media)
. . . then in the wider context of cellular metabolism [protein synthesis is the little bit with two call-outs in the top left of the infographic]:
Thus, starting from the “typical” diffused condition, we readily see how a work to clump at random emerges, and a further work to configure in functionally specific ways.
With implications for this component of entropy change.
As well as for the direction of the clumping and assembly process to get the right parts together, organised in the right cluster of ways that are consistent with function.
Thus, there are implications of prescriptive information that specifies the relevant wiring diagram. (Think, AutoCAD etc as a comparison.)
Pulling back, we can see that to achieve such, the reasonable — and empirically warranted — expectation, is
a: to find energy, mass and information sources and flows associated with
b: energy converters that provide shaft work or controlled flows [I use a heat engine here but energy converters are more general than that], linked to
c: constructors that carry out the particular work, under control of
d: relevant prescriptive information that explicitly or implicitly regulates assembly to match the wiring diagram requisites of function,
A von Neumann kinematic self-replicator
. . . [u/d Apr 13] or, comparing an contrasting a Maxwell Demon model that imposes organisation by choice with use of mechanisms, courtesy Abel:
. . . also with
e: exhaust or dissipation otherwise of degraded energy [typically, but not only, as heat . . . ] and discarding of wastes. (Which last gives relevant compensation where dS cosmos rises. Here, we may note SalC’s own recent cite on that law from Clausius, at 570 in the previous thread that shows what “relevant” implies: Heat can never pass from a colder to a warmer body without some other change, connected therewith, occurring at the same time.)
{Added, April 19, 2015: Clausius’ statement:}
By contrast with such, there seems to be a strong belief that irrelevant mass and/or energy flows without coupled converters, constructors and prescriptive organising information, through phenomena such as diffusion and fluctuations can somehow credibly hit on a replicating entity that then can ratchet up into a full encapsulated, gated, metabolising, algorithmic code using self replicating cell.
Such is thermodynamically — yes, thermodynamically, informationally and probabilistically [loose sense] utterly implausible. And, the sort of implied genes first/RNA world, or alternatively metabolism first scenarios that have been suggested are without foundation in empirically observed adequate cause tracing only to blind chance and mechanical necessity.
{U/D, Apr 13:} Abel 2012 makes much the same point, in his book chapter, MOVING ‘FAR FROM EQUILIBRIUM’ IN A PREBIOTIC ENVIRONMENT: The role of Maxwell’s Demon in life origin :
Mere heterogeneity and/or order do not even begin to satisfy the necessary and sufficient conditions for life. Self-ordering tendencies provide no mechanism for self-organization, let alone abiogenesis. All sorts of physical astronomical “clumping,” weak-bonded molecular alignments, phase changes, and outright chemical reactions occur spontaneously in nature that have nothing to do with life. Life is organization-based, not order-based. As we shall see below in Section 6, order is poisonous to organization.
Stochastic ensembles of nucleotides and amino acids can polymerize naturalistically (with great difficulty). But functional sequencing of those monomers cannot be determined by any fixed physicodynamic law. It is well-known that only one 150-mer polyamino acid string out of 10^74 stochastic ensembles folds into a tertiary structure with any hint of protein function (Axe, 2004). This takes into full consideration the much publicized substitutability of amino acids without loss of function within a typical protein family membership. The odds are still only one functional protein out of 10^74 stochastic ensembles. And 150 residues are of minimal length to qualify for protein status. Worse yet, spontaneously condensed Levo-only peptides with peptide-only bonds between only biologically useful amino acids in a prebioitic environment would rarely exceed a dozen mers in length. Without polycodon prescription and sophisticated ribosome machinery, not even polypeptides form that would contribute much to “useful biological work.” . . . .
There are other reasons why merely “moving far from equilibrium” is not the key to life as seems so universally supposed. Disequilibrium stemming from mere physicodynamic constraints and self-ordering phenomena would actually be poisonous to life-origin (Abel, 2009b). The price of such constrained and self-ordering tendencies in nature is the severe reduction of Shannon informational uncertainty in any physical medium (Abel, 2008b, 2010a). Self-ordering processes preclude information generation because they force conformity and reduce freedom of selection. If information needs anything, it is the uncertainty made possible by freedom from determinism at true decisions nodes and logic gates. Configurable switch-settings must be physicodynamically inert (Rocha, 2001; Rocha & Hordijk, 2005) for genetic programming and evolution of the symbol system to take place (Pattee, 1995a, 1995b). This is the main reason that Maxwell’s Demon model must use ideal gas molecules. It is the only way to maintain high uncertainty and freedom from low informational physicochemical determinism. Only then is the control and regulation so desperately needed for organization and life-origin possible. The higher the combinatorial possibilities and epistemological uncertainty of any physical medium, the greater is the information recordation potential of that matrix.
Constraints and law-like behavior only reduce uncertainty (bit content) of any physical matrix. Any self-ordering tendency precludes the freedom from law needed to program logic gates and configurable switch settings. The regulation of life requires not only true decision nodes, but wise choices at each decision node. This is exactly what Maxwell’s Demon does. No yet-to-be discovered physicodynamic law will ever be able to replace the Demon’s wise choices, or explain the exquisite linear digital PI programming and organization of life (Abel, 2009a; Abel & Trevors, 2007). Organization requires choice contingency rather than chance contingency or law (Abel, 2008b, 2009b, 2010a). This conclusion comes via deductive logical necessity and clear-cut category differences, not just from best-thus-far empiricism or induction/abduction.
In short, the three perspectives converge. Thermodynamically, the implausibility of finding information rich FSCO/I in islands of function in vast config spaces . . .
. . . — where we can picture the search by using coins as stand-in for one-bit registers —
. . . links directly to the overwhelmingly likely outcome of spontaneous processes. Such is of course a probabilistically liked outcome. And, information is often quantified on the same probability thinking.
Taking a step back to App A my always linked note, following Thaxton Bradley and Olson in TMLO 1984 and amplifying a bit:
. . . Going forward to the discussion in Ch 8, in light of the definition dG = dH – Tds, we may then split up the TdS term into contributing components, thusly:
First, dG = [dE + PdV] – TdS . . . [Eqn A.9, cf def’ns for G, H above]
But, [1] since pressure-volume work [–> the PdV term] may be seen as negligible in the context we have in mind, and [2] since we may look at dE as shifts in bonding energy [which will be more or less the same in DNA or polypeptide/protein chains of the same length regardless of the sequence of the monomers], we may focus on the TdS term. This brings us back to the clumping then configuring sequence of changes in entropy in the Micro-Jets example above:
Of course, we have already addressed the reduction in entropy on clumping and the further reduction in entropy on configuration, through the thought expt. etc., above. In the DNA or protein formation case, more or less the same thing happens. Using Brillouin’s negentropy formulation of information, we may see that the dSconfig is the negative of the information content of the molecule.
A bit of back-tracking will help:
S = k ln W . . . Eqn A.3
{U/D Apr 19: Boltzmann’s tombstone}
Now, W may be seen as a composite of the ways energy as well as mass may be arranged at micro-level. That is, we are marking a distinction between the entropy component due to ways energy [here usually, thermal energy] may be arranged, and that due to the ways mass may be configured across the relevant volume. The configurational component arises from in effect the same considerations as lead us to see a rise in entropy on having a body of gas at first confined to part of an apparatus, then allowing it to freely expand into the full volume:
Free expansion:
|| * * * * * * * * | . . . . . ||
Then:
|| * * * * * * * * ||
Or, as Prof Gary L. Bertrand of university of Missouri-Rollo summarises:
The freedom within a part of the universe may take two major forms: the freedom of the mass and the freedom of the energy. The amount of freedom is related to the number of different ways the mass or the energy in that part of the universe may be arranged while not gaining or losing any mass or energy. We will concentrate on a specific part of the universe, perhaps within a closed container. If the mass within the container is distributed into a lot of tiny little balls (atoms) flying blindly about, running into each other and anything else (like walls) that may be in their way, there is a huge number of different ways the atoms could be arranged at any one time. Each atom could at different times occupy any place within the container that was not already occupied by another atom, but on average the atoms will be uniformly distributed throughout the container. If we can mathematically estimate the number of different ways the atoms may be arranged, we can quantify the freedom of the mass. If somehow we increase the size of the container, each atom can move around in a greater amount of space, and the number of ways the mass may be arranged will increase . . . .
The thermodynamic term for quantifying freedom is entropy, and it is given the symbol S. Like freedom, the entropy of a system increases with the temperature and with volume . . . the entropy of a system increases as the concentrations of the components decrease. The part of entropy which is determined by energetic freedom is called thermal entropy, and the part that is determined by concentration is called configurational entropy.”
In short, degree of confinement in space constrains the degree of disorder/”freedom” that masses may have. And, of course, confinement to particular portions of a linear polymer is no less a case of volumetric confinement (relative to being free to take up any location at random along the chain of monomers) than is confinement of gas molecules to one part of an apparatus. And, degree of such confinement may appropriately be termed, degree of “concentration.”
Diffusion is a similar case: infusing a drop of dye into a glass of water — the particles spread out across the volume and we see an increase of entropy there. (The micro-jets case of course is effectively diffusion in reverse, so we see the reduction in entropy on clumping and then also the further reduction in entropy on configuring to form a flyable microjet.)
