For some time now, objector DiEb has been raising the question, what do we mean by speaking of “search” in the context of evolutionary search. At 311 in the parody thread, she [IIRC] remarks:
>>Search is a central term in the work of Dr. Dr. William Dembski jr, Dr. Winston Ewert, and Dr. Robert Marks II (DEM): it appears in the title of a couple of papers written by at least two of the authors, and it is mentioned hundreds of times in their textbook “Introduction to Evolutionary Informatics“. Strangely – and in difference from the other central term information, it is not defined in this textbook, and neither is search problem or search algorithm. Luckily, dozens of examples of searches are given. I took a closer look to find out what DEM see as the search problem in the “Introduction to Evolutionary Informatics” and how their model differs from those used by other mathematicians and scientists.
I have responded yet again to the basic conceptual point (regardless of debate points re Marks, Dembski et al) to draw out why search challenge is a pivotal concern in the discussion of the design inference, based on the issue of large configuration spaces and islands of function, similar to Abel’s discussion of a decade or so ago in the peer-reviewed literature on the universal PLAUSIBILITY metric, principle and bound. I therefore consider it worth the while to headline as follows:
KF, 338: >>Several times, you have raised the issue of search. I have pointed out that at base, it is tantamount to sampling from a configuration space.
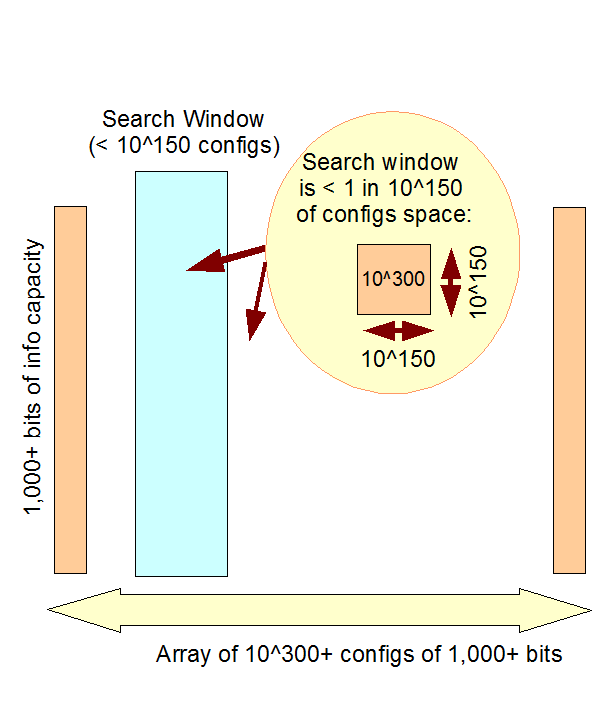
[As, algebraic representation is commonly desired (and is often deemed superior to illustration or verbal description), a traditional representation of such a space is to symbolise it as Omega, here we can use w. Search then is obviously — and the obviousness is a material point here — tantamount to taking a subset of cases k in w by whatever relevant means, blind or intelligent. Thesearch challenge then is to find some relevant zone z in w such that a performance based on configuration rises above a floor deemed non-functional: find/happen upon some z_i in w such that p(z) GT/eq f_min. Zones z are islands of function in the configuration space, w.]
[Let’s add a cluster of UD infographics over the years:]
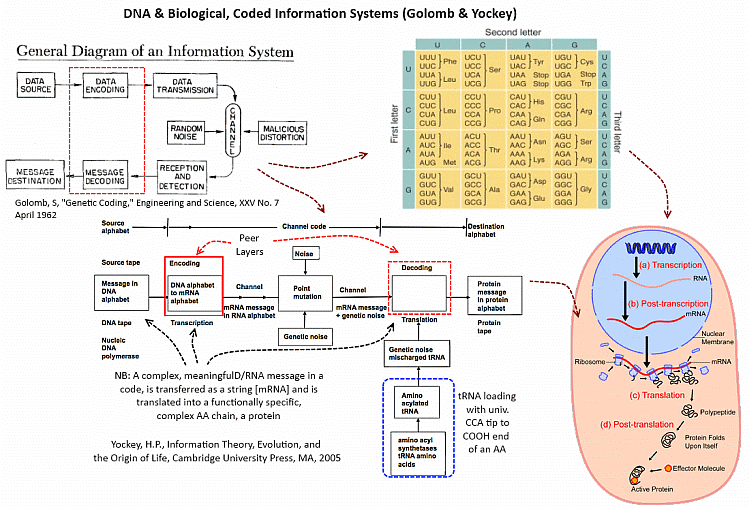
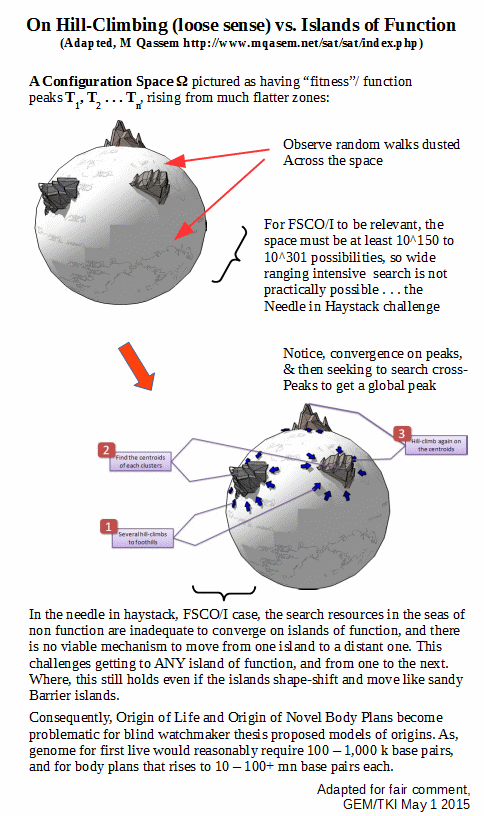
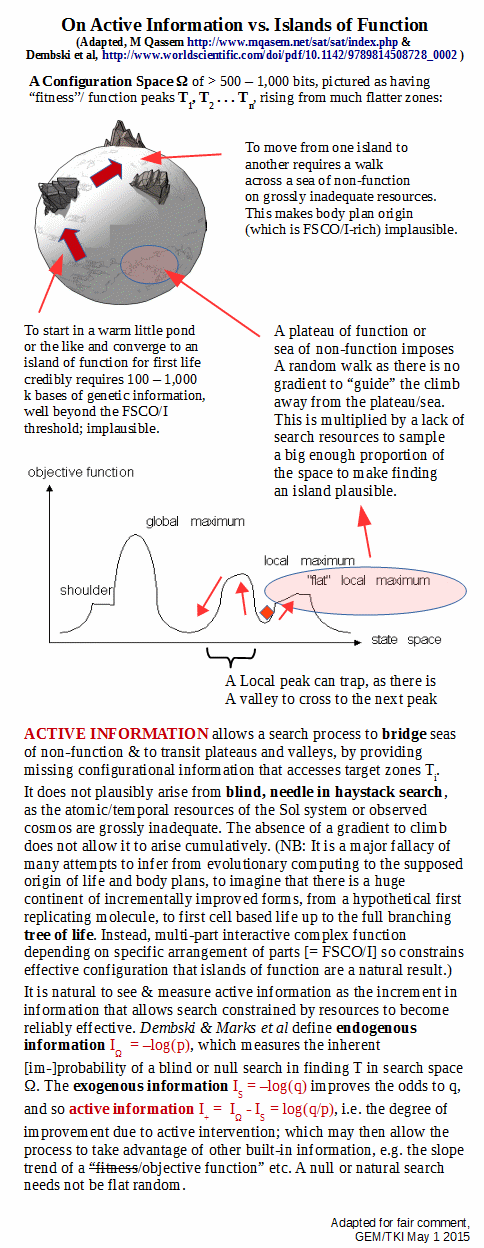
An illustration of islands of organised function, per Trevors and AbelThe 1,000 bit observed cosmos complexity threshold i/l/o the Planck-time search window of 10^150 possibilitiesFSCO/I as exemplified through coded text (paralleling punched paper tape and D/RNA strands), where per AutoCAD etc, any 3-D entity representing a functionally organised system can be reduced to strings in a description language so discussion on strings is WLOGThe D/RNA code in action, considered as an alphanumeric code with associated information-based cybernetic system
