 |
In a recent post over at Panda’s Thumb, entitled, Does CSI enable us to detect Design? A reply to William Dembski (7 April 2013), Professor Joe Felsenstein, an internationally acclaimed population geneticist who is one of the more thoughtful critics of Intelligent Design, takes issue with the claim made by Professor William Dembski and Dr. Bob Marks II that Darwin’s theory of evolution by natural selection, far from solving the problem of where the complex information found in the cells of living organisms originally came from, merely pushes it further back. The thrust of Dembski and Marks’ argument is that even if we grant (for argument’s sake) that Darwinian evolution is fully capable of generating the life-forms we find on Earth today, we haven’t explained the origin of biological complexity. For it turns out that Darwinian evolution could only work in a world that had very special properties, allowing evolution to work in the first place. In a 2006 paper (The Conservation of Information: Measuring the Cost of Successful Search (version 1.1, 6 May 2006), later published in IEEE Transactions on Systems, Man and Cybernetics A, Systems & Humans, 5(5) (September 2009): 1051-1061), Professor Dembski argues that worlds like that are very rare, as they require Nature to possess certain specific properties, which we can easily imagine that Nature might have lacked. These special properties that Nature would need to possess in order for Darwinian evolution to work can themselves be viewed as a kind of information. Thus we get an information regress: Darwinian evolution has to assume the existence of information in the properties of Nature herself, in order to explain where the complex information in living creatures came from. However, this begs the question of where Nature got its information from. Only if we posit a Designing Intelligence which chose to make this universe out of a vast range of possible alternatives can we resolve the problem satisfactorily, argues Dembski. For intelligence is the only thing that is capable of creating information from scratch. In the end, we are led to posit “an ultimate intelligence that creates all information and yet is created by none,” as Dembski puts it in his 2006 paper.
Professor Felsenstein is dubious of Dembski and Marks’ claim that Darwinian evolution could only work in a very special kind of universe, but his chief objection is that “Dembski and Marks have not provided any new argument that shows that a Designer intervenes after the population starts to evolve.” As I’ll argue below, Intelligent Design advocate Professor Michael Behe discussed this objection several years ago, and responded to it in his book, The Edge of Evolution. Interestingly, ID critic Dr. Elizabeth Liddle puts forward her own model of how Intelligent Design might work without the need for intervention, in a recent post over at The Skeptical Zone, entitled, Is Darwinism a better explanation of life than Intelligent Design? (14 May 2013). Her proposal bears some resemblance to Behe’s, and what both have in common is that they allow the Designer to make a very large number of selections from among possible worlds that He/She could have created [Liddle’s Designer is of the feminine sex], but without having to make any interventions. Neither proposal is restricted to front-loading; both proposals explicitly allow the Designer of Nature to make selections that alter the course of evolution long after the first appearance of life on Earth. What’s more, both proposals envisage that these selections should be scientifically detectable, making design inferences legitimate.
What kind of information are Dembski and Marks talking about, when they claim that information is conserved?
Before we address Behe’s and Liddle’s speculative hypotheses regarding the Intelligent Designer’s M.O., or modus operandi, let’s review Dembski and Marks’ Law of the Conservation of Information, and how it points to a Designer of Nature. Dembski explains the thinking behind this law in a recent article over at Evolution News and Views entitled, Conservation of Information Made Simple (28 August 2012). First of all, the concept of information that Dembski is employing here is a very straightforward one. Information can be defined broadly as anything which assists a search to locate its target:
Conservation of information, as we use the term, applies to search. Now search may seem like a fairly restricted topic. Unlike conservation of energy, which applies at all scales and dimensions of the universe, conservation of information, in focusing on search, may seem to have only limited physical significance. But in fact, conservation of information is deeply embedded in the fabric of nature…
Search is a very general phenomenon. The reason we don’t typically think of search in broad terms applicable to nature generally is that we tend to think of it narrowly in terms of finding a particular predefined object. Thus our stock example of search is losing one’s keys, with search then being the attempt to recover them. But we can also search for things that are not pre-given in this way. Sixteenth-century explorers were looking for new, uncharted lands. They knew when they found them that their search had been successful, but they didn’t know exactly what they were looking for…
Another problem with extending search to nature in general is that we tend to think of search as confined to human contexts. Humans search for keys, and humans search for uncharted lands. But, as it turns out, nature is also quite capable of search.
(As an aside, I’d like to point out that Dembski’s “target” metaphor is similar to that used by Aquinas in his celebrated Fifth Way, where he uses the example of an arrow directed by an archer in order to illustrate how all things tend towards their respective ends.)
