. . . (of the concept, functionally specific, complex organisation and associated information, FSCO/I)
Sometimes, a longstanding objector here at UD — such as RVB8 — inadvertently reveals just how weak the objections to the design inference are by persistently clinging to long since cogently answered objections. This phenomenon of ideology triumphing over evident reality is worth highlighting as a headlined post illustrating darwinist rhetorical stratagems and habits.
Here is RVB8 in a comment in the current Steve Fuller thread:
RVB8, 36: >> for ID or Creationism, I can get the information direct from the creators of the terminology. Dembski for Specified Complexity, Kairos for his invention of FSCO/I, and Behe for Irreducible Complexity.>>
For a long time, he and others of like ilk have tried to suggest that as I have championed the acrostic summary FSCO/I, the concept I am pointing to is a dubious novelty that has not been tested through peer review or the like and can be safely set aside. In fact, it is simply acknowledging that specified complexity is both organisational and informational, and that in many contexts it is specified in the context of requisites of function through multiple coupled parts. Text such as in this post shows a simple form of such a structure, S-T-R-I-N-G-S.
As it seems necessary to set a pronunciation, the acronym FSCO/I shall henceforth be pronounced “fish-koi” (where happily, koi are produced by artificial selection, a form of ID too often misused as a proxy for the alleged powers of culling out by differential reproductive success in the wild)
Where of course, memorably, Crick classically pointed out to his son Michael on March 19, 1953 as follows, regarding DNA as text:

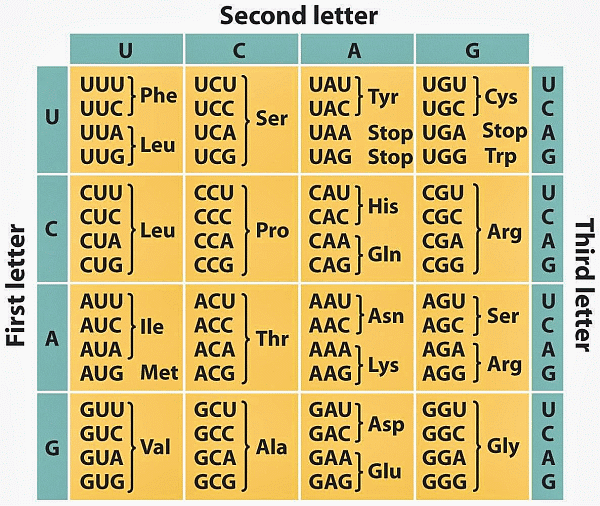
Subsequently, that code was elucidated (here in the mRNA, transcribed form):
Likewise a process flow network is an expression of FSCO/I, e.g. an oil refinery:

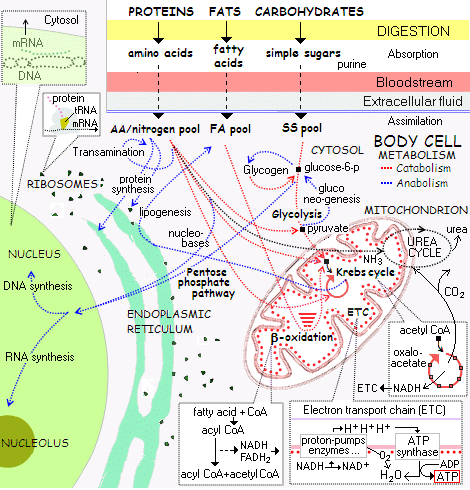
This case is much simpler than the elucidated biochemistry process flow metabolic reaction network of the living cell:
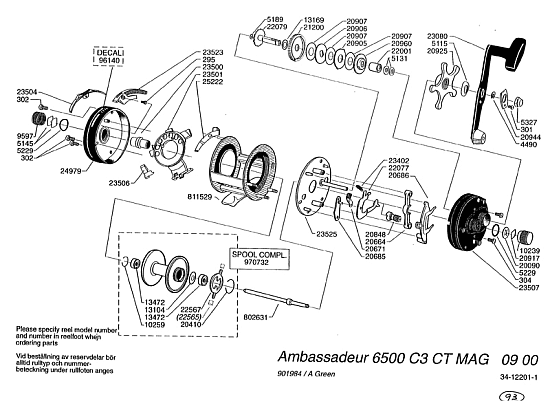
I have also often illustrated FSCO/I in the form of functional organisation through a drawing of an ABU 6500 C3 reel (which I safely presume came about through using AutoCAD or the like):
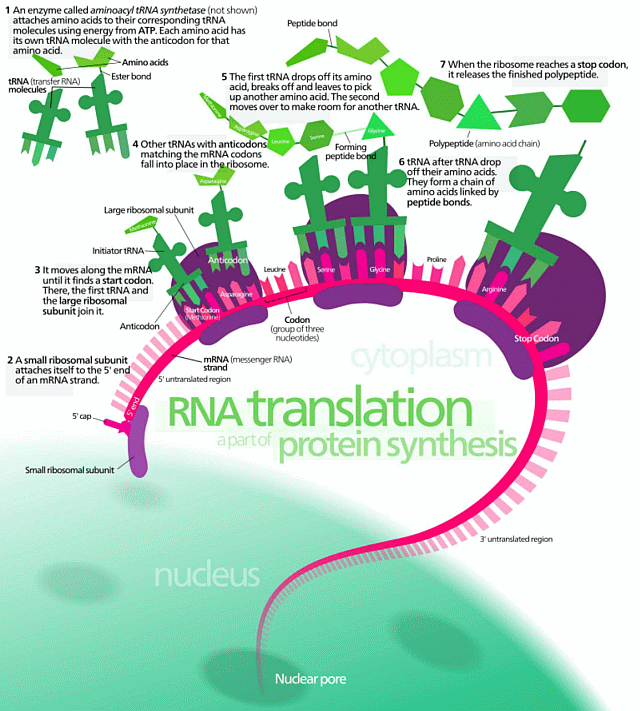
All of this is of course very directly similar to something like protein synthesis [top left in the cell’s biochem outline], which involves both text strings and functionally specific highly complex organisation:
In short, FSCO/I is real, relevant and patently descriptive, both of the technological world and the biological world. This demands an adequate causal explanation, and the only serious explanation on the table that is empirically warranted is, design.