In the sense, blind search, by chance and/or mechanical necessity without intelligent direction or control or guidance or influence generally. This is directly relevant to the challenge of “finding” — strictly, happening upon the shorelines of — deeply isolated islands of function in config spaces of 500 – 1,000 bits or more of complexity. In these cases,
a: the atomic resources of the sol system or observed cosmos [10^57 to 10^80 atoms, more or less]
b: treated as observers each sampling at fast chemical reaction rates [~10^14 samples or observations/sec]
c: for 10^17 s (order of time since the typical projection to the singularity) will be
__________________________________
d: utterly overwhelmed by the scope of search to plausibly sample enough of the space to credibly hit one or more shorelines of function.
This does not require any detailed probability assessment, but indicates that by many orders of magnitude the challenge overwhelms the search resources.
As a direct result, blind search is not a plausible means of discovering zones exhibiting functionally specific complex organisation and/or associated information [FSCO/I] in sufficiently complex configuration spaces.
Where, per search samples the space, it is a subset, so the set of possible searches is comparable to the power set. If the direct set is of magnitude n, the set of searches is comparable in magnitude to 2^n. Thus, search for a golden search is plausibly exponentially harder than direct search.
Of course, typical discussions of fitness landscapes are about incremental hill-climbing within islands of function. They thus beg the question of arriving at shorelines of function. Where also, deep isolation is a direct result of FSCO/I requiring multiple, well matched components properly arranged and coupled to produce relevant results.
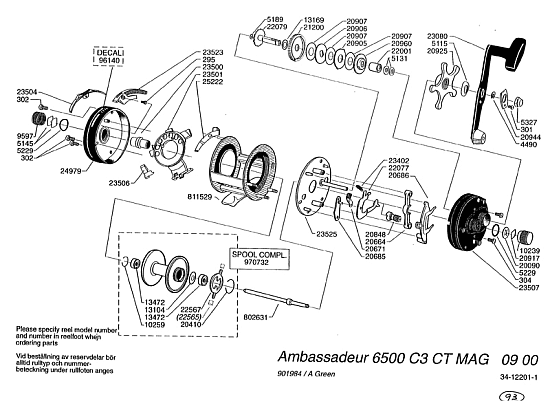
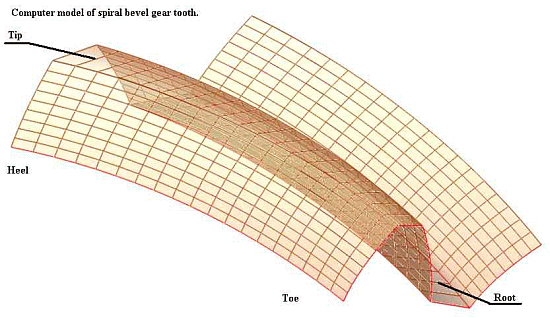
A 6500 C3 reel exploded diagram, illustrating the role of multiple, correctly aligned, oriented and coupled parts to achieve coherent function based on specific, information-rich organisationA computer model of spiral bevel gear teeth, showing how precise configuration of parts of a whole is an inherent part of coherent, information-rich functionally specific organisation
And as a consequence of OOL requiring credibly 100k – 1,000 k bases and body plans 10 – 100 millions, we are well beyond the FSCO/I threshold in these cases.
So, it is not plausible that the FSCO/I seen in life forms at origin or at basic body plan level, originated by blind search.
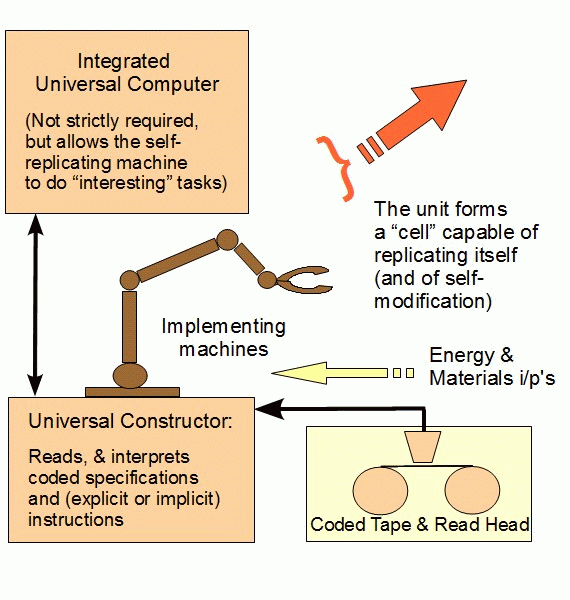
Pausing, it is worth noting that the proposal that ability to reproduce leading to descent with incremental modification solves the problem typically overlooks that at OOL, there is need to account for the FSCO/I of the von Neumann kinematic self-replicator found in the living cell.
Likewise, that for body plan origins, many co-ordinated changes (often, involving reproduction) will have to be accounted for. Natural selection of reproducing entities does not evade the origin of FSCO/I challenge.
What, per Newton’s vera causa principle, has right to be regarded as an observed effective cause of FSCO/I? Intelligently directed configuration, aka design.