Why evolution itself is a search, even if it’s blind
This brings Dembski to his next point, that evolution itself can be considered as a search, even though it is commonly conceived as a blind process:
Evolution, according to some theoretical biologists, such as Stuart Kauffman, may properly be conceived as a search (see his book Investigations). Kauffman is not an ID guy, so there’s no human or human-like intelligence behind evolutionary search as far as he’s concerned. Nonetheless, for Kauffman, nature, in powering the evolutionary process, is engaged in a search through biological configuration space, searching for and finding ever-increasing orders of biological complexity and diversity…
Mathematically speaking, search always occurs against a backdrop of possibilities (the search space), with the search being for a subset within this backdrop of possibilities (known as the target). Success and failure of search are then characterized in terms of a probability distribution over this backdrop of possibilities, the probability of success increasing to the degree that the probability of locating the target increases.
 |
The generic structure of an alpha amino acid. Image courtesy of Yassine Mrabet and Wikipedia.
To illustrate his point, Dembski cites an example which should be familiar to all Uncommon Descent readers: the formation of the first proteins on Earth. Proteins are sequences of amino acids (typically, over 100) which are all L-amino acids (unlike those found in non-living things, which come in two varieties, L and D) and which are joined by chemical bonds known as peptide bonds. Only a tiny proportion of all the possible sequences of 100 amino acids that could exist, actually fold up and do a useful job. These are the ones we call proteins. Thus if Nature were capable of building a protein without any outside intervention, it would be like finding a needle in a haystack. Hence the “search” metaphor. As Dembski puts it:
For example, consider all possible L-amino acid sequences joined by peptide bonds of length 100. This we can take as our reference class or backdrop of possibilities — our search space. Within this class, consider those sequences that fold and thus might form a functioning protein. This, let us say, is the target. This target is not merely a human construct. Nature itself has identified this target as a precondition for life — no living thing that we know can exist without proteins. Moreover, this target admits some probabilistic estimates. Beginning with the work of Robert Sauer, cassette mutagenesis and other experiments of this sort performed over the last three decades suggest that the target has probability no more than 1 in 10^60 (assuming a uniform probability distribution over all amino acid sequences in the reference class).
The next concept we need to grasp, in order to grasp Dembski and Marks’ argument, is the notion of a fitness landscape – a biological term which is helpfully explained in an article entitled, Evolution 101: Fitness Landscapes, by Michigan State University postdoc student Arend Hintze and MSU graduate student Randy Olson, and posted by Dr. Danielle Whittaker on the Beacon Center blog. A fitness landscape can be understood in terms of the genotypes which comprise it. (Professor John Blamire defines a genotype as ‘the “internally coded, inheritable information” carried by all living organisms.’)
If we enumerate every possible genotype (and every genotype has its own fitness value), we can start drawing a fitness landscape, where the height of the landscape is defined by the fitness, and the place on the map is defined by the mutational distance from the original genotype…
There are peaks and valleys, and by examining this landscape you can imagine the direction a genotype may evolve. Every time the genotype mutates, it alters its location in the landscape a little, and experiences the fitness value assigned to its new genotype. The higher the fitness value, the better the genotype performs, and the more likely it will create offspring into the next generation. By continuing this process over many generations, the genotype will eventually end up on a peak in the landscape… The shape of the landscape and how far mutations can move the genotype across it will determine the evolutionary path and the final peak the genotype will end up at.
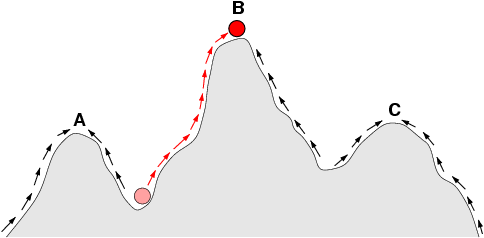 |
Sketch of a fitness landscape. The arrows indicate the preferred flow of a population on the landscape, and the points A and C are local optima. The red ball indicates a population that moves from a very low fitness value to the top of a peak. Image courtesy of Claus Wilke and Wikipedia.
In his essay, Conservation of Information Made Simple (28 August 2012), Professor Dembski quotes a passage from theoretical biologist Stuart Kauffman. Kauffman is no friend of Intelligent Design, yet he is happy to describe the process of evolution as being engaged in a search for higher and higher levels of biological complexity and diversity, as it explores a vast space of possible configurations. Unlike Darwinian biologists, however, Kauffman is prepared to acknowledge that there is a problem with the claim that the Darwinian mechanism of random variation culled by natural selection is capable of generating new biological information. As he puts it in his Investigations (Oxford University Press, 2000, p. 19):
If mutation, recombination, and selection only work well on certain kinds of fitness landscapes, yet most organisms are sexual, and hence use recombination, and all organisms use mutation as a search mechanism, where did these well-wrought fitness landscapes come from, such that evolution manages to produce the fancy stuff around us?