So, we are justified in reworking the Boltzmann expression to separate clumping/thermal and configurational components:
S = k ln (Wclump*Wconfig)
= k lnWth*Wc . . . [Eqn A.11, cf. TBO 8.2a]
or, S = k ln Wth + k ln Wc = Sth + Sc . . . [Eqn A.11.1]
We now focus on the configurational component, the clumping/thermal one being in effect the same for at-random or specifically configured DNA or polypeptide macromolecules of the same length and proportions of the relevant monomers, as it is essentially energy of the bonds in the chain, which are the same in number and type for the two cases. Also, introducing Brillouin’s negentropy formulation of Information, with the configured macromolecule [m] and the random molecule [r], we see the increment in information on going from the random to the functionally specified macromolecule:
IB = -[Scm – Scr] . . . [Eqn A.12, cf. TBO 8.3a]
Or, IB = Scr – Scm = k ln Wcr – k ln Wcm
= k ln (Wcr/Wcm) . . . [Eqn A12.1.]
Where also, for N objects in a linear chain, n1 of one kind, n2 of another, and so on to ni, we may see that the number of ways to arrange them (we need not complicate the matter by talking of Fermi-Dirac statistics, as TBO do!) is:
So, we may look at a 100-monomer protein, with as an average 5 each of the 20 types of amino acid monomers along the chain , with the aid of log manipulations — take logs to base 10, do the sums in log form, then take back out the logs — to handle numbers over 10^100 on a calculator:
Wcr = 100!/[(5!)^20] = 1.28*10^115
For the sake of initial argument, we consider a unique polymer chain , so that each monomer is confined to a specified location, i.e Wcm = 1, and Scm = 0. This yields — through basic equilibrium of chemical reaction thermodynamics (follow the onward argument in TBO Ch 8) and the Brillouin information measure which contributes to estimating the relevant Gibbs free energies (and with some empirical results on energies of formation etc) — an expected protein concentration of ~10^-338 molar, i.e. far, far less than one molecule per planet. (There may be about 10^80 atoms in the observed universe, with Carbon a rather small fraction thereof; and 1 mole of atoms is ~ 6.02*10^23 atoms. ) Recall, known life forms routinely use dozens to hundreds of such information-rich macromolecules, in close proximity in an integrated self-replicating information system on the scale of about 10^-6 m.
Of course, if one comes at the point from any of these directions, the objections and selectively hyperskeptical demands will be rolled out to fire off salvo after salvo of objections. Selective, as the blind chance needle in haystack models that cannot pass vera causa as a test, simply are not subjected to such scrutiny and scathing dismissiveness by the same objectors. When seriously pressed, the most they are usually prepared to concede, is that perhaps we don’t yet know enough, but rest assured “Science” will triumph so don’t you dare put up “god of the gaps” notions.
. . . So the debate rages on. Over the past few decades scientists have edged closer to understanding the origin of life, but there is still some way to go, which is probably why when Robyn Williams asked Lane, ‘What was there in the beginning, do you think?’, the scientist replied wryly: ‘Ah, “think”. Yes, we have no idea, is the bottom line.’
But in fact, adequate cause for FSCO/I is not hard to find: intelligently directed configuration meeting requisites a – e just above. Design.
There are trillions of cases in point.
And that is why I demand that — whatever flaws, elaborations, adjustments etc we may find or want to make — we need to listen carefully and fairly to Granville Sewell’s core point:
You are under arrest, for bringing the Emperor into disrepute . . .
. . . The second law is all about probability, it uses probability at the microscopic level to predict macroscopic change: the reason carbon distributes itself more and more uniformly in an insulated solid is, that is what the laws of probability predict when diffusion alone is operative. The reason natural forces may turn a spaceship, or a TV set, or a computer into a pile of rubble but not vice-versa is also probability: of all the possible arrangements atoms could take, only a very small percentage could fly to the moon and back, or receive pictures and sound from the other side of the Earth, or add, subtract, multiply and divide real numbers with high accuracy. The second law of thermodynamics is the reason that computers will degenerate into scrap metal over time, and, in the absence of intelligence, the reverse process will not occur; and it is also the reason that animals, when they die, decay into simple organic and inorganic compounds, and, in the absence of intelligence, the reverse process will not occur.
The discovery that life on Earth developed through evolutionary “steps,” coupled with the observation that mutations and natural selection — like other natural forces — can cause (minor) change, is widely accepted in the scientific world as proof that natural selection — alone among all natural forces — can create order out of disorder, and even design human brains, with human consciousness. Only the layman seems to see the problem with this logic. In a recent Mathematical Intelligencer article [“A Mathematician’s View of Evolution,” The Mathematical Intelligencer 22, number 4, 5-7, 2000] I asserted that the idea that the four fundamental forces of physics alone could rearrange the fundamental particles of Nature into spaceships, nuclear power plants, and computers, connected to laser printers, CRTs, keyboards and the Internet, appears to violate the second law of thermodynamics in a spectacular way.1 . . . .
What happens in a[n isolated] system depends on the initial conditions; what happens in an open system depends on the boundary conditions as well.As I wrote in “Can ANYTHING Happen in an Open System?”, “order can increase in an open system, not because the laws of probability are suspended when the door is open, but simply because order may walk in through the door…. If we found evidence that DNA, auto parts, computer chips, and books entered through the Earth’s atmosphere at some time in the past, then perhaps the appearance of humans, cars, computers, and encyclopedias on a previously barren planet could be explained without postulating a violation of the second law here . . . But if all we see entering is radiation and meteorite fragments, it seems clear that what is entering through the boundary cannot explain the increase in order observed here.” Evolution is a movie running backward, that is what makes it special.
THE EVOLUTIONIST, therefore, cannot avoid the question of probability by saying that anything can happen in an open system, he is finally forced to argue that it only seems extremely improbable, but really isn’t, that atoms would rearrange themselves into spaceships and computers and TV sets . . . [NB: Emphases added. I have also substituted in isolated system terminology as GS uses a different terminology.]
Surely, there is room to listen, and to address concerns on the merits. >>
_______________
I think we need to appreciate that the design inference applies to all three of thermodynamics, information and probability, and that we will find determined objectors who will attack all three in a selectively hyperskeptical manner. We therefore need to give adequate reasons for what we hold, for the reasonable onlooker. END
PS: As it seems unfortunately necessary, I here excerpt the Wikipedia “simple” summary derivation of 2LOT from statistical mechanics considerations as at April 13, 2015 . . . a case of technical admission against general interest, giving the case where distributions are not necessarily equiprobable. This shows the basis of the point that for over 100 years now, 2LOT has been inextricably rooted in statistical-molecular considerations (where, it is those considerations that lead onwards to the issue that FSCO/I, which naturally comes in deeply isolated islands of function in large config spaces, will be maximally implausible to discover through blind, needle in haystack search on chance and mechanical necessity):
With this in hand, I again cite a favourite basic College level Physics text, as summarised in my online note App I:
Yavorski and Pinski, in the textbook Physics, Vol I [MIR, USSR, 1974, pp. 279 ff.], summarise the key implication of the macro-state and micro-state view well: as we consider a simple model of diffusion, let us think of ten white and ten black balls in two rows in a container. There is of course but one way in which there are ten whites in the top row; the balls of any one colour being for our purposes identical. But on shuffling, there are 63,504 ways to arrange five each of black and white balls in the two rows, and 6-4 distributions may occur in two ways, each with 44,100 alternatives. So, if we for the moment see the set of balls as circulating among the various different possible arrangements at random, and spending about the same time in each possible state on average, the time the system spends in any given state will be proportionate to the relative number of ways that state may be achieved. Immediately, we see that the system will gravitate towards the cluster of more evenly distributed states. In short, we have just seen that there is a natural trend of change at random, towards the more thermodynamically probable macrostates, i.e the ones with higher statistical weights.So “[b]y comparing the [thermodynamic] probabilities of two states of a thermodynamic system, we can establish at once the direction of the process that is [spontaneously] feasible in the given system. It will correspond to a transition from a less probable to a more probable state.” [p. 284.] This is in effect the statistical form of the 2nd law of thermodynamics.Thus, too, the behaviour of the Clausius isolated system above [with interacting sub-systemd A and B that transfer d’Q to B due to temp. difference] is readily understood: importing d’Q of random molecular energy so far increases the number of ways energy can be distributed at micro-scale in B, that the resulting rise in B’s entropy swamps the fall in A’s entropy. Moreover, given that [FSCO/I]-rich micro-arrangements are relatively rare in the set of possible arrangements, we can also see why it is hard to account for the origin of such states by spontaneous processes in the scope of the observable universe.(Of course, since it is as a rule very inconvenient to work in terms of statistical weights of macrostates [i.e W], we instead move to entropy, through s = k ln W. Part of how this is done can be seen by imagining a system in which there are W ways accessible, and imagining a partition into parts 1 and 2. W = W1*W2, as for each arrangement in 1 all accessible arrangements in 2 are possible and vice versa, but it is far more convenient to have an additive measure, i.e we need to go to logs. The constant of proportionality, k, is the famous Boltzmann constant and is in effect the universal gas constant, R, on a per molecule basis, i.e we divide R by the Avogadro Number, NA, to get: k = R/NA. The two approaches to entropy, by Clausius, and Boltzmann, of course, correspond. In real-world systems of any significant scale, the relative statistical weights are usually so disproportionate, that the classical observation that entropy naturally tends to increase, is readily apparent.)