Indeed, we are well within our inductive logic, epistemic rights, to hold that FSCO/I is a well tested, highly reliable sign of design as materially relevant cause. On a trillion member observation base.>>
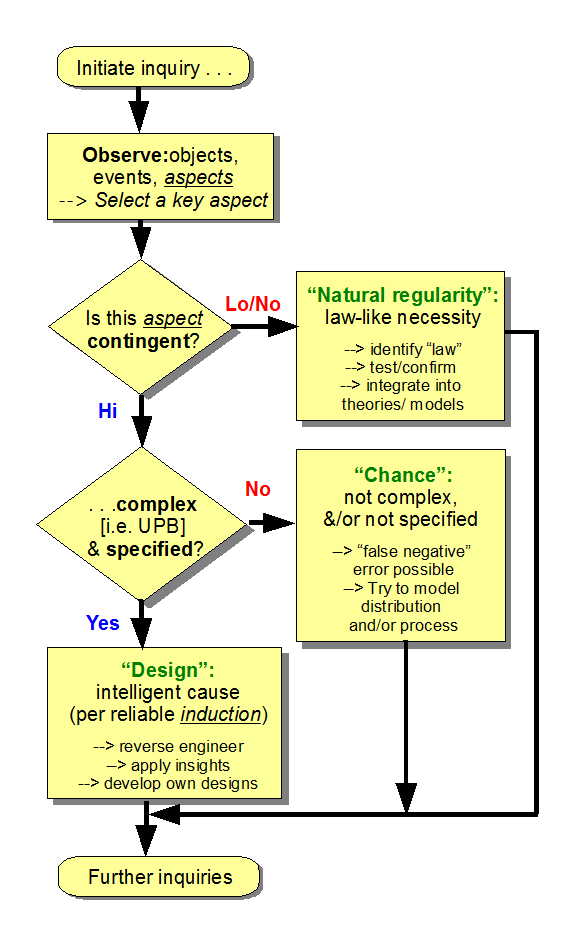
Consequently, we have a reasonable and robust baseline understanding of search and of search challenge that then drives reflection on the inductive logic, empirically justified design inference explanatory filter, here seen in the per aspect in succession form:
Explanatory FilterThus, the design inference is an empirically grounded, robust framework for exploring origin of FSCO/I. And, it is testable by the simple means of identifying observed cases of origin of FSCO/I rich entities and evaluating whether blind search credibly and reliably causes FSCO/I. To date, on a trillion member observation base, no. END
F/N: Note this from Wiki on searches of a state space:
State space search is a process used in the field of computer science, including artificial intelligence (AI), in which successive configurations or states of an instance are considered, with the intention of finding a goal state with a desired property.
Problems are often modelled as a state space, a set of states that a problem can be in. The set of states forms a graph where two states are connected if there is an operation that can be performed to transform the first state into the second.
State space search often differs from traditional computer science search methods because the state space is implicit: the typical state space graph is much too large to generate and store in memory. Instead, nodes are generated as they are explored, and typically discarded thereafter. A solution to a combinatorial search instance may consist of the goal state itself, or of a path from some initial state to the goal state.
Representation
In state space search a state space is formally represented as a tuple
S: LT S,A,Action(s),Result(s,a),Cost(s,a)GT S: LT S, A, Action(s), Result(s,a), Cost(s,a)>, in which:
S is the set of all possible states;
A is the set of possible action, not related to a particular state but regarding all the state space;
Action(s) is the function that establish which action is possible to perform in a certain state;
Result(s,a) is the function that return the state reached performing action a in state s s
Cost(s,a) is the cost of performing an action a in state s. In many state spaces [cost] is a constant, but this is not true in general.
Examples of State-space search algorithms
Uninformed Search
According to Poole and Mackworth, the following are uninformed state-space search methods, meaning that they do not know information about the goal's location.[1]
Depth-first search
Breadth-first search
Lowest-cost-first search
Informed Search
Some algorithms take into account information about the goal node's location in the form of a heuristic function[2]. Poole and Mackworth cite the following examples as informed search algorithms:
Heuristic depth-first search
Greedy best-first search
A* search
Muy interesante, no?
KF
PS: Cf my remarks above:
Several times, you have raised the issue of search [ –> as in, in recent exchanges at UD]. I have pointed out that at base, it is tantamount to sampling from a configuration space.
[As, algebraic representation is commonly desired (and is often deemed superior to illustration or verbal description), a traditional representation of such a space is to symbolise it as Omega, here we can use w. Search then is obviously — and the obviousness is a material point here — tantamount to taking a subset of cases k in w by whatever relevant means, blind or intelligent. The search challenge then is to find some relevant zone z in w such that a performance based on configuration rises above a floor deemed non-functional: find/happen upon some z_i in w such that p(z) GT/eq f_min. Zones z are islands of function in the configuration space, w.]
kairosfocus
January 31, 2018
January
01
Jan
31
31
2018
10:28 AM
10
10
28
AM
PDT
DiEb (and Bob O’H):
I would like to remind here that functional specification, as I define it, is fully objective.
Indeed, a conscious agent is required to define the function, but once an explicit definition has been given, all the rest if completely objective.
And, as any function can be defined, without limitations*, there is no subjective ambiguity in the definition of functional information: it is the minimal information needed to implement some explicitly defined function.
With that definition, if it is possible to objectively define a function for an object which requires a minimum amount of specific information to be implemented (above an appropriate threshold for the system), whatever the function is, then we can infer design for that object.
It's as simple as that. And completely objective.
*Important note: the only limitation is that we must not use any knowledge of the specific bits of information in the object to create an "ad hoc" function. That would be, of course, cheating.gpuccio
January 31, 2018
January
01
Jan
31
31
2018
05:07 AM
5
05
07
AM
PDT
DiEb:
Again, your mathematical arguments are interesting, but how would you describe mathematically the scenario I proposed at #19?
Which is IMO the only one really pertinent for biological problems.
And would you try to answer my challenge from a mathematical point of view?gpuccio
January 31, 2018
January
01
Jan
31
31
2018
04:58 AM
4
04
58
AM
PDT
DiEb, All I needed to do was to point out that search as sampling from a configuration space with in effect implied observation of performance of the configuration [think, does this chemistry or mutation "work" and can it metabolise and reproduce] is enough and is generally consistent with the concepts put on the table a decade ago; which is what ET asked about in effect. Further to this, "decoupling" sounds suspiciously like an insistence on imposing a general hill-climbing pattern so that there is trend information available everywhere. Such cannot be justified as the evidence is that FSCO/I comes in deeply isolated islands of function in vast configuration spaces dominated by non-functional gibberish. I repeat, the search-challenge is to find shorelines of initial adequate, reproducing function on islands of function that are deeply isolated in config spaces that overwhelm available search resources. As I warned already, that is enough and there is no reason to imagine that delving on personalities or real or imagined peculiarities will enlighten rather than cloud the core issue. As at this point, it looks strongly to me like you have already had the dismissive conclusion in hand and are looking for some excuse to rationalise it by finding whatever points you can find to object to in details of a particular proposal by those whose general views you hold in contempt. I am therefore drawing attention to the elephant in the middle of the room: search challenge due to the issue of the search capability in the face of a needle in haystack challenge. In that context, it is highly interesting to note that at each point where I have actually answered main questions, you have then proceeded to further objections, often in loaded terms. That unresponsiveness to pointing out what a blind search would be and why it is relevant i/l/o search challenge, what the search problem is and what a search algorithm would be, tells me that such are only gambits on a rhetorical game that is increasingly familiar. On fair comment, I have to point out that the real issue you have is obviously not the points you presented as the thin edge of an axe. I therefore point to the central issue, to the now clearly brushed aside answers, and the onward play-out of agendas that do not contribute to the substantial issue. That issue is that the blind watchmaker type thesis has no empirically or analytically credible account for the origin of the coherent, complex functionally specific organisation and information in cell based life and in body plans onward. While, intelligent design routinely produces FSCO/I. KFkairosfocus
January 31, 2018
January
01
Jan
31
31
2018
01:07 AM
1
01
07
AM
PDT
KF @22:
1) A closer inspection of the erratum would reveal that I'm well aware of this article.