In other words, Kauffman recognizes that Darwinian evolution can only work in special kinds of fitness landscapes. Dembski uses this insight of Kauffman’s to illustrate his point (which has been rigorously proved in his and Marks’ paper on the Law of the Conservation of Information), that any information we see coming out of the evolutionary process must have already been contained in the “fitness landscape” in which evolution occurs.
 |
Bulgarian Orthodox Easter eggs. Image courtesy of Ikonact and Wikipedia.
An Easter Egg hunt provides a useful analogy that helps us understand why evolution cannot hit targets such as functional proteins, or complex life-forms, simply by following a blind search. Some sort of “guided search” is required, but the information that guides the search still has to come from somewhere:
Take an Easter egg hunt in which there’s just one egg carefully hidden somewhere in a vast area. This is the target and blind search is highly unlikely to find it precisely because the search space is so vast…
The Easter egg hunt example provides a little preview of conservation of information. Blind search, if the search space is too large and the number of Easter eggs is too small, is highly unlikely to successfully locate the eggs. A guided search, in which the seeker is given feedback about his search by being told when he’s closer or farther from the egg, by contrast, promises to dramatically raise the probability of success of the search. The seeker is being given vital information bearing on the success of the search. But where did this information that gauges proximity of seeker to egg come from? Conservation of information claims that this information is itself as difficult to find as locating the egg by blind search, implying that the guided search is no better at finding the eggs than blind search once this information must be accounted for…
Most biological configuration spaces are so large and the targets they present are so small that blind search (which ultimately, on materialist principles, reduces to the jostling of life’s molecular constituents through forces of attraction and repulsion) is highly unlikely to succeed. As a consequence, some alternative search is required if the target is to stand a reasonable chance of being located. Evolutionary processes driven by natural selection constitute such an alternative search. Yes, they do a much better job than blind search. But at a cost — an informational cost, a cost these processes have to pay but which they are incapable of earning on their own…
[C]onservation of information says that increasing the probability of successful search requires additional informational resources that, once the cost of locating them is factored in, do nothing to make the original search easier…
The reason it’s called “conservation” of information is that the best we can do is break even, rendering the search no more difficult than before.
The thrust of Dembski’s argument should by now be clear. Let’s imagine (for argument’s sake) that there’s an evolutionary process that leads from a simple cell to the dazzling variety of life-forms that we find on Earth today, via a series of small transitional steps. What the law of conservation of information tells us is that increasing the likelihood that this evolutionary process will succeed in reaching its various targets, can only be achieved by reducing the likelihood of evolution’s being able to occur in the first place. In other words, the more successful we make Darwinian evolution, the less antecedently likely we render it:
…[D]esign proponents have argued that even if common ancestry holds, the evidence of intelligence in biology is compelling. Conservation of information is part of that second-prong challenge to evolution. Evolutionary theorists like Miller and Dawkins think that if they can break down the problem of evolving a complex biological system into a sequence of baby-steps, each of which is manageable by blind search (e.g., point mutations of DNA) and each of which confers a functional advantage, then the evidence of design vanishes. But it doesn’t. Regardless of the evolutionary story told, conservation of information shows that the information in the final product had to be there from the start.
It would actually be quite a remarkable property of nature if fitness across biological configuration space were so distributed that advantages could be cumulated gradually by a Darwinian process. Frankly, I don’t see the evidence for this… The usual response to my skepticism is, Give evolution more time. I’m happy to do that, but even if time allows evolution to proceed much more impressively, the challenge that conservation of information puts to evolution remains.
If biological evolution proceeds by a gradual accrual of functional advantages, instead of finding itself deadlocked on isolated islands of function surrounded by vast seas of non-function, then the fitness landscape over biological configuration space has to be very special indeed (recall Stuart Kauffman’s comments to that effect earlier in this piece). Conservation of information goes further and says that any information we see coming out of the evolutionary process was already there in this fitness landscape or in some other aspect of the environment or was inserted by an intervening intelligence. What conservation of information guarantees did not happen is that the evolutionary process created this information from scratch.
In this passage, Dembski describes the Intelligent Designer as “intervening” and as having “inserted” information into the fitness landscape, but as I’ll argue below, Behe and Liddle both show that there is no need to envisage an actual insertion of information; a selection made by the Designer, outside space and time, would do the trick equally well.
In any event, the key point that Dembski makes in the foregoing passage is that when it comes to the biological information we find in the genomes of living things, you can’t get something from nothing. Information doesn’t create itself.