This underlying context is easily understood and leads logically to 2LOT as an overwhelmingly likely consequence. Beyond a reasonable scale, fluctuations beyond a very narrow range are statistical miracles, that we have no right to expect to observe.
And, that then refocusses the issue of connected, concurrent energy flows to provide compensation for local entropy reductions.
Comments
Zeroth law of thermodynamics: If two systems are in thermal equilibrium respectively with a third system, they must be in thermal equilibrium with each other. This law helps define the notion of temperature.
If a = b, and b = c, then a = c. Irrespective of any laws of thermodynamics. We don't need a law of thermodynamics to tell us so.Mung
April 24, 2015
April
04
Apr
24
24
2015
06:35 PM
6
06
35
PM
PDT
That a law of thermodynamics should be applicable to a thermodynamic system is hardly news.
... the second law of thermodynamics only applies to thermodynamic macrostates and microstates.
Missing the point, entirely.Mung
April 22, 2015
April
04
Apr
22
22
2015
06:36 PM
6
06
36
PM
PDT
Clavdivs, 2LOT is a direct consequence of the microstate analysis of molecular statistics, which is more fundamental. The case with paramagnetism will show that heat is not the only relevant context, and indeed heat flow into a system basically means that there is more energy spreading randomly to explore the space of possibilities for mass and energy to be arranged at micro level. From the beginning of this exchange I have stressed that micro analysis and its range of implications. One of these happens to bear the label 2LOT. Another, is the basis for a point Clausius made in 1854, translated into English 1856, i.e. the hoped for compensations associated with reduction of entropy to form FSCO/I rich clusters, must be relevantly connected causally and temporally. The common dismissal by appeal to irrelevant flows, fails. KF
PS: I am led to wonder to what extent there is familiarity with that micro view.kairosfocus
April 19, 2015
April
04
Apr
19
19
2015
07:01 AM
7
07
01
AM
PDT
kairosfocus:
I cannot tell from your latest whether you agree that the second law of thermodynamics only applies to thermodynamic macrostates and microstates.
Do you?CLAVDIVS
April 19, 2015
April
04
Apr
19
19
2015
06:46 AM
6
06
46
AM
PDT
Clavdivs,
I simply note for record, expecting that the below will be clear enough that the unbiased onlooker will readily see the balance on the merits.
I no longer expect that committed evolutionary materialists and fellow travellers will yield to facts, evidence or argument. Absent, the sort of utter system collapse that overtook the similarly ideologically locked in Marxists at the turn of the 1990's.
So, for record.
First, it has been adequately shown how the statistical-molecular picture shows how S becomes times's arrow. (Cf the PS, OP for a derivation of 2LOT from it. For over 100 years, this law has been inextricable from that grounding.)
And, the unmet challenge -- unmet on trillions of examples observed -- for FSCO/I to arise from blind needle in haystack search across config spaces is directly tied to the same considerations.
As just one instance, the very same balance of statistical weights of clusters of microstates issue is what grounds why on release of a partition between A and B a gas will expand to fill A + B rapidly (increasing its entropy also . . . ) but we would have to wait many times the duration of the cosmos to date before we would see a momentary, spontaneous return of the molecules back into A alone, leaving B empty.
But of course, it is trivially easy to push the molecules into A again by intelligently directed configuration. The reason is, that the numbers of states in which the gas is spread across A + B astronomically outweighs the number where (absent imposed constraint) the same molecules spontaneously occupy only A.
And, that is only for ORDER, not functionally specific, complex, interactive organisation per wiring diagram and associated information, FSCO/I for short.
Likewise, the coins example or its 1,000 atom paramagnetic substance in a weak magnetic field micro-analogue shows us through an easily analysed example how a predominant group cluster emerges and "sticks." It is also directly relevant to descriptive strings that are informationally equivalent to wiring diagram organised entities. This case is therefore WLOG.
The predominant cluster readily emerges and is near-50-50 clusters with a small access to fluctuations of several SD, but the SD will be quite small, sqrt npq.
In addition, though many coded strings that map to functional wiring diagrams will be in that range, they will be drastically overwhelmed by the utterly dominant near 50-50 in no particular meaningful or functional pattern. That is, we again see the familiar pattern, deeply isolated islands of function -- wiring diagram patterns sharply constrain clusters of functional configs -- in vast config spaces not thoroughly searchable on atomic-temporal resources of the sol system or observed cosmos. Where, the paramagnetic substance case is beyond any reasonable dispute a thermodynamic system. One that is directly comparable to a tray of 1,000 coins. So, the analysis for the one applies to the other, the difference being we readily see coins.
The molecular-statistical stat thermo-D analysis is thermodynamic and is inextricably tied to the macro level classical forms. Where the key analysis is fundamentally the same as that which grounds 2LOT on relative statistical weights and tendency to gravitate to predominant group.
As has been so often pointed out but studiously dismissed, ignored or brushed aside by the deeply indoctrinated.
The matter is so plain that the basic challenge is, demonstrate spontaneous origin of FSCO/I per observation on blind chance and/or mechanical necessity as a reasonable case; or else acknowledge the overwhelming fact on trillions of cases, that FSCO/I has just one routinely observed adequate cause: intelligently directed configuration.
AKA, design.
As in, vera causa.
KF
PS: Prediction, onlookers: advocates of evolutionary materialism and/or fellow travellers will continue to fail to demonstrate such causal adequacy of blind chance and mechanical necessity, but will insist on locking out the demonstrated adequate cause for FSCO/I in explaining origins.kairosfocus
April 19, 2015
April
04
Apr
19
19
2015
06:31 AM
6
06
31
AM
PDT
kairosfocus:
None of that contradicts what I said to Mung. There is no rigorously proven law that 'configuration entropy' or 'information entropy' must spontaneously increase unless exported. The second law only applies to thermodynamic entropy, which is the point that unifies scordova's formulations ... namely, they all relate to thermodynamic systems only.
I don't disagree whatsoever that many non-thermodynamic systems tend spontaneously to their most probable arrangement of microstates. However, that tendency cannot be described as being due to the second law of thermodynamics, because they're not thermodynamic systems.CLAVDIVS
April 19, 2015
April
04
Apr
19
19
2015
05:06 AM
5
05
06
AM
PDT
F/N: wiki has some interesting articles on entropy in various manifestations, let us clip as summing up typical conventional wisdom and testifying against known general interest; pardon the mangling of neatly presented formulae:
1: Configuration Entropy:
>> In statistical mechanics, configuration entropy is the portion of a system's entropy that is related to the position of its constituent particles [--> at ultramicroscopic level] rather than to their velocity or momentum. It is physically related to the number of ways of arranging all the particles of the system while maintaining some overall set of specified system properties, such as energy.
It can be shown[1] that the variation of configuration entropy of thermodynamic systems (e.g., ideal gas, and other systems with a vast number of internal degrees of freedom) in thermodynamic processes is equivalent to the variation of the macroscopic entropy defined as dS = d'Q/T, where d'Q is the heat exchanged between the system and the surrounding media, and T is temperature. Therefore configuration entropy is the same as macroscopic entropy. [d'Q used to get it to print] . . . .
The configurational entropy is related to the number of possible configurations by Boltzmann's entropy formula
S = k_B log W
where kB is the Boltzmann constant and W is the number of possible configurations. In a more general formulation, if a system can be in states n with probabilities Pn, the configurational entropy of the system is given by
S = - k_B [SUM on i] pi log pi
which in the perfect disorder limit (all Pn = 1/W) leads to Boltzmann's formula, while in the opposite limit (one configuration with probability 1), the entropy vanishes. This formulation is analogous to that of Shannon's information entropy.
The mathematical field of combinatorics, and in particular the mathematics of combinations and permutations is highly important in the calculation of configurational entropy. In particular, this field of mathematics offers formalized approaches for calculating the number of ways of choosing or arranging discrete objects; in this case, atoms or molecules. However, it is important to note that the positions of molecules are not strictly speaking discrete above the quantum level. Thus a variety of approximations may be used in discretizing a system to allow for a purely combinatorial approach. Alternatively, integral methods may be used in some cases to work directly with continuous position functions . . . >>
2: Conformational Entropy:
>> Conformational entropy is the entropy associated with the number of conformations of a molecule. The concept is most commonly applied to biological macromolecules such as proteins and RNA, but also be used for polysaccharides and other molecules. To calculate the conformational entropy, the possible conformations of the molecule may first be discretized into a finite number of states, usually characterized by unique combinations of certain structural parameters, each of which has been assigned an energy. In proteins, backbone dihedral angles and side chain rotamers are commonly used as parameters, and in RNA the base pairing pattern may be used. These characteristics are used to define the degrees of freedom (in the statistical mechanics sense of a possible "microstate"). The conformational entropy associated with a particular structure or state, such as an alpha-helix, a folded or an unfolded protein structure, is then dependent on the probability or the occupancy of that structure.