2) The decoupling of the function f and the target T shows itself in the representation of a query: as f is the same for all targets, a query can be represented by a sequence (q_1, q_2,...) of elements of $Omega$, you do not need a sequence of pairs ([q_1,f(q_1)], [q_2,f(q_2)],....)
3) This was the first attempt to represent searches as measures - in this case on the space of queries of length Q. Turns out that this did not work, as Q is not a measurable space in the way they intended it to be. That is why DEM looked at other representations in their later work.
4) Here is a short current discussion on some aspects of the paper - turns out that you can find obvious errors even in the eights year of its publication!DiEb
January 30, 2018
January
01
Jan
30
30
2018
10:12 PM
10
10
12
PM
PDT
ET, the successful configs have not yet been instantiated, but are possible. The point is, what is the plausibility of achieving successful configurations for biological life in Darwin's pond or the like by blind needle in haystack chance plus mechanical necessity search/sampling? Then, of doing much the same with novel body plans. Once we see the pattern of deeply isolated islands of function (as a consequence of multiple well matched correctly organised and coupled parts) and the degree of complexity thus scope of the config space the answer is, not plausible. Of course intelligently directed configuration routinely produces such FSCO/I. So, the committed activist faces the task of locking out the obvious answer while minimising the blatant implausibility. That's why we see the rhetorical patterns we so often see. KFkairosfocus
January 30, 2018
January
01
Jan
30
30
2018
03:54 PM
3
03
54
PM
PDT
The search analogy doesn't work with evolution by means of blind and mindless processes. There isn't any target or needle to search for. Whatever structure you think is being searched for doesn't yet exist and has to be invented. And it allegedly gets invented by just-so happenstance changes that just happen to accumulate in such a way as to invent them.
Stuff happens. The stuff that doesn't get eliminated gets to accumulate. And sometimes the right stuff just happens to accumulate in just the right way and that which wasn't being searched for, is found. :cool:
Now model that in a way relevant to biology.ET
January 30, 2018
January
01
Jan
30
30
2018
03:43 PM
3
03
43
PM
PDT
BTW, did Bob O'H accept gpuccio's invitation to join the spliceosome discussion?Dionisio
January 30, 2018
January
01
Jan
30
30
2018
03:14 PM
3
03
14
PM
PDT
ET, the issue is not hard particularly to figure out, especially from the way specifics have been put down and then we see anything but that the focus of onward attention. That searches of a config spaces select samples is patent. That we are looking at the challenge of getting FSCO/I in large spaces through blind watchmaker approaches is obvious. That the search problem is whether the search challenge has been/ credibly can be so surmounted, is a corollary, and the answer is well known. As for what an algorithm is, that is trivial. KF
PS: Lets try the search for search paper, http://evoinfo.org/papers/2010_TheSearchForASearch.pdf :
>> The Search for a Search: Measuring the Information Cost of Higher Level Search
William A. Dembski and Robert J. Marks II
Journal of Advanced Computational Intelligence and Intelligent Informatics, Vol.14, No.5, 2010, pp. 475-486
Cite as:
William A. Dembski and Robert J. Marks II, "The Search for a Search: Measuring the Information Cost of Higher Level Search," Journal of Advanced Computational Intelligence and Intelligent Informatics, Vol.14, No.5, 2010, pp. 475-486.
Abstract
Needle-in-the-haystack problems look for small targets in large spaces. In such cases, blind search stands no hope of success. Conservation of information dictates any search technique will work, on average, as well as blind search. Success requires an assisted search. But whence the assistance required for a search to be successful? To pose the question this way suggests that successful searches do not emerge spontaneously but need themselves to be discovered via a search. The question then naturally arises whether such a higher-level “search for a search” is any easier than the original search. We prove two results: (1) The Horizontal No Free Lunch Theorem, which shows that average relative performance of searches never exceeds unassisted or blind searches, and (2) The Vertical No Free Lunch Theorem, which shows that the difficulty of searching for a successful search increases exponentially with respect to the minimum allowable active information being sought.
1. Introduction
Conservation of information theorems [1–3], especially
the No Free Lunch Theorems (NFLT’s) [4–8], show that
without prior information about a search environment or
the target sought, one search strategy is, on average, as
good as any other [9]. This is the result of the Horizontal
NFLT presented in Section 3.2.
A search’s difficulty can be measured by its endoge-
nous information [1, 10–14] defined as
I_w = ? log_2 p ............. (1)
where p is the probability of a success from a random
query [1]. When there is knowledge about the target lo-
cation or search space structure, the degree to which the
search is improved is determined by the resulting
active information[1, 10–14]. Even moderately sized searches
are virtually certain to fail in the absence of knowledge
about the target location or the search space structure.
Knowledge concerning membership of the search prob-lem in a structured class [15], for example, can constitute
search space structure information [16].
Endogenous and active information together allow for
a precise characterization of the conservation of
informa-tion. The average active information, or
active entropy,of an unassisted search is zero when no assumption is made concerning the search target. If any assumption is made concerning the target, the active entropy becomes negative. This is the Horizontal NFLT presented in Sec-tion 3.2. It states that an arbitrary search space structure will, on average, result in a worse search than assuming nothing and simply performing an unassisted search.
>>
It is not hard to see from this clip that the basic frame of thought I presented above, starting in the OP is accurate and could have been reasonably understood from what has long since been on record in the peer-reviewed literature published by the Evo Informatics Lab.
Searches are queries of a config space of possibilities and return a performance value that can be null or can give enough to feed hill climbing and reaching a limit up to some attractor zone or point. Thus, they are based on samples of the config space.
The relevant challenge is needle in haystack searches that attack spaces that blind random samples on atomic and temporal resources of the sol system or the observed cosmos will be maximally unlikely to find deeply isolated islands of function. Intelligent design routinely solves such.