Citing the work of Simon Conway Morris, a Christian evolutionary biologist who maintains that the information which guides the evolutionary process is embedded in Nature, Dembski goes on to argue that the very metaphors invoked by Morris to describe the manner in which this information is stored in Nature point to Nature’s having been designed. Even if we grant that evolution is capable of “climbing Mount Improbable” (to use a phrase popularized by Professor Richard Dawkins, the world’s best-known contemporary atheist), it is still a very remarkable
fact (unexplained by Darwinism) that evolution possesses the tools required to get it to the top of the mountain and generate such a variety of complex life-forms:
If evolution is so tightly constrained and the Darwinian mechanism of natural selection is just that, a mechanism, albeit one that “navigates immense hyperspaces of biological alternatives” by confining itself to “thin roads of evolution defining a deeper biological structure,” then, in the language of conservation of information, the conditions that allow evolution to act effectively in producing the complexity and diversity of life is but a tiny subset, and therefore a small-probability target, among all the conditions under which evolution might act. And how did nature find just those conditions? Nature has, in that case, embedded in it not just a generic evolutionary process employing selection, replication, and mutation, but one that is precisely tuned to produce the exquisite adaptations, or, dare I say, designs, that pervade biology…
…This is the relevance of conservation of information for evolution: it shows that the vast improbabilities that evolution is supposed to mitigate in fact never do get mitigated. Yes, you can reach the top of Mount Improbable, but the tools that enable you to find a gradual ascent up the mountain are as improbably acquired as simply scaling it in one fell swoop. This is the lesson of conservation of information.
At the conclusion of his 2012 essay, Conservation of Information Made Simple, Professor Dembski addresses the question of where the information we find in the fundamental properties of Nature ultimately comes from: an Intelligent Designer Who was not designed by anyone else.
One final question remains, namely, what is the source of information in nature that allows targets to be successfully searched? If blind material forces can only redistribute existing information, then where does the information that allows for successful search, whether in biological evolution or in evolutionary computing or in cosmological fine-tuning or wherever, come from in the first place? The answer will by now be obvious: from intelligence. On materialist principles, intelligence is not real but an epiphenomenon of underlying material processes. But if intelligence is real and has real causal powers, it can do more than merely redistribute information — it can also create it.
Indeed, that is the defining property of intelligence, its ability to create information, especially information that finds needles in haystacks.
Professor Felsenstein’s beef with Dembski and Marks’ Law of the Conservation of Information
Felsenstein writes:
I think that ordinary physics, with its weakness of long-range interactions, predicts smoother-than-random fitness surfaces. But whether I am right about that or not, Dembski and Marks have not provided any new argument that shows that a Designer intervenes after the population starts to evolve. In their scheme, ordinary mutation and natural selection can bring about the adaptation. Far from reformulating the Design Inference, they have pushed it back to the formation of the universe.
I’d like to make a brief comment here on Felsenstein’s critique of Dembski’s claim that evolution only works in a very unusual fitness landscape. The basis for this claim is a mathematical one: the Law of the Conservation of Information, which Dembski established by a process of rigorous logical argumentation, in his paper with Marks. Since there has been no credible critique of the mathematical reasoning contained in this paper since its publication, I shall take it that the result stands. Consequently, if Felsenstein wants to argue that evolution would work in a much larger proportion of fitness landscapes than Dembski claims, then he should do one of two things: either critique Dembski and Mark’s mathematical argument for the Law of the Conservation of Information (LCI), or attempt to argue that it doesn’t apply to evolution. Felsenstein does neither. Instead, Felsenstein puts forward an argument that evolution isn’t sensitive to tiny changes in the fitness landscape (as Dembski maintains it is), based on an appeal to “ordinary physics”, which is simply irrelevant to the case in question. If LCI is true, and if it applies to biological evolution, then evolution must be a fine-tuned process. it’s as simple as that.
The other part of Felsenstein’s critique relates to the modus operamdi of the Intelligent Designer: Felsenstein thinks that Dembski and Marks need to show that the Designer intervenes after the population starts to evolve, but what they’ve shown instead is that He fine-tunes the universe at the very moment of its formation. In other words, the Designer doesn’t intervene in the history of the universe; He just winds it up, like a cosmic clockmaker. At best, contends Felsenstein, that’s an argument for Deism.
The persistence of the fitness landscape over time is a fact which needs to be explained
 |
A cul-de-sac in Sacramento, California. Image courtesy of The Mentalist, LeaW, Indolences and Wikipedia.
What Professor Felsenstein is implicitly assuming in his critique is that the fitness landscape, with its smooth surfaces that permit incremental Darwinian evolution to occur, persists over the course of time. But why should it? The Earth has been through several major cataclysms since its formation: huge meteorite impacts which destroyed nearly all living creatures; having its entire surface frozen for tens (and possibly hundreds) of millions of years (according to some geologists); mass extinctions caused by a sudden soaring of global temperatures; and the sudden release of oxygen into the atmosphere, which proved toxic for many anaerobic organisms on the early Earth, to name just a few. Throughout all these upheavals, we are supposed to believe that the fitness landscape that makes gradualistic Darwinian evolution possible maintained its smooth contours, making incremental improvements possible. But that, in itself, is a huge assumption. Who is to say that a fitness landscape, once set up, requires no further maintenance, other than the continued survival of life on Earth? For instance, what’s to prevent radical environmental changes from pushing all terrestrial organisms into an evolutionary cul-de-sac, where no major improvements are possible, even over the course of billions of years? And why couldn’t that have happened on the early Earth?