The entropy of heterogeneous random coil or denatured proteins is significantly higher than that of the folded native state tertiary structure. In particular, the conformational entropy of the amino acid side chains in a protein is thought to be a major contributor to the energetic stabilization of the denatured state and thus a barrier to protein folding.[1] However, a recent study has shown that side-chain conformational entropy can stabilize native structures among alternative compact structures.[2] The conformational entropy of RNA and proteins can be estimated; for example, empirical methods to estimate the loss of conformational entropy in a particular side chain on incorporation into a folded protein can roughly predict the effects of particular point mutations in a protein. Side-chain conformational entropies can be defined as Boltzmann sampling over all possible rotameric states:[3]
S = -R {SUM] pi ln pi
where R is the gas constant and p_{i} is the probability of a residue being in rotamer i.[3]
The limited conformational range of proline residues lowers the conformational entropy of the denatured state and thus increases the energy difference between the denatured and native states. A correlation has been observed between the thermostability of a protein and its proline residue content.[4] >>
3: Entropy of mixing
>>Assume that the molecules of two different substances are approximately the same size, and regard space as subdivided into a square lattice whose cells are the size of the molecules. (In fact, any lattice would do, including close packing.) This is a crystal-like conceptual model to identify the molecular centers of mass. If the two phases are liquids, there is no spatial uncertainty in each one individually. (This is, of course, an approximation. Liquids have a "free volume". This is why they are (usually) less dense than solids.) Everywhere we look in component 1, there is a molecule present, and likewise for component 2. After the two different substances are intermingled (assuming they are miscible), the liquid is still dense with molecules, but now there is uncertainty about what kind of molecule is in which location. Of course, any idea of identifying molecules in given locations is a thought experiment, not something one could do, but the calculation of the uncertainty is well-defined.
We can use Boltzmann's equation for the entropy change as applied to the mixing process
Delta S_{mix}= k_B ln Omega,
where k_B, is Boltzmann's constant. We then calculate the number of ways Omega, of arranging N_1, molecules of component 1 and N_2, molecules of component 2 on a lattice, where
N = N_1 + N_2,
is the total number of molecules, and therefore the number of lattice sites. Calculating the number of permutations of N, objects, correcting for the fact that N_1, of them are identical to one another, and likewise for N_2,
Omega = N!/N_1!N_2!,
After applying Stirling's approximation for the factorial of a large integer m:
ln m! = sum_k ln k ~ [Integral]{1}^{m}dk ln k
= mln m - m ,
the result is Delta S_{mix} = -k_B[N_1 *ln(N_1/N) + N_2 * ln(N_2/N)] = -k_B N*[x_1*ln x_1 + x_2*ln x_2],
where we have introduced the mole fractions, which are also the probabilities of finding any particular component in a given lattice site.
x_1 = N_1/N = p_1; and x_2 = N_2/N = p_2,
Since the Boltzmann constant k_B = R / N_A,, where N_A, is Avogadro's number, and the number of molecules N = n*N_A, we recover the thermodynamic expression for the mixing of two ideal gases,
Delta S_{mix} = -nR[x_1*ln x_1 + x_2*ln x_2] . . . .
The entropy of mixing is also proportional to the Shannon entropy or compositional uncertainty of information theory, which is defined without requiring Stirling's approximation. Claude Shannon introduced this expression for use in information theory, but similar formulas can be found as far back as the work of Ludwig Boltzmann and J. Willard Gibbs. The Shannon uncertainty is completely unrelated to the Heisenberg uncertainty principle in quantum mechanics, and is defined by
H = - sum_{i) p_i * ln (p_i)
To relate this quantity to the entropy of mixing, we consider that the summation is over the various chemical species, so that this is the uncertainty about which kind of molecule is in any one site. It must be multiplied by the number of sites N, to get the uncertainty for the whole system. Since the probability p_i, of finding species i, in a given site equals the mole fraction x_i, we again obtain the entropy of mixing on multiplying by the Boltzmann constant k_B.
Delta S_{mix} = -N k_B*sum_{i}x_i*ln x_i>>
4: Entropy (information theory)
>> The inspiration for adopting the word entropy in information theory came from the close resemblance between Shannon's formula and very similar known formulae from statistical mechanics.
In statistical thermodynamics the most general formula for the thermodynamic entropy S of a thermodynamic system is the Gibbs entropy,
S = - k_B [sum] p_i * ln p_i,
where kB is the Boltzmann constant, and pi is the probability of a microstate. The Gibbs entropy was defined by J. Willard Gibbs in 1878 after earlier work by Boltzmann (1872).[9]
The Gibbs entropy translates over almost unchanged into the world of quantum physics to give the von Neumann entropy, introduced by John von Neumann in 1927,
S = - k_B { Tr}(rho ln rho),
where rho is the density matrix of the quantum mechanical system and Tr is the trace.
At an everyday practical level the links between information entropy and thermodynamic entropy are not evident. Physicists and chemists are apt to be more interested in changes in entropy as a system spontaneously evolves away from its initial conditions, in accordance with the second law of thermodynamics, rather than an unchanging probability distribution. And, as the minuteness of Boltzmann's constant kB indicates, the changes in S/kB for even tiny amounts of substances in chemical and physical processes represent amounts of entropy that are extremely large compared to anything in data compression or signal processing. Furthermore, in classical thermodynamics the entropy is defined in terms of macroscopic measurements and makes no reference to any probability distribution, which is central to the definition of information entropy.
At a multidisciplinary level, however, connections can be made between thermodynamic and informational entropy, although it took many years in the development of the theories of statistical mechanics and information theory to make the relationship fully apparent. In fact, in the view of Jaynes (1957), thermodynamic entropy, as explained by statistical mechanics, should be seen as an application of Shannon's information theory: the thermodynamic entropy is interpreted as being proportional to the amount of further Shannon information needed to define the detailed microscopic state of the system, that remains uncommunicated by a description solely in terms of the macroscopic variables of classical thermodynamics, with the constant of proportionality being just the Boltzmann constant. For example, adding heat to a system increases its thermodynamic entropy because it increases the number of possible microscopic states of the system that are consistent with the measurable values of its macroscopic variables, thus making any complete state description longer. (See article: maximum entropy thermodynamics). Maxwell's demon can (hypothetically) reduce the thermodynamic entropy of a system by using information about the states of individual molecules; but, as Landauer (from 1961) and co-workers have shown, to function the demon himself must increase thermodynamic entropy in the process, by at least the amount of Shannon information he proposes to first acquire and store; and so the total thermodynamic entropy does not decrease (which resolves the paradox). Landauer's principle imposes a lower bound on the amount of heat a computer must generate to process a given amount of information, though modern computers are far less efficient . . . >>
5: Entropy in thermodynamics and information theory
>> Theoretical relationship
Despite the foregoing, there is a difference between the two quantities. The information entropy H can be calculated for any probability distribution (if the "message" is taken to be that the event i which had probability pi occurred, out of the space of the events possible), while the thermodynamic entropy S refers to thermodynamic probabilities pi specifically. The difference is more theoretical than actual, however, because any probability distribution can be approximated arbitrarily closely by some thermodynamic system.
Moreover, a direct connection can be made between the two. If the probabilities in question are the thermodynamic probabilities pi: the (reduced) Gibbs entropy sigma can then be seen as simply the amount of Shannon information needed to define the detailed microscopic state of the system, given its macroscopic description. Or, in the words of G. N. Lewis writing about chemical entropy in 1930, "Gain in entropy always means loss of information, and nothing more". To be more concrete, in the discrete case using base two logarithms, the reduced Gibbs entropy is equal to the minimum number of yes–no questions needed to be answered in order to fully specify the microstate, given that we know the macrostate.
Furthermore, the prescription to find the equilibrium distributions of statistical mechanics—such as the Boltzmann distribution—by maximising the Gibbs entropy subject to appropriate constraints (the Gibbs algorithm) can be seen as something not unique to thermodynamics, but as a principle of general relevance in statistical inference, if it is desired to find a maximally uninformative probability distribution, subject to certain constraints on its averages. (These perspectives are explored further in the article Maximum entropy thermodynamics.)
Information is physical
A physical thought experiment demonstrating how just the possession of information might in principle have thermodynamic consequences was established in 1929 by Leó Szilárd, in a refinement of the famous Maxwell's demon scenario.
Consider Maxwell's set-up, but with only a single gas particle in a box. If the supernatural demon knows which half of the box the particle is in (equivalent to a single bit of information), it can close a shutter between the two halves of the box, close a piston unopposed into the empty half of the box, and then extract k_B T * ln 2 joules of useful work if the shutter is opened again. The particle can then be left to isothermally expand back to its original equilibrium occupied volume. In just the right circumstances therefore, the possession of a single bit of Shannon information (a single bit of negentropy in Brillouin's term) really does correspond to a reduction in the entropy of the physical system. The global entropy is not decreased, but information to energy conversion is possible.
Using a phase-contrast microscope equipped with a high speed camera connected to a computer, as demon, the principle has been actually demonstrated.[2] In this experiment, information to energy conversion is performed on a Brownian particle by means of feedback control; that is, synchronizing the work given to the particle with the information obtained on its position. Computing energy balances for different feedback protocols, has confirmed that the Jarzynski equality requires a generalization that accounts for the amount of information involved in the feedback. >>
In short, once molecular statistics, probability and information considerations are factored in, we begin to see deep connexions. Those connexions point to how the particular aspect of configuration, FSCO/I becomes significant. For, as can readily be shown, a blind, sol system or observed cosmos scope needle in haystack chance and necessity search of config space is maximally implausible to find deeply isolated islands of function. And, this is closely tied to the molecular underpinnings of 2LOT.