That takes care of the alleged tremendous, unanswered issue of search problem. Search algorithms are obvious once one knows what an algorithm is. The only real problem is to halt, which may have to be forced.kairosfocus
January 30, 2018
January
01
Jan
30
30
2018
03:09 PM
3
03
09
PM
PDT
@19 gpuccio has provided a nice opportunity for DiEb and Bob O'H to shine.
Let's hope they won't miss it.Dionisio
January 30, 2018
January
01
Jan
30
30
2018
03:00 PM
3
03
00
PM
PDT
Perhaps kairosfocus could just send an email to the Discovery Institute via "Evolution News and Views" and ask them. I am sure they would answer someone who helps run a pro-ID blog.
Does Denyse have ties to the DI? Maybe she could coax Winston to stop by UD.ET
January 30, 2018
January
01
Jan
30
30
2018
02:36 PM
2
02
36
PM
PDT
DiEb (and Bob O'H):
I have read your piece at TSK with interest, but as I told you previously I cannot enter the mathematical details of the problem.
I already gave you a personal definition of search which IMO is more than enough for a biological view of ID, and I think it could be probably shared by most of us in the ID field. I repeat it here, for convenience:
For my purposes, the only important concept is to define some system where probabilistic events happen (in our case, some biological system on our planet, where RV happens in already existing organisms), and where, in a specified time window, some new specific configuration arises in the existing genomes.
Of course, the new configuration has some level of functional information in itself, which can be measured (usually indirectly) in reference to some well defined function (usually the function biologically observed).
In this context, we can say that a “search” in the probabilistic system “generated” that amount of functional information.
Of course, it is not really a search, just some sequence of random events that brings about, in something that could be well described as a random walk, the observed result.
In this sense, we can try to evaluate:
a) The set of all possible configurations that can arise in the system (the search space).
b) The subset of the specific configurations that can implement the observed function (the target space).
c) The functional information linked to the observed function (-log2 (b/a))
d) The probabilistic resources of the system (the total number of different configurations that can be reached in the system in the defined time span).
e) Comparing c) and d) we can derive the probability of the observed event in the system by RV alone.
Of course, many of these steps require approximations, as in all empirical science.
Now, while I still would not comment about the differences between you and Dembski and others, I would like to comment briefly on one of your statements, that I find interesting, and I hope so to also answer some of the points made here by Bob O'H, always according to my point of view. You say:
That is the great difference between the problems which all other scientists discuss and the ones of DEM: DEM have decoupled the optimum of the function and the target, arriving quite another version of a search problem:
And you also make an interesting "example":
In this spirit I would like to invent a dialogue between God and Darwin’s Bulldog:
Bulldog: “The horse is a marvellous creature: fully adapted to its niche, really, survival of the fittest at play”
God: “Oh no, that one is a total disaster – it may function better than any other creature in its environment, but I was aiming for pink unicorns”
Well, this is interesting. What could it mean, in the light of biological ID?
The point is, IMO, that in natural history we continuosly see pink unicorns appearing, where the search described by the official theory (RV + NS) can only find, not so much horses, but probably only small round stones to be used as tentative wheels, or even less.
I will be more clear. Let's stick to a kind of "search" that is well documented in biology (maybe the only one that is well documented):
a) The appearance of a simple function ot the simple optimization of an existing function by RV + NS under extremely strong selective pressure.
I have discussed that in great detail here:
https://uncommondescent.com/intelligent-design/what-are-the-limits-of-natural-selection-an-interesting-open-discussion-with-gordon-davisson/
Simple penicillin resistance is an example. I have discussed it at comment #303 in that thread. I quote here some conclusions:
"a) One single point mutation can confer some resistance to penicillin, probably altering the affinity between the PBP anf the antibiotic.
b) Other (few) point mutations can increase the resistance."
Another example is chloroquine resistance. Here, two specific random mutations are necessary for the function to appear, and it can then be optimized by about three other single mutations. I have discussed that scenario in the same thread, at comment #311.
Now, these are two examples where the RV + NS algorithm works. One of the reasons is that the search function (which could be considered the fitness function, resistance to penicillin) is not decoupled from the target that is found. Resistance to penicillin defines the fitness function, and resistance to penicillin is the target found by the search.
Of course, other conditions must be present:
a1) The initial step (1 mutation for penicillin resistance, 2 mutations for chloroquine resistance) must be simple, because it must be found by a purely random search: it happens before the appearance of the function.
a2) The following optimization steps must be simple too: each single new mutation increases the function, and is therefore selectable.
a3) The selective pressure is very strong.
OK, that is clear enough.
But now, let's consider the appearance, in natural history, of some new complex molecular system. We can consider a couple of examples that I have discussed in detail.
One could be ATP synthase, which appears almost at OOL.
The other could be the spliceosome system in eukaryotes.
Now, while each of those two systems is very complex, we will focus for the moment on two components for each of them:
b1) The alpha and beta chains in the F1 subunit of ATP synthase, which I have discussed many times.
b2) The Prp8 and Brr2 proteins in the U5 subunit of the spliceosome, which I have discussed in the OP here:
https://uncommondescent.com/intelligent-design/the-spliceosome-a-molecular-machine-that-defies-any-non-design-explanation/
and additionally in comment #357 there.
Now, my point is that these are pink unicorns.
And they are targets that in some way have been found.
But there is no reasonable search function "f" which could find them. Any function f must be related to the search space and to the target. But the fitness functions in a realistic scenario must be related to the appearance and/or optimization of some function, and the function must work on reasonably simple steps which can be provided by the random component of the search.
But here we are in front of extremely long and complex proteins, hundreds or thousands of AAs, and each of those proteins is extremely functionally constrained, as proved by their evolutionary conservation, and each of them is part of a much more complex system which implements a very specific function: generating ATP from proton gradients, and splicing spliceosomal introns.
So, the simple point is: any search function f, here, is necessarily decoupled from the complex final function which could become a functional target only at the very end of a complex search.
So we have:
1) Functionally complex targets which, in some way, have been found.
2) Search functions which cannot find them, because they are not coupled in any way to the target in the search space.
That's a scenario which requires design to be explained.
I hope I have been clear enough. I would really appreciate some comment on this aspect from you (DiEb and Bob O'H).
Anticipating some of the possible objections, I will repeat here a challenge that I have offered many times in the last few months, but that nobody, at present, has even tried to answer. Here it is, again:
Will anyone on the other side answer the following two simple questions?
1) Is there any conceptual reason why we should believe that complex protein functions can be deconstructed into simpler, naturally selectable steps? That such a ladder exists, in general, or even in specific cases?