If the maintenance of a fitness landscape which permits the evolution of complex organisms over the course of time is not a foregone conclusion, then we can no longer rule out an ongoing role for the Designer simply by appealing to the efficacy of “ordinary mutation and natural selection” to bring about adaptations, as Felsenstein contends. Rather, we need a Designer Who can guarantee at every stage of the development of life on Earth that the path leading to sentient and sapient beings remains open.
Behe and Liddle on the possibility of design without intervention
 |
Balls breaking in a game of pool. Image courtesy of No-w-ay, H. Caps and Wikipedia.
In his book, The Edge of Evolution (The Free Press, 2007), Professor Michael Behe writes:
How was the design of life accomplished? That’s a peculiarly contentious question. Some people (officially including the National Academy of Sciences) are willing to allow that the laws of nature may have been purposely fine-tuned for life by an intelligent agent, but they balk at considering further fine-tuning after the Big Bang because they would fret it would require ‘interference’ in the operation of nature. So they permit a designer just one shot, at the beginning – after that, hands off. For example, in The Plausibility of Life Marc Kirschner and John Gerhart hopefully quote a passage from an old article on evolution in the 1909 Catholic Encyclopedia: ‘God is the Creator of heaven and earth. If God produced the universe by a single creative act of His will, then its natural development by laws implanted in it by the Creator is to the greater glory of His Divine power and wisdom.’
This line of thinking is known as ‘Theistic Evolution’. But its followers are just kidding themselves if they think it is compatible with Darwinism. First, to the extent that anyone – either God, … or ‘any being. . . external to our universe responsible for selecting its properties’ – set nature up in any way to ensure a particular outcome, then to that extent, although there may be evolution, there is no Darwinism. Darwin’s main contribution to science was to posit a mechanism for the unfolding of life that required no input from any intelligence – random variation and natural selection. If laws were ‘implanted’ into nature with the express knowledge that they would lead to intelligent life, then even if the results follow by ‘natural development,’ nonetheless, intelligent life is not a random result (although randomness may be responsible for other, unintended features of nature). Even if all the pool balls on the table followed natural laws after the cue struck the first ball, the final result of all the balls in the side pocket was not random. It was intended [via the specific arrangement of the balls on the pool table before the shot was made].
Second, ‘laws’, understood as simple rules that describe how matter interacts (such as Newton’s law of gravity), cannot do anything by themselves. For anything to be done, specific substances must act. If our universe contained no matter, even the most finely tuned laws would be unable to produce life, because there would be nothing to follow the laws. Matter has unique characteristics, such as how much, where it is, and how it’s moving. In the absence of specific arrangements of matter, general laws account for little.
Finally, a particular, complex outcome cannot be ensured without a high degree of specification. At the risk of overusing the analogy, one can’t ensure that all the pool balls will end up in the side pocket just by specifying simple laws of physics, or even simple laws plus, say, the size of the pool table. Using the same simple laws, almost all arrangements of balls and almost all cue shots would not lead to the intended result. Much more has to be set. And to ensure a livable planet that actually harbors life, much more has to be specified than just the bare laws of physics. (2007, pp. 229-230)
Behe then proceeds to address a “theological” objection to Intelligent Design on the part of some religious believers:
Some people who accept design design arguments for physics, but not for biology, nurture an aesthetic preference that our universe should be self-contained, with no exceptions to physical laws after its inception. The prospect of the active, continuing involvement of the designer rubs them the wrong way. They picture something like a big hand flinging a Mars-sized orb at the nascent earth [in order to generate the moon – VJT], or pushing molecules around, and it offends their sensibilities. (2007, p. 230)
 |
An artistic depiction of the multiverse. Image courtesy of Silver Spoon and Wikipedia.