KFkairosfocus
April 19, 2015
April
04
Apr
19
19
2015
03:09 AM
3
03
09
AM
PDT
F/N: to highlight the issue of relevance of compensating flows, I have added to the OP a page shot from Clausius' 1854 paper, as published in English. It should be noted that 2LOT was developed in connexion with steam engines and the like, which give context to the statement. Note, the first technically effective refrigerator was built by Perkins in 1834, and a patent was granted on the first practical design in 1956. Boltzmann's first work was in the 1870's and Gibbs published at the turn of C20. Einstein's Annalen der Physik paper on Brownian motion, which pivots on viewing the particles of pollen etc as partaking of the molecular motion, is 1905. KFkairosfocus
April 18, 2015
April
04
Apr
18
18
2015
05:36 PM
5
05
36
PM
PDT
Clavdivs,
With all due respect, you are simply refusing to address the first facts of the molecular underpinnings of 2LOT, which are directly tied to molecular configurations, e.g. S = k log W. W being in effect the count of number of ways mass and energy can be arranged at micro levels consistent with a macro-observable state.
Second, FYI, if you were to examine the thread above regarding L K Nash (a not inconsiderable name) and his use of 500 or 1000 coins as an example of configuration, you will find a direct translation to a paramagnetic substance in a weak B field, with two possible alignments of atoms N-up and N-down; based on an example presented by Mandl; again a not inconsiderable name.
The pattern of the trend to an equilibrium cluster of arrangements near 50-50 distribution emerges, as does the applicability of the binomial distribution.
Overall, thermodynamics, including 2LOT, is inextricably tied to this statistical-molecular perspective; it has been for over 100 years. (I suggest you take a look at the PS to the OP on this. 2LOT is directly connected to the strong trend of systems to move towards thermodynamic equilibrium reflective of relative weights of clusters of microstates. And, this is not a novelty.)
That analysis then brings directly to bear, e.g. the presence of functionally specific configs that carry say an ASCII coded message in English of 143 characters and the maximal implausibility of accessing same on blind chance and mechanical necessity precisely because the 10^80 atoms of the observed cosmos, working at 10^14 trials per s and for 10^17 s, can only test 10^111 possibilities of the 10^301, of which the vast majority will be near 50-50 in no particular order.
In short, blind needle in haystack search follows exactly the pattern elucidated by using 1,000 coins.
Too much stack, too few needles, far too little search capability to examine more than a tiny, effectively negligible fraction of configs.
The same point that has been underscored year after year but studiously dismissed or ignored by those whose system of thought demands repeated statistical miracles.
And feeding in thermal energy to the system will make no difference to the balance of circumstances; the maximum just given is well beyond reasonable actual processing reach. Too much stack, too few needles.
This is an illustration of why it is so readily observable that FSCO/I is only produced by intelligently directed configuration.
And, you would do well to recall that ever since the case of 35 Xe atoms spelling out IBM coming on 30 years past, there has been a considerable demonstration of similar cases of intelligently directed configuration producing FSCO/I-rich patterns at that level.
KFkairosfocus
April 18, 2015
April
04
Apr
18
18
2015
04:14 PM
4
04
14
PM
PDT
kairosfocus:
This is directly connected to the analysis that grounds 2LOT on molecular statistics considerations, as can readily be seen above for those interested in a sound rather than a rhetorically convenient conclusion.
'Rhetorically convenient' my foot. We're talking about what is, and what is not, a recognised law of nature.
In fact, there simply are no credible cases of such complex wiring diagram functionality coming about in our observation by blind chance and mechanical necessity, whilst there are literally trillions of such by design.
You have simply bypassed my point altogether. Here it is again: the second law is proven as a law of nature only in relation to the thermodynamics of systems i.e. microstates measured in terms of energy. There is no recognised, proven law of nature of "configuration entropy" or "wiring entropy" or "coin toss entropy".
Accordingly, you can only apply the recognised, proven second law of thermodynamics to systems you are measuring in terms of energy and thermodynamic variables like temperature, pressure, etc. If you are measuring configuration, wiring or coin tosses, you cannot apply the recognised second law of thermodynamics.
That was scordova's point, which I was pointing out again to Mung.CLAVDIVS
April 18, 2015
April
04
Apr
18
18
2015
03:40 PM
3
03
40
PM
PDT
Clavdivs,
Entropy as discussed is a state function linked to molecular configurations of a system, per S = k log W etc.
As a state function, the specificity of the state is relevant to W, and in this case particular molecular configurations are material as we are addressing function based on config, where the function is evident at a much coarser resolution than the molecular scale of nm, e.g. a bacterial flagellum or the protein synthesis system or other life form relevant FSCO/I rich functions.
The challenge is, in a darwin pond or the like, to get to such FSCO/I rich configs, by harvesting the available thermal energy, which at this scale goes to random molecular motions.
The answer is, that the search space challenge is such that the motion to equilibrium trend pushes the system spontaneously away from the sort of highly complex and specific configs required. And, that a search on the gamut of the solar system or observed cosmos is maximally unlikely to find such configs blindly, due to the island of function in a sea of non-functional configs problem; once structured description length exceeds 500 - 1,000 bits.
This is directly connected to the analysis that grounds 2LOT on molecular statistics considerations, as can readily be seen above for those interested in a sound rather than a rhetorically convenient conclusion.
Appealing to irrelevant energy flows that normally just go to increased random agitation in a context where the entire resources of the solar system or observed cosmos devoted to such a search would with all but absolute certainty fail to discover such, is a grossly inadequate answer.
Especially when we have easy access to the only observationally warranted adequate cause of FSCO/I, at both macro and molecular levels, intelligently directed configuration.
The combination of empirical observation base of trillions and the molecular underpinnings of 2LOT strongly indicate that such FSCO/I is a reliable signature of design. It is quire clear that the reason this is resisted is ideological, not logical or empirical.
In fact, there simply are no credible cases of such complex wiring diagram functionality coming about in our observation by blind chance and mechanical necessity, whilst there are literally trillions of such by design.
Indeed, to produce objecting comments, you further extended that base of observations, creating FSCO/I rich comments as symbol strings, by design.
KFkairosfocus
April 18, 2015
April
04
Apr
18
18
2015
07:34 AM
7
07
34
AM
PDT
DNA-J: This was already discussed, the issue missed by those who appeal to the compensation argument -- notice what Clausius observed, aptly -- is always relevance. You would have to connect the melting ice tot he construction of the genome, brains, embryo etc through energy converters and constructors. Acting at molecular level, the operative level in the living cell. And, those who want to sniff at fishing reels should notice that this is a demonstration with a familiar item, of FSCO/I, which is then articulated to the cellular metabolism network and the protein synthesis part of it. KFkairosfocus
April 18, 2015
April
04
Apr
18
18
2015
06:28 AM
6
06
28
AM
PDT
Mung:
Salvador retreats to individual formulations of the second law, but what on earth unifies these individual formulations, and why should ID theorists care if they fail to address “the Clausius formulation” of the 2LOT?
What unifies these individual formulations is these are the only formulations that are proven as a law of nature, viz. all systems spontaneously increase their thermodynamic entropy, unless they can export it to their surroundings. Thus, in statistical mechanics, the 2nd law is a proven law of nature only for microstates that are measured in terms of energy.
It is not a proven law of nature that non-thermodynamic entropy, such as information entropy, coin tosses etc, always increases unless exported, because the microstates are not being measured in terms of energy.CLAVDIVS
April 18, 2015
April
04
Apr
18
18
2015
06:21 AM
6
06
21
AM
PDT
kf at 66.
Great point: informational entropy and "heat" entropy are really, thanks to the statistical underpinnings of 2LOT, inextricably interconnected.
So how much ice would I need to melt in order to account for the information content of he human genome?
Also, you do realize, don't you, that when Clausius writes
Heat can never pass from a colder to a warmer body without some other change, connected therewith, occurring at the same time.
the radiation that the earth emits into space would count as a change "connected therewith". The "coupling" could be any contingent relationship, it doesn't have to be a piston rod or axle. Although those do feature in many popular examples, which may have caused some confusion...DNA_Jock
April 18, 2015
April
04
Apr
18
18
2015
05:28 AM
5
05
28
AM
PDT
Graham2 I would say come back when you have a more open mind, but it appears your mind was so open in the past that you ended up 'losing your mind'.
"Hawking’s entire argument is built upon theism. He is, as Cornelius Van Til put it, like the child who must climb up onto his father’s lap into order to slap his face.
Take that part about the “human mind” for example. Under atheism there is no such thing as a mind. There is no such thing as understanding and no such thing as truth. All (Stephen) Hawking is left with is a box, called a skull, which contains a bunch of molecules.
Hawking needs God in order to deny Him."
- Cornelius Hunter –
Photo – “of all the things I’ve lost, I think I miss my mind the most”
http://3.bp.blogspot.com/-H-kjiGN_9Fw/URkPboX5l2I/AAAAAAAAATw/yN18NZgMJ-4/s1600/rob4.jpg
bornagain77
April 18, 2015
April
04
Apr
18
18
2015
04:58 AM
4
04
58
AM
PDT
Of related note:
Ian Juby recently interviewed Dr. Andrew McIntosh. Dr. Andrew McIntosh is an expert in Thermodynamics who explains the intractable problems for neo-Darwinism from thermodynamics in a very easy to understand manner for the lay person.