2) Is there any evidence from facts that supports the hypothesis that complex protein functions can be deconstructed into simpler, naturally selectable steps? That such a ladder exists, in general, or even in specific cases?
gpuccio
January 30, 2018
January
01
Jan
30
30
2018
01:46 PM
1
01
46
PM
PDT
DiEb, First and foremost, what search is, as was also what you raised several previous times and were answered in-thread in those discussions. The key difference is, I headlined it this time. So far as I can see, as I elaborated at first level in answer to insistence, I drew out the corollaries on "search problem" and "search algorithm." Once search is seen i/l/o the search challenge and the background debates starting with Weasel etc, those are corollaries. Assuming that one knows what an algorithm is. Notice, that I point out that termination may have to be forced. KFkairosfocus
January 30, 2018
January
01
Jan
30
30
2018
10:48 AM
10
10
48
AM
PDT
KF @16:
DiEb,
you have suggested that the approach to search used is inappropriate, here are your actual words used at UD that I am responding to:
Search is a central term in the work of Dr. Dr. William Dembski jr, Dr. Winston Ewert, and Dr. Robert Marks II (DEM) . . . Strangely – and in difference from the other central term information, it is not defined in this textbook, and neither is search problem or search algorithm.
That is, your actual complaint presented to us here at UD is about definition, and crucially about definition of search. So, a response to such is obviously relevant to what you raised here.
KF on the top of this page:
For some time now, objector DiEb has been raising the question, what do we mean by speaking of “search” in the context of evolutionary search. At 311 in the parody thread, she [IIRC] remarks:
>>Search is a central term in the work of Dr. Dr. William Dembski jr, Dr. Winston Ewert, and Dr. Robert Marks II (DEM): it appears in the title of a couple of papers written by at least two of the authors, and it is mentioned hundreds of times in their textbook “Introduction to Evolutionary Informatics“. Strangely – and in difference from the other central term information, it is not defined in this textbook, and neither is search problem or search algorithm. Luckily, dozens of examples of searches are given. I took a closer look to find out what DEM see as the search problem in the “Introduction to Evolutionary Informatics” and how their model differs from those used by other mathematicians and scientists.
http://theskepticalzone.com/wp/the-search-problem-of-william-dembski-winston-ewert-and-robert-marks/ >>
Highlighting mine. So, what was I looking at specifically? Can you spot it?DiEb
January 30, 2018
January
01
Jan
30
30
2018
09:17 AM
9
09
17
AM
PDT
DiEb,
you have suggested that the approach to search used is inappropriate, here are your actual words used at UD that I am responding to:
Search is a central term in the work of Dr. Dr. William Dembski jr, Dr. Winston Ewert, and Dr. Robert Marks II (DEM) . . . Strangely – and in difference from the other central term information, it is not defined in this textbook, and neither is search problem or search algorithm.
That is, your actual complaint presented to us here at UD is about definition, and crucially about definition of search. So, a response to such is obviously relevant to what you raised here.
I have pointed out that it is both well warranted and relevant to discuss search in general terms as sampling from a configuration space, with some index of interest being relevant though not necessarily a target. That is, the issue is that evolutionary development of successful configurations is being claimed. This starts with alleged chemical evolution to arrive at an original self-replicating and metabolising life form, and then onwards of body plans. Both by blind non purposive means. In recent decades Weasel and kin are very relevant cases.
Forgive me the terrible error of actually responding to what you explicitly asked about.
As it is relevant at least to the onlooker present and future, let me again cite my definition, which I believe will be relevant also to the sort of exercises that the Evolutionary Informatics Lab has undertaken over the years, based on recall of their work as I have looked at it:
Several times, you have raised the issue of search [ --> as in, in recent exchanges at UD]. I have pointed out that at base, it is tantamount to sampling from a configuration space.
[As, algebraic representation is commonly desired (and is often deemed superior to illustration or verbal description), a traditional representation of such a space is to symbolise it as Omega, here we can use w. Search then is obviously — and the obviousness is a material point here — tantamount to taking a subset of cases k in w by whatever relevant means, blind or intelligent. The search challenge then is to find some relevant zone z in w such that a performance based on configuration rises above a floor deemed non-functional: find/happen upon some z_i in w such that p(z) GT/eq f_min. Zones z are islands of function in the configuration space, w.]
In that context, the search problem is to solve the search challenge as identified, especially for large configuration spaces that exceed 10^150 - 10^300 possibilities, i.e. for 500 - 1,000 bits as a threshold. The answer to which is, that there is no credible solution by blind chance and/or mechanical necessity within the scope of the sol system to the observed cosmos. I add: intelligently directed configuration, using insight, routinely solves this problem, e.g. posts pro and con in this thread. The observed base of cases exceeds a trillion.
A search algorithm can be identified as attacking the search problem i/l/o the relevant possible searches, modulo the issue that there may be a need to intervene and impose a computational halt as some searches may run without limit if simply left to their inherent dynamics. Where, an algorithm is generally understood to be a finite, stepwise computational process that starts with a given initial point and proceeds to provide a result that is intended by its creator. This obtains for computation, which may model the real world situation which is dynamical rather than algorithmic.
I would consider that, given the context, search problems and algorithms are relatively trivial to understand, once search has been adequately conceptualised.
Beyond a certain point, on fair comment, all of this begins to look like an attempt to suggest the ignorant, stupid, insane or wicked accusation against design thinkers, by way of making mountains out of mole-hills.
May I suggest that if you had looked in Dembski's longstanding NFL, you would have found on pp 148, 144 and 149:
p. 148:“The great myth of contemporary evolutionary biology is that the information needed to explain complex biological structures can be purchased without intelligence. [--> that is, that blind search can and does readily arrive at FSCO/I] My aim throughout this book is to dispel that myth . . . . Eigen and his colleagues must have something else in mind besides information simpliciter when they describe the origin of information as the central problem of biology.
I submit that what they have in mind is specified complexity [ --> he goes to a generic form, of which the biologically relevant subset is functionally specific and complex as he develops in outline on p. 149], or what equivalently we have been calling in this Chapter Complex Specified information or CSI . . . .
Biological specification always refers to function. [--> see?] An organism is a functional system comprising many functional subsystems. . . . In virtue of their function [a living organism's subsystems] embody patterns that are objectively given and can be identified independently of the systems that embody them. Hence these systems are specified in the sense required by the complexity-specificity criterion . . . the specification can be cashed out in any number of ways [through observing the requisites of functional organisation within the cell, or in organs and tissues or at the level of the organism as a whole. [Dembski cites:]
Wouters, p. 148: "globally in terms of the viability of whole organisms,"
Behe, p. 148: "minimal function of biochemical systems,"
Dawkins, pp. 148 - 9: "Complicated things have some quality, specifiable in advance, that is highly unlikely to have been acquired by ran-| dom chance alone. In the case of living things, the quality that is specified in advance is . . . the ability to propagate genes in reproduction."
On p. 149, he roughly cites Orgel's famous remark from 1973, which exactly cited reads:
In brief, living organisms are distinguished by their specified complexity. Crystals are usually taken as the prototypes of simple well-specified structures, because they consist of a very large number of identical molecules packed together in a uniform way. Lumps of granite or random mixtures of polymers are examples of structures that are complex but not specified. The crystals fail to qualify as living because they lack complexity; the mixtures of polymers fail to qualify because they lack specificity . . .