In order to assuage the concerns of these religious believers that belief in Intelligent Design commits us to a demeaning view of the Designer, Behe then provides what he describes as a “cartoon example” of how an Intelligent Being with a perfect understanding of physics (or an uberphysicist, as Behe calls Him) might design the evolution of life down to the last detail, without having to intervene in the history of the cosmos. At the beginning, Behe envisages that the uberphysicist has “a huge warehouse in which is stored a colossal number of little shiny spheres,” where “[e]ach sphere encloses the complete history of a separate, self–contained, possible universe, waiting to be activated.” Behe explains that “the warehouse can be considered a vast multiverse of possible universes, but none of them have yet been made real.” Most of these possible universes will be inhospitable to life, but a tiny proportion will be life-friendly:
One enormous section of the warehouse contains all the universes that, if activated, would fail to produce life. They would develop into universes consisting of just one big black hole, universes without stars, universes without atoms, or other abysmal failures. In a small wing of the huge warehouse are stored possible universes that have the right general laws and constants of nature for life. Almost all of them, however, fall into the category of “close, but no cigar.” For example, in one possible universe the Mars–sized body would hit the nascent earth at the wrong angle and life would never commence. In one small room of the small wing are those universes that would develop life. Almost all of them, however, would not develop intelligent life. In one small closet of the small room of the small wing are placed possible universes that would actually develop intelligent life. (2007, p. 231)
From among the (relatively few) life-friendly universes, Behe’s uberphysicist then makes a selection: He brings one of them into being, in a single creative act, thereby setting in motion the entire course of evolution, culminating in the appearance of intelligent human beings. The mutations that occur during the evolution of life may appear random, but in fact, they were deliberately selected by Behe’s uberphysicist. Behe argues that this selection amounts to an act of design, without the need for any interference.
One afternoon the uberphysicist walks from his lab to the warehouse, passes by the huge collection of possible dead universes, strolls into the small wing, over to the small room, opens the small closet, and selects on the extremely rare universes that is set up to lead to intelligent life. Then he “adds water” to activate it. In that case the now–active universe is fine–tuned to the very great degree of detail required, yet it is activated in a “single creative act.” All that’s required for the example to work is that some possible universe could follow the intended path without further prodding, and that the uberphysicist select it. After the first decisive moment the carefully chosen universe undergoes “natural development by laws implanted in it.” In that universe, life evolves by common descent and a long series of mutations, but many aren’t random. There are myriad Powerball–winning events, but they aren’t due to chance. They were foreseen, and chosen from all the possible universes.
Certainly that implies impressive power in the uberphysicist. But a being who can fine–tune the laws and constants of nature is immensely powerful. If the universe is purposely set up to produce intelligent life, I see no principled distinction between fine–tuning only its physics or, if necessary, fine–tuning whatever else is required. In either case the designer took all necessary steps to ensure life.
Those who worry about ‘interference’ should relax. The purposeful design of life to any degree is easily compatible with the idea that, after its initiation, the universe unfolded exclusively by the intended playing out of the natural laws. (2007, pp. 229-230, 231-232)
In her post, Is Darwinism a better explanation of life than Intelligent Design? (14 May 2013), Elizabeth Liddle puts forward a similar theory, although it is somewhat less detailed than Behe’s:
Here’s an ID theory that any IDist who likes it is welcome to:
Let’s say that a Designer (and I’m going to assume a divine designer, because, as Dembski says, any material designer just moves the problem back a notch, as it would itself require a designer) wanted to create a universe in which life would appear. This designer knows that of the trillions of possible universes, only one will unfold according to the Divine Plan and bring forth life and human beings, and yet such beings are her Divine Purpose.
And so she causes to exist just that one in a trillion universe, in which each event unfolds as she intends. From within the universe, all we observe are natural causes, which, nonetheless, against all apparent odds, happen to result in us. And so the only way of inferring the Designer is to apprehend just how many possible universes might have been created, and how few of those would have resulted in us.
Nothing has occurred that is not possible given the rules we infer about this universe. But the probability that of all possible events, the ones that lead to intelligent life are those that occurred is infinitesimal, unless we posit that we were intended – that of all hypothetical universes in the Divine Mind, the one she chose to actuate was the one that would lead to us.
We will find nothing but apparently fortuitous chemistry in the formation of novel proteins – but such unlikely chemistry that trillions of alternative chemical reactions must have been considered and rejected as being not on the path to us.
There. I think I’ve presented myself with a more convincing ID argument than any I’ve read so far.
UPDATE: Proteins would be a search target, too
 |
The protein hexokinase, with much smaller molecules of ATP and the simplest sugar, glucose, shown in the top right corner for comparison. Image courtesy of Tim Vickers and Wikipedia..