Dr. Andrew McIntosh interview with Ian Juby - video
https://www.youtube.com/watch?v=D2PZ23ufoIQbornagain77
April 18, 2015
April
04
Apr
18
18
2015
04:48 AM
4
04
48
AM
PDT
Jeeez, fishing reels and the shroud of Turin, all in the one thread. Im outa here.Graham2
April 18, 2015
April
04
Apr
18
18
2015
04:30 AM
4
04
30
AM
PDT
Mung, for 100+ years, 2LOT has been inextricably rooted in molecular-statistical terms, and these terms can be tied very directly to metrics of average missing info to identify particular microstate on knowing only macro-observable state defining variables. The net result as say L K Nash long since pointed out, is that if a system is initially in far from "equilibrium" condition and only spontaneous forces typically available are at work, it will strongly tend to the predominant cluster of states and will tend to stay there; i.e. we have identified what thermodynamic equilibrium is and how it arises and gains its stability. This will obviously hold so long as there is reasonable access for particles and energy to interact and undertake a spontaneous walk away from initial state. It does not strictly require every microstate is equiprobable but that simplification makes the mathematics enormously more tractable. And, if coins are deemed unrealistic, Mandl has kindly given us an equivalent, a toy paramagnetic substance in a weak B field. But then, instantly, we can see that it is the same logic at work in both cases. Just, we can inspect coins directly by opening up the box so to speak. Yes, magnitudes of involved entropy numbers for such an aspect are low relative to those in many heat flow cases. So what, our interest is in likelihood of finding deeply isolated islands of function on blind needle in haystack search. On having complexity at least 500 - 1,000 bits, we find that FSCO/I is maximally implausible to be found on such blind search. Basic probability, info and thermodynamics converge on the same point. And, that brings us back to seeing, on the logic that grounds 2LOT and is inextricable from it, that we have a good analytical rationale for the empirical observation that FSCO/I is an empirically highly reliable sign of intelligently directed configuration as adequate cause. KF
PS: The onlooker should be able to note from the studious silence of objectors who routinely appeal to irrelevant energy etc flows as "compensating" for origin of FSCO/I, that they do not have a serious response. The following version of the Clausius statement of 2LOT, is most highly and directly relevant:
Heat can never pass from a colder to a warmer body without some other change, connected therewith, occurring at the same time.
As in, relevant to and involved in the same process. As also in: energy, mass and info flows, connected to energy converters that produce shaft work and/or ordered flows that with prescriptive info, couple to constructors that under cybernetic control produce FSCO/I based entities. The assembly of a fishing reel or a protein, alike, exemplify the pattern.kairosfocus
April 18, 2015
April
04
Apr
18
18
2015
03:09 AM
3
03
09
AM
PDT
kf, I have long been an advocate of the expression of thermodynamics in information theory terms. This view is founded upon statistical mechanics. As you say, it has long and respected history.
Salvador retreats to individual formulations of the second law, but what on earth unifies these individual formulations, and why should ID theorists care if they fail to address "the Clausius formulation" of the 2LOT?
An ID argument does not have to be formulated in long-outdated terms that have been subsumed under broader principles.
I think we agree on this.Mung
April 17, 2015
April
04
Apr
17
17
2015
10:23 PM
10
10
23
PM
PDT
Wikipedia:
In probability theory, the law of large numbers (LLN) is a theorem that describes the result of performing the same experiment a large number of times. According to the law, the average of the results obtained from a large number of trials should be close to the expected value, and will tend to become closer as more trials are performed.
So we're talking basic probability here, or something a bit more advanced.
What's the expected value for an ID argument that relies in the LLN?
http://en.wikipedia.org/wiki/Expected_value
Oh sure. Just basic probability and all. Boringly obvious.
Trial: The painting on the ceiling of the Sistine Chapel.
Wikipedia:
The Sistine Chapel (Latin: Sacellum Sixtinum; Italian: Cappella Sistina) is a chapel in the Apostolic Palace, the official residence of the Pope, in Vatican City. Originally known as the Cappella Magna, the chapel takes its name from Pope Sixtus IV, who restored it between 1477 and 1480. Since that time, the chapel has served as a place of both religious and functionary papal activity. Today it is the site of the Papal conclave, the process by which a new pope is selected. The fame of the Sistine Chapel lies mainly in the frescos that decorate the interior, and most particularly the Sistine Chapel ceiling and The Last Judgment by Michelangelo.
How many times shall we repeat this trial?
What is the expected value?
Should we conclude that it's not designed?Mung
April 17, 2015
April
04
Apr
17
17
2015
10:10 PM
10
10
10
PM
PDT
Mung:
Including, elsewhere?
This thread and its OP serve to show the 100+ year inextricable connexion between the statistical-molecular view and 2LOT, thence how the molecular-state view shows why FSCO/I on blind needle in haystack search is maximally implausible.
And, information is involved as the entropy of an entity can properly viewed as a metric of avg missing info to specify microstate on knowing the macro one.
Probabilities and fluctuations crop up, pointing to why there is a strong trend to equilibrium and why it is sticky, tending to persist once you get there.
Bonus, the coins example thanks to Mandl can be directly translated into studying a toy paramagnetic system.
KF
PS: Y/day I had a major reminder of why I do not wish to have anything to deal with the fever swamp, rage and hate fest, defamatory cyberstalker atheism advocates and their more genteel enablers. I wonder if such understand what they say about themselves when they carry on as they do when they think they can get away with it?kairosfocus
April 17, 2015
April
04
Apr
17
17
2015
06:42 AM
6
06
42
AM
PDT
Salvador no longer wishes to discuss thermodynamics, or information, or the law of large numbers, or probability.
Perhaps a wise choice.Mung
April 16, 2015
April
04
Apr
16
16
2015
07:42 PM
7
07
42
PM
PDT
SalC & Mung:
I discussed the nature of chance (in different senses) here some time back:
https://uncommondescent.com/intelligent-design/id-foundations-1a-what-is-chance-a-rough-definition/
I would suggest that there are generally relevant causal factors which include chance, in both senses of the uncontrollable/unpredictable and the inherently stochastic quantum processes.
Clipping:
Chance:
TYPE I: the clash of uncorrelated trains of events such as is seen when a dropped fair die hits a table etc and tumbles, settling to readings in the set {1, 2, . . . 6} in a pattern that is effectively flat random. In this sort of event, we often see manifestations of sensitive dependence on initial conditions, aka chaos, intersecting with uncontrolled or uncontrollable small variations yielding a result predictable in most cases only up to a statistical distribution which needs not be flat random.
TYPE II: processes — especially quantum ones — that are evidently random, such as quantum tunnelling as is the explanation for phenomena of alpha decay. This is used in for instance zener noise sources that drive special counter circuits to give a random number source. Such are sometimes used in lotteries or the like, or presumably in making one time message pads used in decoding.
This is what I then went on to say:
(So, we first envision nature acting by low contingency mechanical necessity such as with F = m*a . . . think a heavy unsupported object near the earth’s surface falling with initial acceleration g = 9.8 N/kg or so. That is the first default. Similarly, we see high contingency knocking out the first default — under similar starting conditions, there is a broad range of possible outcomes. If things are highly contingent in this sense, the second default is: CHANCE. That is only knocked out if an aspect of an object, situation, or process etc. exhibits, simultaneously: (i) high contingency, (ii) tight specificity of configuration relative to possible configurations of the same bits and pieces, (iii) high complexity or information carrying capacity, usually beyond 500 – 1,000 bits. And for more context you may go back to the same first post, on the design inference. And yes, that will now also link this for an all in one go explanation of chance, so there!)
Okie, let us trust there is sufficient clarity for further discussion on the main point. Remember, whatever meanings you may wish to inject into “chance,” the above is more or less what design thinkers mean when we use it — and I daresay, it is more or less what most people (including most scientists) mean by chance in light of experience with dice-using games, flipped coins, shuffled cards, lotteries, molecular agitation, Brownian motion and the like. At least, when hair-splitting debate points are not being made. It would be appreciated if that common sense based usage by design thinkers is taken into reckoning.
I just note, that this is deeply embedded in the statistical mechanical picture of matter at molecular level.
KF
PS: That One sees chance processes at work does not preclude possibility of influence or intervention by purposeful actors as relevant. The same tumbling dice can be loaded or set to a desired reading.kairosfocus
April 16, 2015
April
04
Apr
16
16
2015
02:24 AM
2
02
24
AM
PDT
SalC (attn Mung):
Did you follow LKN's actual analysis (not to mention adaptation of Mandl's paramagnetic model . . . he illustrated with 9 units, referred 10^20 to 23 as more realistic)?