And, p. 149, he highlights Paul Davis in The Fifth Miracle: "Living organisms are mysterious not for their complexity per se, but for their tightly specified complexity."] . . .”
p. 144: [Specified complexity can be more formally defined:] “. . . since a universal probability bound of 1 [chance] in 10^150 corresponds to a universal complexity bound of 500 bits of information, [the cluster] (T, E) constitutes CSI because T [effectively the target hot zone in the field of possibilities --> note, in such a zone, hill climbing is an onward consideration as are attractors etc as I discussed] subsumes E [ effectively the observed event from that field], T is detachable from E, and and T measures at least 500 bits of information [--> I extend to 500 - 1,000] . . . ”
I trust that this will suffice to see what he was addressing, why -- and why it made a lot of sense.
The point is, search can be understood as described and on this we see the search challenge problem which grounds the design inference on FSCO/I as tested, reliable sign.
Side tracks, personalities and peculiarities do not change that.
And, so far as what was presented to us at UD, the definition was what was asked for. it has been provided and shown to be relevant, on fair comment, you have no just cause for complaint.
KFkairosfocus
January 30, 2018
January
01
Jan
30
30
2018
08:50 AM
8
08
50
AM
PDT
that DEM seem to allow the target of the search and the fitness function to be totally unrelated.
Why would they have to be for the concept to be relevant and true?
You want to find something. It could be archaeological such as how a particular long-vanished culture treated dogs. It could be how to fix an obsolete VCR that you will never use once it's fixed. It could be how to advance a level in a video game.
You will use a methodology which in a large degree is based on the purposeful rejection of improbabilities and impossibilities to achieve your end but the only goal would be to satisfy curiosity or to fight boredom. No real fitness function.
What you would accept though is that the end has been achieved via design and randomness would not be involved.tribune7
January 30, 2018
January
01
Jan
30
30
2018
07:20 AM
7
07
20
AM
PDT
KF:
My article was an exercise on "peculiarities and personalities":
1) I wrote an article about a very specific problem I find in the work of some of the most preeminent thinkers of Intelligent Design, and I highlighted that problem using one specific work - their book "Introduction to Evolutionary Informatics". You may have seen news stories about this book here on Uncommon Descent.
2) The specific problem is the definition of "search problem" (not of "search"!) - that's why the article is named The Search Problem of William Dembski, Winston Ewert, and Robert Marks
And now, when I ask you how your post addresses the peculiar problem in the work of three prominent personalities, you are starting to complain?
BTW: an - admittedly unflattering - summary of your comments could be: "Let's not talk about other personalities, let's just talk about me". You should work on that.DiEb
January 30, 2018
January
01
Jan
30
30
2018
07:05 AM
7
07
05
AM
PDT
BO'H: If you find that the heart of the matter is irrelevant or round about in a context where you have been involved on this issue for many years that speaks; and, sadly. Surely, it is highly relevant to see that search can be understood as relating to samples from a config space and that in the context of systems of relevance, origin of FSCO/I by blind search is the heart of the matter at stake. Where, in answer to your:
once the search is “in” the target, it stops, as it has reached the optimum
. . . the fact that hill-climbing on reaching a shoreline of function is relevant and the possibilities of non-point attractors up to and including strange attractors is also relevant (thus we can have cycles); so, stopping search on reaching function is not relevant, is a material point. I also note that if something inherently changes stochastically, it may go through quasi-periodic or even aperiodic cycling in response to perturbations, even around a trend. A classic case in point is of course the GDP vs time trend for a given economy. KFkairosfocus
January 30, 2018
January
01
Jan
30
30
2018
06:21 AM
6
06
21
AM
PDT
DiEb, really! I pointed out that there is a focal issue to be addressed rather than allow ourselves to be distracted by peculiarities and personalities. I spoke to that focal issue, what search is -- you asserted no [credible?] definition has been offered -- and then showed how this leads right to the heart of the matter, tying it to the OOL and OO body plans, then the problem of origin of functionally specific complex organisation and associated information, which is the core matter at stake on matters of design inference relevant to the world of life. I then went on to tie the matter to the applicability of the design inference explanatory filter heuristic. You now try to dismiss me as in effect riding a hobby-horse as though the issues I highlighted are not the heart of the matter. That's not acceptable. Please, do better than this, you are a lot better than the sadly typical run of trolls we so often see at or around UD. KFkairosfocus
January 30, 2018
January
01
Jan
30
30
2018
06:15 AM
6
06
15
AM
PDT
kf - sorry to hear about the power cut. I think I'm going to duck out of this discussion, as it's going to take too long for me to work out if you have addressed my points: your response is rather verbose, and extremely indirect.Bob O'H
January 30, 2018
January
01
Jan
30
30
2018
06:14 AM
6
06
14
AM
PDT
@KF:
DiEb, you will know well enough that my focus has always been the grounding of the design inference i/l/o needle in haystack search challenge in large configuration spaces, not the particularities and peculiarities that objectors may or may not find in the works of given personalities.
KF, I got distracted by the title of your post - I thought that "Answering DiEb" would imply that you indeed tried to answer to the points I was making, and not come up with your favorite topics.
Why did you quote me in the title if this post is only about your focus?DiEb
January 30, 2018
January
01
Jan
30
30
2018
06:05 AM
6
06
05
AM
PDT
BO'H (attn DiEb):
The problem of impersonal, non-purposeful search in a space of possibilities was not put on the table by design thinkers but by the evolutionists.
And you will doubtless recall the problems with the Weasel case where there was an implied target and thus we saw later search simulations that were allegedly without explicit or implicit targets.
The obvious context is statistical thermodynamics, and concepts such as ensembles of possible unfoldings of a large collection of entities at similar initial start points. A configuration space is a cut-down phase space and moving from state to state of an entity can be tracked by the path taken in the configuration space; where WLOG discussion can be entertained on strings of alphanumerical characters capable of various states. Accordingly, I have pointed to the problem of needle in haystack blind search as purposeless blind walk, where to get to ool one has to deal with the purposelessness of chemistry, thermodynamics and physics in Darwin's pond or the like. Then to move from one main body plan to another one has to cross intervening seas of non-function with the same challenge of vastly inadequate search resources.
So, sorry, I have no intent of revisiting the peculiarities of the past 20+ years of debates.
A simple generalised search that can address random non-foresighted walks, randomness-influenced trajectories, hill climbing and the like without needing to refer to targets is what is on the table. Search in general, for relevant purposes, is sample from config space W, where there may be generations of change based on a metric of performance that gives rise to hill climbing among a population that has first achieved reproductive capacity with some room for variation and passing on of variation to future generations.
I do note as is illustrated above in the OP, that locking-in to one local peak is a problem even within an island of function, much less where seas of non-function must be crossed to reach other zones of functionality above threshold, where end states can go to all sorts of possibilities in a world of attractors including strange attractors so no I do not accept that searches will self-terminate at a given point. That is only one class of attractor in a space of possibilities.