In my recent post, The Edge of Evolution?, I drew readers’ attention to the work of Dr. Branko Kozulic, who, in his paper, Proteins and Genes, Singletons and Species, points out that there are literally hundreds of chemically unique proteins in each and every species of living organism. These “singleton” proteins have no close chemical relatives, making their origin a baffling mystery. Dr. Kozulic contends that the presence of not one but hundreds of chemically unique proteins in each species is an event beyond the reach of chance, and that each species must therefore be the result of intelligent planning. In his paper, Kozulic listed various estimates of how much fine-tuning there is in a single protein molecule. Only a tiny proportion of all possible amino acid sequences is capable of folding and functioning as a protein within a cell. And remember, each species has hundreds of chemically unique proteins (called singletons):
While scientists generally agree that only a minority of all possible protein sequences has the property to fold and create a stable 3D structure, the figure adequate to quantify that minority has been a subject of much debate. (p. 6)
In 1976, Hubert Yockey estimated the probability of about 10^-65 [that’s 1 in 100,000 million million million million million million million million million million – VJT] for finding one cytochrome c sequence among random protein sequences [48]. For bacteriophage λ[lambda] repressor, Reidhaar-Olson and Sauer estimated that the probability was about 10^-63 [49]. Based on β[beta]-lactamase mutation data, Douglas Axe estimated the prevalence of functional folds to be in the range of 10^-77 to 10^-53 [50]. A comparison of these estimates with those concerning the total number of protein molecules synthesized during Earth’s history – about 10^40 [9, 51, 52] – leads to the conclusion that random assembling of amino acids could not have produced a single enzyme during 4.5 billion years [48, 53]. On the other hand, Taylor et al. estimated that a random protein library of about 10^24 members would be sufficient for finding one chorismate mutase molecule [54]…
Let us assess the highest probability for finding this correct order by random trials and call it, to stay in line with Crick’s term, a “macromolecular miracle”. The experimental data of Keefe and Szostak indicate – if one disregards the above described reservations – that one from a set of 10^11 randomly assembled polypeptides can be functional in vitro, whereas the data of Silverman et al. [57] show that of the 10^10 in vitro functional proteins just one may function properly in vivo. The combination of these two figures then defines a “macromolecular miracle” as a probability of one against 10^21. For simplicity, let us round this figure to one against 10^20. (pp. 6-7, p. 8)
The frequency of functional proteins among random sequences is at most one in 10^20 (see above). The proteins of unrelated sequences are as different as the proteins of random sequences [22, 81, 82] – and singletons per definition are exactly such unrelated proteins. (p. 11)
The presence of a large number of unique genes in each species represents a new biological reality. Moreover, the singletons as a group appear to be the most distinctive constituent of all individuals of one species, because that group of singletons is lacking in all individuals of all other species. (p. 18)
Dr. Kozulic argues that there simply isn’t enough time available during the Earth’s history, for literally hundreds of new, singleton proteins to have originated through the processes of random and natural selection. Thus the appearance of hundreds of new proteins in each and every new species means that there is plenty of room for conscious selection by an Intelligent Designer, in the unfolding of the cosmos!
Is this the clockwork universe by another name?
 |
Tim Wetherell’s Clockwork Universe sculpture at Questacon, Canberra, Australia (2009). Image courtesy of OpheliaO and Wikipedia.
It is important to note here that neither Behe nor Liddle envisages a deterministic universe: both of them posit scenarios in which mutations occur. To a naive onlooker, these mutations might appear random, but in fact, the outcome of these mutations has been carefully planned by the Designer. In other words, we are not dealing with a front-loading scenario here, in which the outcome of each and every mutation could (in principle) be predicted from a knowledge of the laws and initial conditions of the cosmos. Rather, what Behe and Liddle envisage is a Designer who selects not only the laws and initial conditions of the cosmos, but also the outcomes of indeterministic events, such as mutations.
This is an important point, as physicist Dr. Robert Sheldon has argued in a highly persuasive article entitled, The Front-Loading Fiction (July 2, 2009) that front-loading wouldn’t work. The clockwork universe of Laplacean determinism, which endeavors to specify all future outcomes simply by selecting the laws and initial conditions of the cosmos, won’t work because in a quantum universe like ours, “no amount of precision can control the outcome far in the future,” as “[t]he exponential nature of the precision required to predetermine the outcome exceeds the information storage of the medium.” Nor will it do to suppose that the universe unfolded according to a cosmic computer program, since “Turing’s proof of the indeterminacy of feedback; the inability to keep data and code separate as required for Turing-determinacy; and the inexplicable existence of biological fractals within a Turing-determined system” would all render the outcome of any such program inherently unpredictable. In fact, the only kind of universe that could be pre-programmed to produce specific results without fail and without the need for any further input, would be one without any kind of feedback, real-world contingency or fractals – and hence, one devoid of organic life.
For his part, Sheldon envisages an incessantly active “hands-on” Deity, Who continually maintains the universe at every possible scale of time and space, in order that it can support life. That’s perfectly fine by me. But what Behe’s and Liddle’s thought experiments show is that a Deity can be actively involved in the history of life, without necessarily being an interventionist. All the Deity needs to do is select a cosmos with the history He intends, from among countless alternative possible universes.
Would design detection be possible in a non-interventionist universe?
Dr. Liddle, in her thought experiment, makes it quite clear that a Deity’s acts of design could still be detected in the “non-interventionist” cosmos which she envisages. Design could be inferred from the extreme rarity of possible universes that lead to intelligent life:
From within the universe, all we observe are natural causes, which, nonetheless, against all apparent odds, happen to result in us. And so the only way of inferring the Designer is to apprehend just how many possible universes might have been created, and how few of those would have resulted in us.