I am getting lazy, want to copy-paste not type out. But, here's LKN, p. 26 2nd edn, on the pattern that I highlighted above from Yavorski-Pinski:
As a mundane illustration, imagine a box in which 1,000 distinguishable coins [--> extend to the paramagnetic model if you do not like coins . . . ] all lie heads up. This perfectly ordered configuration can arise in but one way. Suppose that, after shaking the box slightly, we find its coins in the less orderly 900H/100T configuration, which can arise in some 10^140 ways. Once the box has been shaken, this configuration is favored by a margin of 10^140:1 over the initial perfectly ordered configuration. Suppose then that, after further shaking, we find the contents of the box in the still less ordered 700H/300T configuration, which can arise in some 10^265 different ways. The appearance of this configuration is favored by a margin of 10^125:1 over retention of the intermediate 900H/100T configuration, and by a margin of 10^265:1 over the reappearance of the initial completely ordered configuration. Suppose finally that the box is subjected to prolonged and very vigorous shaking. We are then likely to find the contents of the box in some close approximation tot he completely random 500H/500T configuration, which can arise in some 10^300 different ways. And now still further shaking is unlikely to produce any significant departure from the wholly disordered PG [= predominant group] configurations in which W has at last assumed its maximum value. This purely pedestrian illustration [--> remember the paramagnetic substance model] thus shows how a progressive increase in "disorder" necessarily accompanies an approach to equilibrium [ --> moves to PG, stays there within several SD's thereafter . . . a yardstick for fluctuations" . . . as an overwhelming likelihood] characterized by the assumption of configurations with ever increasing values of W. And what may appear at first to be a purposeful "drive," towards states of maximal disorder, can now be seen to arise from the operation of blind chance in an assembly where all microstates remain equally probable [--> a postulate used in modelling reality and justified by success, but the effect will largely remain if there is simply a reasonably random distribution of probabilites i.e. so long as there is not something that locks in a far from equilibrium condition], but where an overwhelming proportion of all microstates is associated with the maximally disordered [--> least specified or restricted] PG configurations.
Of course, LKN uses the order/disorder contrast that is typically deprecated by current personalities, but his point in context is reasonable and readily understood. Where if one does not like a discussion on in effect microscopic coins, a paramagnetic substance of 1000 atoms will do . . . maybe a cryogenic array.
His point comes out clearly, drawing out the tendency, once nothing blocks it, for configurations at micro level to strongly trend towards a cluster of microstates close to the peak of the binomial distribution; maximising W in S = k ln W. This draws out the same trend that is then exhibited as underlying the 2LOT, and as the appendix to the OP shows, we can derive the numerical form from it.
In short, the macro-level 2LOT rests on an underlying microstates view, and on interactions and changes driven by implications of molecular level randomness. As a further consequence we see how interactions between subsystems of an overall system that may be isolated, will be such that transfer of heat from A to B will net yield an overall increase in the number of ways mass and energy may be distributed at micro-level as the number of ways added for B plausibly exceeds the number lost by A on transfer of an increment d'Q.
The next point is, that the same micro, molecular scale picture now brings to bear the force of the last part of the Clausius statement . . . and recall, there are multiple statements that significantly overlap . . . you have repeatedly cited (but seem to have overlooked):
Heat can never pass from a colder to a warmer body without some other change, connected therewith, occurring at the same time.
In short, "compensation" is observed to be characteristically relevant, rather than irrelevant.
And more broadly, on the same underlying molecular picture, we can see why it is futile to expect the sort of huge "fluctuation" implied by alleged spontaneous appearance of FSCO/I, other than where there is a cluster of constraints as highlighted in the OP as updated BTW:
. . . starting from the “typical” diffused condition [ --> say, in a Darwin's warm pond], we readily see how a work to clump at random emerges, and a further work to configure in functionally specific ways.
With implications for this component of entropy change. [--> Entropy being a state function, we may reasonably break it up into components, where also such components may not be freely inter-convertible, e.g. work to clump without regard to configuration, then further work to configure per wiring diagram]
As well as for the direction of the clumping and assembly process to get the right parts together, organised in the right cluster of ways that are consistent with function.
Thus, there are implications of prescriptive information that specifies the relevant wiring diagram. (Think, AutoCAD etc as a comparison.)
Pulling back, we can see that to achieve such, the reasonable — and empirically warranted — expectation, is
a: to find energy, mass and information sources and flows associated with
b: energy converters that provide shaft work or controlled flows [I use a heat engine here but energy converters are more general than that], linked to
A heat Engine partially converts heat into work: constructors that carry out the particular work, under control of
d: relevant prescriptive information that explicitly or implicitly regulates assembly to match the wiring diagram requisites of function,
. . . [u/d Apr 13] or, comparing an contrasting a Maxwell Demon model that imposes organisation by choice with use of mechanisms, courtesy Abel:
. . . also with
e: exhaust or dissipation otherwise of degraded energy [typically, but not only, as heat . . . ] and discarding of wastes. (Which last gives relevant compensation where dS cosmos rises. Here, we may note SalC’s own recent cite on that law from Clausius, at 570 in the previous thread that shows what “relevant” implies: Heat can never pass from a colder to a warmer body without some other change, connected therewith, occurring at the same time.)
This contrasts sharply with the tendency to appeal to irrelevant flows without couplings. But the empirical evidence favours the above, as well as the underlying analysis on clusters of microstates.
All of which is why I tend to speak on the statistical molecular processes undergirding and intertwined inextricably with 2LOT for 100+ years now. As well as that the tendency outlined is in effect the statistical form of 2LOT, which is a trivial extension from it.
There is no suspect novelty tracing to Niw and the undersigned.
The 500 or 1000 coin model directly connects and indeed it is arguable that the same thing is happening with macro level coins as with a paramagnetic substance, only we can see.
And, without relevant and properly coupled energy, mass and information flows tied to energy converters and constructors controlled by prescriptive information, the molecular dynamics undergirding 2LOT are not reasonably compatible with origin of FSCO/I rich structures.
Which, is where I came in way back.
However, I do not expect such reasoning to be directly persuasive to those who have shown willingness to burn down the house of reason itself to sustain their evolutionary materialist ideology or accommodation to it. But, as more and more people wake up to what is going on, such will feel and fear social pressure occasioned by exposure to the point that their scheme is unreasonable and untenable.
That is the point when actual dialogue may begin.
Meanwhile, the issue is to make our case clear and solid.
Thermodynamics reasoning, information reasoning and probability reasoning -- which converge and interact profoundly -- all have a part to play.
KFkairosfocus
April 15, 2015
April
04
Apr
15
15
2015
01:26 AM
1
01
26
AM
PDT
Mung: Chance is not a cause
Does that mean chance can't be an explanation for something?scordova
April 14, 2015
April
04
Apr
14
14
2015
08:49 PM
8
08
49
PM
PDT
kairosfocus:
PS: I again note that in L K Nash’s classical introduction to statistical thermodynamics, the example of a 500 or 1,000 or so coin system is used as the key introductory example.
"Statistical analysis shows that the emergence of a predominant configuration is characteristic of any assembly with a large number (N) of units, and that the peaking already observable with a 10-5 assembly becomes ever more pronounced as N increases. We can easily bring out the essence of this analysis by considering the results obtained by repeatedly tossing a well-balanced coin, which can fall in only two ways: head (H) or tails (T)."
- p. 10
Not even going to get into the exercise on p. 124.Mung
April 14, 2015
April
04
Apr
14
14
2015
08:17 PM
8
08
17
PM
PDT
Further:
Postulate III.The entropy of a composite system is additive over the constituent subsystems. The entropy is continuous and differentiable and is a monotonicaly increasing function of the energy.
Shades of Shannon/Weaver.Mung
April 14, 2015
April
04
Apr
14
14
2015
07:55 PM
7
07
55
PM
PDT
Since we're on a roll:
Postulate II.There exists a function (called the entropy S) of the extensive parameters of any composite system, defined for all equilibrium states and having the following property: The values assumed by the extensive parameters in the absence of an internal constraint are those that maximize the entropy over the manifold of constrained equilibrium states.
- H.B. Callen. Thermodynamics
Note the failure to mention any specific "version" of the second law. Is it therefore deficient in some way?
Not applicable to thermodynamics? How so?
Folks, this is from 1960. We're sharing what has been known for decades.Mung
April 14, 2015
April
04
Apr
14
14
2015
07:48 PM
7
07
48
PM
PDT
Let's continue with Henry B. Callen:
Postulate I.There exist particular states (called equilibrium states) of simple systems that, macroscopically, are characterized completely by the internal energy U, the volume V, and the mole numbers N1, N2,...,Nr of the chemical components.
The question for Salvador is simple.
Which formulation (Sal: version) of the second law does this postulate violate?
Are there equilibrium states of thermodynamic systems that this postulate fails to recognize?Mung
April 14, 2015
April
04
Apr
14
14
2015
07:32 PM
7
07
32
PM
PDT
Salvador:
Pardon, you give a 4,458 word OP and yet are unwilling to state the actual version of the 2nd Law you are working from.