Also, kindly cf OP as I augmented, I make specific reference to configuration-based performances that can rise above a threshold spoken of as non-function, then there is the issue of hill-climbing beyond this. I specifically noted on the real challenge being to find deeply isolated shorelines of function relative to search challenge.
Let me clip:
Several times, you have raised the issue of search. I have pointed out that at base, it is tantamount to sampling from a configuration space.
[As, algebraic representation is commonly desired (and is often deemed superior to illustration or verbal description), a traditional representation of such a space is to symbolise it as Omega, here we can use w. Search then is obviously — and the obviousness is a material point here — tantamount to taking a subset of cases k in w by whatever relevant means, blind or intelligent. The search challenge then is to find some relevant zone z in w such that a performance based on configuration rises above a floor deemed non-functional: find/happen upon some z_i in w such that p(z) GT/eq f_min. Zones z are islands of function in the configuration space, w.]
The key issue is the needle in haystack search to reach shorelines of function where islands of function by the very nature of FSCO/I will be deeply isolated in config spaces and where beyond 500 - 1,000 bits sol system or observed cosmos scale atomic resources will be grossly inadequate to make blind search plausibly successful.
This is the core matter for the design inference, and side-tracks on personalities and peculiarities will be largely irrelevant.
Hence, my focus.
KF
PS: A power cut, so I will post when I can.kairosfocus
January 30, 2018
January
01
Jan
30
30
2018
05:57 AM
5
05
57
AM
PDT
kf @ 5 - if there is no target, then what is a search searching for?
If I were to start at an arbitrary case k_x and go on a random walk or on a mechanical trajectory with some noise influence, it is conceivable that I may hit on the shores of an island of function for a self-replicating, entity that may then happen to hit on hill climbing via the usual discussed means. ... And in this case there is no target as such, thus no basis for a target of search, thus no basis for an objection that a search target and a fitness function are unrelated.
Isn't the Island of Function a target? Or possibly the optimum within that island (or over all islands)?
So, I see no reason to make any grand objection out of oh, search, target and functionality must be coupled. Not when search can mean purposeless random walk or hop and/or randomly influenced trajectory from an arbitrary initial point leading to a sample from a config space.
If the search is a purposeless random walk, that means that the fitness function is flat in that region. But one can write a fitness function that is piece-wise flat, i.e. it has two levels: "in" the target, and "outside" the target. Thus, once the search is "in" the target, it stops, as it has reached the optimum.Bob O'H
January 30, 2018
January
01
Jan
30
30
2018
04:43 AM
4
04
43
AM
PDT
@KF: I take that as a "no"?DiEb
January 30, 2018
January
01
Jan
30
30
2018
04:41 AM
4
04
41
AM
PDT
DiEb, you will know well enough that my focus has always been the grounding of the design inference i/l/o needle in haystack search challenge in large configuration spaces, not the particularities and peculiarities that objectors may or may not find in the works of given personalities. I have therefore highlighted the baseline issue, and in so doing have identified what search means as sampling of a configuration space that may contain in it islands of deeply isolated function, which is relevant to the FSCO/I issue and the design inference heuristic. That is what I consider to be the relevant matter. My response just now to BO'H is what I think in response to his summary of the personality-focussed objection you are apparently making. Whatever peculiarities or extensions to the conventional thought Marks, Dembski and others may have made (with whatever successes or errors or points that need clarification), the core issue is as I have outlined and unless it is the main focus of the discussion, we have in hand little more than grand pursuit of red herrings and strawmen. KFkairosfocus
January 30, 2018
January
01
Jan
30
30
2018
04:35 AM
4
04
35
AM
PDT
BO'H: any performance of fitness is independent of whether a search -- a separate thing entirely -- has or has not a target. Where, random walks at arbitrary initial points are relevant forms of search, as are mechanically driven trajectories, which may be influenced in some aspects by noise and even chaos. Fitness is a correlate of configurations that achieve relevant function, but the business of sampling a space cannot in general be assigned to such zones. If I were to start at an arbitrary case k_x and go on a random walk or on a mechanical trajectory with some noise influence, it is conceivable that I may hit on the shores of an island of function for a self-replicating, entity that may then happen to hit on hill climbing via the usual discussed means. But the problem is that this is in relevant cases utterly implausible to the point of appeal to miracle. And in this case there is no target as such, thus no basis for a target of search, thus no basis for an objection that a search target and a fitness function are unrelated. There is in this case no target for the function to address. Where, hill climbing by RV + differential reproductive success across generations, would be emergent behaviour from the threshold of relevant function -- ability to survive, reproduce and vary [implying metabolic automata with von Neumann self replication facility and a record of information structure serving as genetic code] -- hit upon on a shoreline. So, I see no reason to make any grand objection out of oh, search, target and functionality must be coupled. Not when search can legitimately mean purposeless random walk or hop and/or randomly influenced trajectory from an arbitrary initial point leading to a sample from a config space. KFkairosfocus
January 30, 2018
January
01
Jan
30
30
2018
04:27 AM
4
04
27
AM
PDT
KF: thank your for your post, but after a first reading, I fail to see how it addresses my point of interest. I wrote
I took a closer look to find out what DEM see as the search problem in the “Introduction to Evolutionary Informatics” and how their model differs from those used by other mathematicians and scientists.
I tried to extract from DEM's textbook their meaning of "search problem" (just an aspect of search). My last paragraph reads
It could be that I have erected an elaborate strawman, and that the search problem which I attributed to DEM has nothing to do with their ideas. In this case, it should be easy for DEM – or their apologists – to come forward with their definition. Or perhaps – if I am right – they may just wish to explain why their model is not horrible.
So, do you have a definition of "search problem" which fits DEM's work? I would love to see it!DiEb
January 30, 2018
January
01
Jan
30
30
2018
04:19 AM
4
04
19
AM
PDT
Hm, I can't see that this answers DiEb's criticism - that DEM seem to allow the target of the search and the fitness function to be totally unrelated.Bob O'H
January 30, 2018
January
01
Jan
30
30
2018
03:47 AM
3
03
47
AM
PDT
F/N: I add, an algebraic summary to make the point plain to those who deem such symbolism superior to other approaches to conceptualisation. KF
PS: See above.kairosfocus


 Explanatory FilterThus, the design inference is an empirically grounded, robust framework for exploring origin of FSCO/I. And, it is testable by the simple means of identifying observed cases of origin of FSCO/I rich entities and evaluating whether blind search credibly and reliably causes FSCO/I. To date, on a trillion member observation base, no. END
Explanatory FilterThus, the design inference is an empirically grounded, robust framework for exploring origin of FSCO/I. And, it is testable by the simple means of identifying observed cases of origin of FSCO/I rich entities and evaluating whether blind search credibly and reliably causes FSCO/I. To date, on a trillion member observation base, no. END
http://theskepticalzone.com/wp…..ert-marks/>>