We will find nothing but apparently fortuitous chemistry in the formation of novel proteins – but such unlikely chemistry that trillions of alternative chemical reactions must have been considered and rejected as being not on the path to us.
This kind of reasoning accords very well with the design inferences that Intelligent Design theorists make by invoking Professor Dembski’s “design filter” – not that I would accuse Dr. Liddle of being an Intelligent Design theorist for one moment, of course! Nevertheless, the scenario she proposes should allay any concerns that people living in a cosmos that was not subject to acts of Divine intervention could never infer the existence of a Designer.
Would a designed universe satisfy the requirements of quantum randomness?
Professor Felsenstein may be inclined to object that the non-random outcomes in the universe selected by Behe’s (or Liddle’s) Deity are at odds with the inherent randomness of quantum physics. In response, I would argue that an act of selection by an Intelligent Designer need not violate quantum randomness, because a selection can be random at the micro level, but non-random at the macro level. The following two rows of digits will serve to illustrate my point.
1 0 0 0 1 1 1 1 0 0 0 1 0 1 0 0 1 1
0 0 1 0 0 0 0 1 1 0 1 1 0 1 1 1 0 1
The above two rows of digits were created by a random number generator. Now suppose I impose the macro requirement: keep the columns whose sum equals 1, and discard the rest. I now have:
1 0 1 1 1 0 0 0 0 0 1
0 1 0 0 0 1 1 0 1 1 0
Each row is still random, but I have imposed a non-random macro-level constraint. Likewise, when the Designer makes a choice of which world to create from among various possible worlds, there is no violation of quantum randomness at the microscopic level.
Could the foregoing scenario actually be true? A philosophical evaluation
It seems to me that the question of whether the scenario proposed by Behe and Liddle is viable or not ultimately hinges on the philosophical question of whether this universe would still be the same individual universe, if its history were different. Philosophers often like to talk about possible universes (although many of them prefer to speak instead of “possible worlds”, which is a somewhat broader term). Disagreement exists as to whether these possible worlds are concrete or merely abstract. But the question of how these worlds should be individuated is a vexed one. It makes sense to say that this world could have been different from the way it is; consequently, not every feature of this world can be essential to it. The question then boils down to this: which features of the cosmos we live in are part-and-parcel of its individual identity?
If we accept that “pure randomness” (i.e. events which “just happen”, without being either causally determined or selected by an intelligent agent) is philosophically impossible, then that seems to entail that there can be no universe whose micro- or macro-level outcomes are not fully specified in some fashion. That, in turn, would seem to imply that when God selects a particular universe to create, God must select one whose history is specified too – at least, up until the arrival of intelligent beings like ourselves, who are capable of making additional specifications by their acts of free choice.
At any rate, we are now in a position to respond to Professor Felsenstein’s objection to the Law of the Conservation of Information, that “Dembski and Marks have not provided any new argument that shows that a Designer intervenes after the population starts to evolve.” As we have seen, no intervention is necessary; a Designer Who is outside time and space could select the entire course of evolution, without needing to intervene even once, if He so wished.
Felsenstein objects that Dembski and Marks’ Law of the Conservation of Information would make evolution a foregone conclusion, from the moment of creation:
In their scheme, ordinary mutation and natural selection can bring about the adaptation. Far from reformulating the Design Inference, they have pushed it back to the formation of the universe.
But this objection presupposes that mutations occur deterministically. If mutations are indeterministic on the physical level, then there is nothing, in the absence of a Designer, which guarantees that the course of evolution will proceed as it does. A universe with the same laws and initial conditions as ours might still remain lifeless, even after 14 billion years, if “random” events happen to go the wrong way for the development of life. Hence the need for selection covering every stage of the history of the universe, on the Designer’s part.
I also argued above that the persistence of the evolutionary “fitness landscape” over the course of time is a highly remarkable fact, which needs to be explained. We are very fortunate that evolution did not get stuck in a cul-de-sac, at a time when the only organisms on Earth were one-celled bacteria. If that had happened, we would not be here today. The fact that we live on a planet where mutations lead to increasing diversity and complexity, over billions of years, requires an explanation, and the only satisfactory one is: design.
To sum up: Felsenstein’s contention that the Law of Conservation pushes the Designer to the very periphery of the picture turns out to be mistaken, and his assumption that design requires intervention rests on a misunderstanding of Intelligent Design theory. It is to be hoped that he will reconsider his views. I’d also like to thank Professor Behe and Dr. Liddle for having demonstrated that belief in an active Designer does not necessarily entail belief in an interventionist Designer.
Let me close with a quote from St. Augustine (The City of God v, 11):
“Not only heaven and earth, not only man and angel, even the bowels of the lowest animal, even the wing of the bird, the flower of the plant, the leaf of the tree, hath God endowed with every fitting detail of their nature.”