LoL! What more could Salvador say to express just how lost he is?Mung
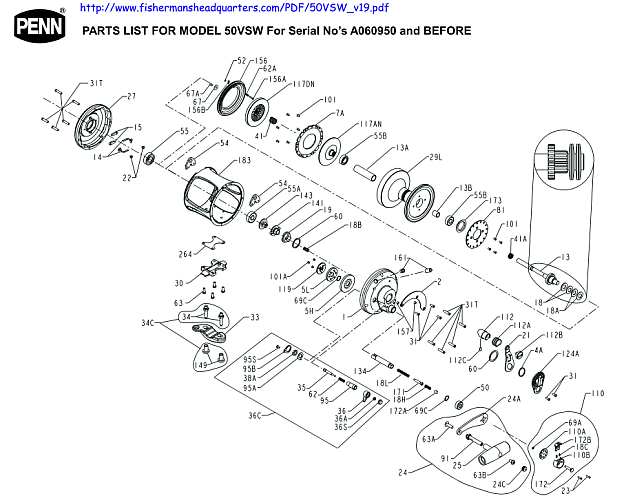
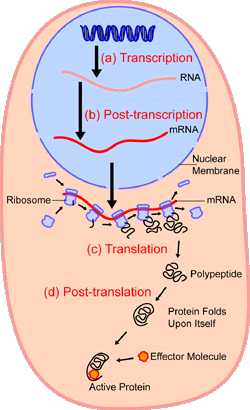

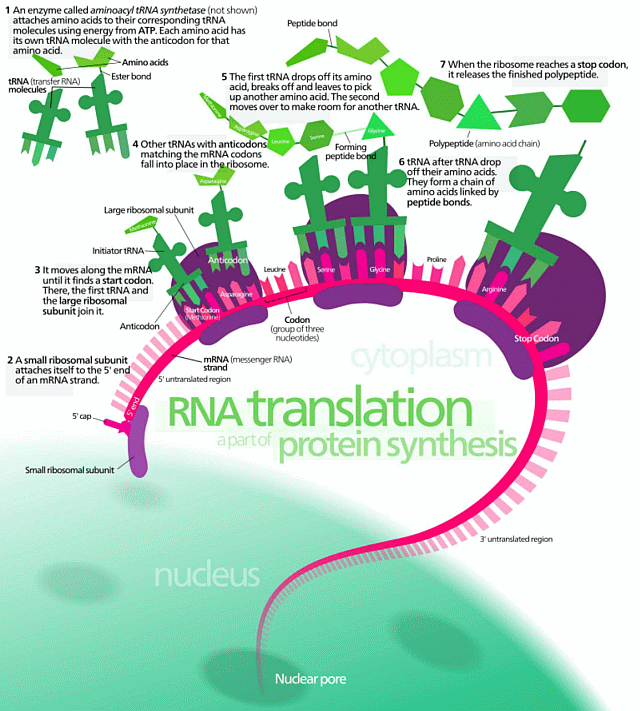
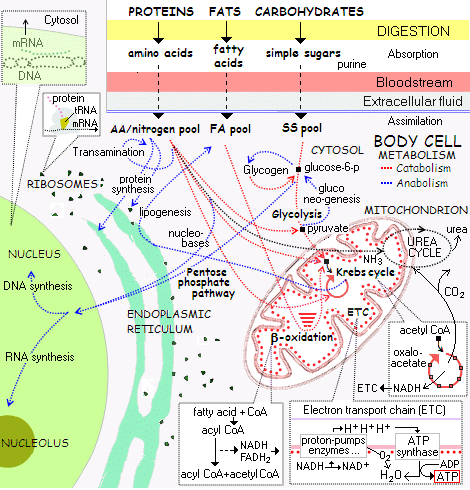
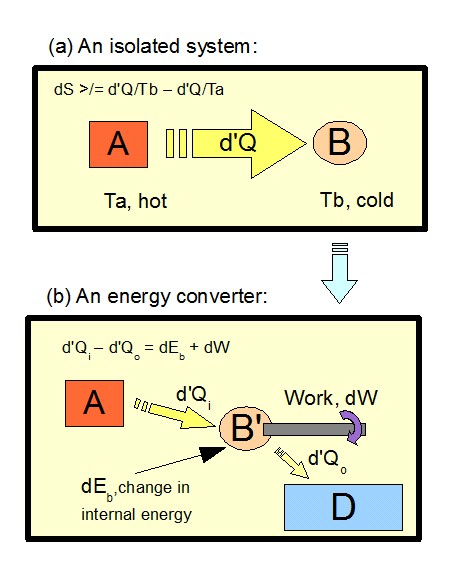
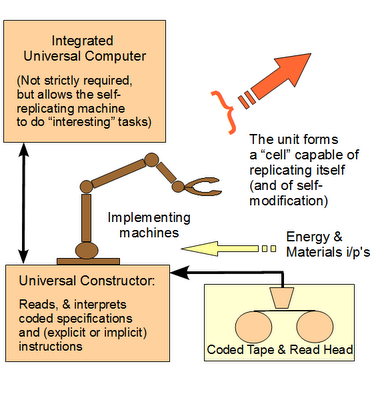
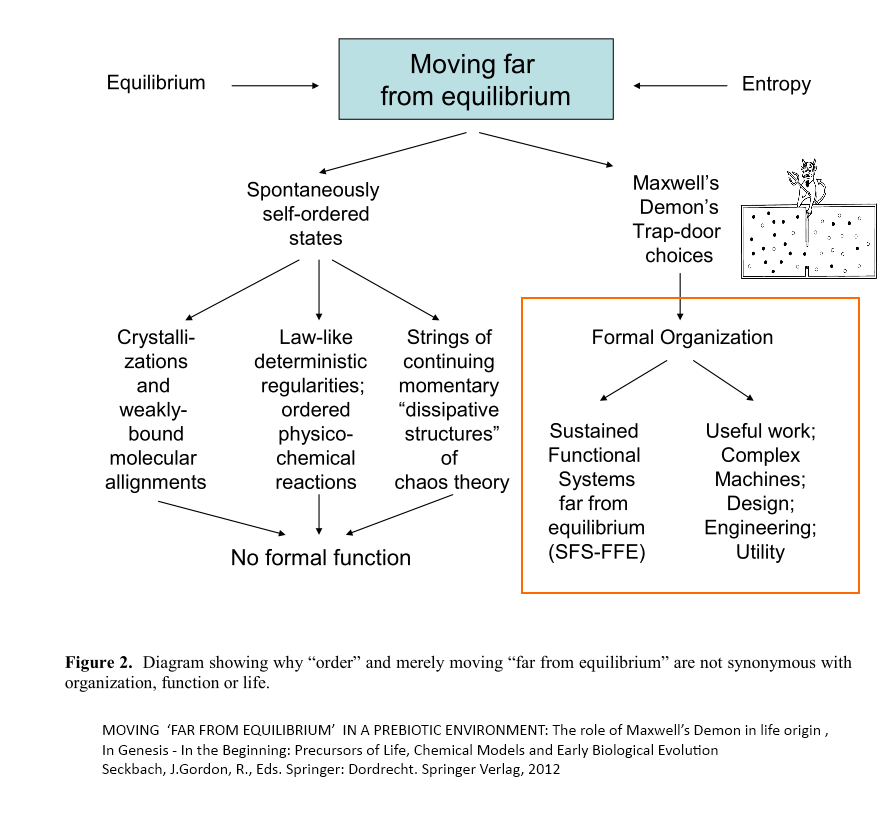

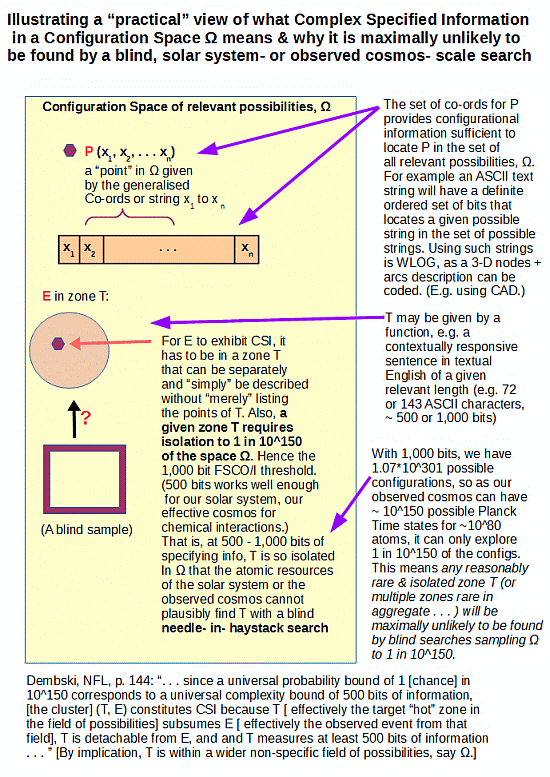
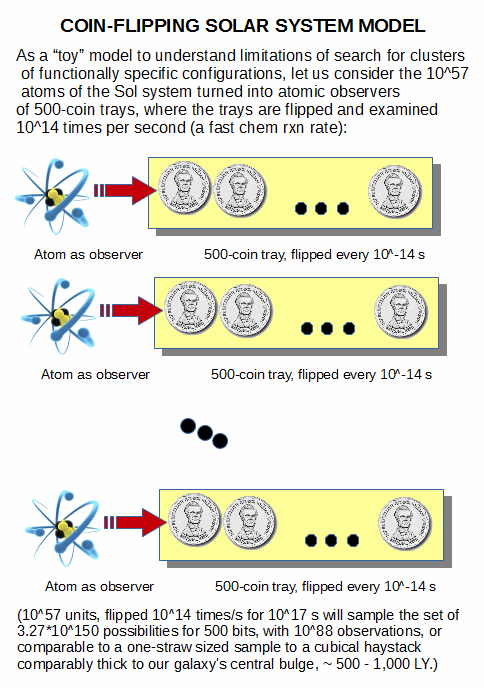
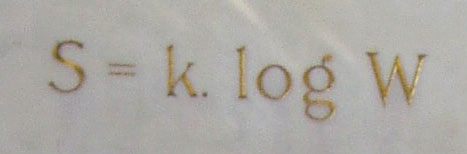
{kind=link}