As the text of this post illustrates, and as the text of objector comments to come will further inadvertently illustrate.
Now, I responded at no 37, as follows:
KF, 37: >>Unfortunately, your choice of speaking in terms of “invention” of FSCO/I speaks volumes on your now regrettably habitual refusal to acknowledge phenomena that are right in front of you. As in, a descriptive label acknowledges a phenomenon, it does not invent it.
Doubtless [and on long track record], you think that is a clever way to dismiss something you don’t wish to consider.
This pattern makes your rhetoric into a case in point of the sociological, ideological reaction to the design inference on tested sign. So, I now respond, by way of addressing a case of a problem of sustained unresponsiveness to evidence.
However, it only reveals that you are being selectively hyperskeptical and dismissive through the fallacy of the closed, ideologised, indoctrinated, hostile mind.
I suggest you need to think again.
As a start, look at your own comment, which is text. To wit, a s-t-r-i-n-g of 1943 ASCII characters, at 7 bits per character, indicating a config space of 2^[7 * 1943) possibilities. That is, a space with 2.037*10^4094 cells.
The atomic and temporal resources of our whole observed cosmos, running at 1 search per each of 10^80 atoms, at 10^12 – 10^14 searches per s [a fast chem reaction rate] for 10^17 s [time since big bang, approx.] could not search more than 10^111 cells, a negligibly small fraction. That is, the config space search challenge is real, there is not enough resource to search more than a negligibly small fraction of the haystack blindly. (and the notion sometimes put, of somehow having a golden search runs into the fact that searches are subsets, so search for a golden search comes from the power set of the direct config space, of order here 2^[10^4094]. That is, it is exponentially harder.)
How then did your text string come to be? By a much more powerful means: you as an intelligent and knowledgeable agent exerted intelligently directed configuration to compose a text in English.
That is why, routinely, when you see or I see text of significant size in English, we confidently and rightly infer to design.
As a simple extension, a 3-d object such as an Abu 6500 C3 fishing reel is describable, in terms of bit strings in a description language, so functional organisation is reducible to an informational equivalent. Discussion on strings is WLOG.
In terms of the living cell, we can simply point to the copious algorithmic TEXT in DNA, which directly fits with the textual search challenge issue. There is no empirically warranted blind chance and mechanical necessity mechanism that can plausibly account for it. We have every epistemic and inductive reasoning right to see that the FSCO/I in the cell is best explained as a result of design.
That twerdun, which comes before whodunit.
As for, oh it’s some readily scorned IDiot on a blog, I suggest you would do better to ponder this from Stephen Meyer:
The central argument of my book [= Signature in the Cell] is that intelligent design—the activity of a conscious and rational deliberative agent—best explains the origin of the information necessary to produce the first living cell. I argue this because of two things that we know from our uniform and repeated experience, which following Charles Darwin I take to be the basis of all scientific reasoning about the past. First, intelligent agents have demonstrated the capacity to produce large amounts of functionally specified information (especially in a digital form). Second, no undirected chemical process has demonstrated this power. Hence, intelligent design provides the best—most causally adequate—explanation for the origin of the information necessary to produce the first life from simpler non-living chemicals. In other words, intelligent design is the only explanation that cites a cause known to have the capacity to produce the key effect in question . . . . In order to [[scientifically refute this inductive conclusion] Falk would need to show that some undirected material cause has [[empirically] demonstrated the power to produce functional biological information apart from the guidance or activity a designing mind. Neither Falk, nor anyone working in origin-of-life biology, has succeeded in doing this . . . .
The central problem facing origin-of-life researchers is neither the synthesis of pre-biotic building blocks (which Sutherland’s work addresses) or even the synthesis of a self-replicating RNA molecule (the plausibility of which Joyce and Tracey’s work seeks to establish, albeit unsuccessfully . . . [[Meyer gives details in the linked page]). Instead, the fundamental problem is getting the chemical building blocks to arrange themselves into the large information-bearing molecules (whether DNA or RNA) . . . .
For nearly sixty years origin-of-life researchers have attempted to use pre-biotic simulation experiments to find a plausible pathway by which life might have arisen from simpler non-living chemicals, thereby providing support for chemical evolutionary theory. While these experiments have occasionally yielded interesting insights about the conditions under which certain reactions will or won’t produce the various small molecule constituents of larger bio-macromolecules, they have shed no light on how the information in these larger macromolecules (particularly in DNA and RNA) could have arisen. Nor should this be surprising in light of what we have long known about the chemical structure of DNA and RNA. As I show in Signature in the Cell, the chemical structures of DNA and RNA allow them to store information precisely because chemical affinities between their smaller molecular subunits do not determine the specific arrangements of the bases in the DNA and RNA molecules. Instead, the same type of chemical bond (an N-glycosidic bond) forms between the backbone and each one of the four bases, allowing any one of the bases to attach at any site along the backbone, in turn allowing an innumerable variety of different sequences. This chemical indeterminacy is precisely what permits DNA and RNA to function as information carriers. It also dooms attempts to account for the origin of the information—the precise sequencing of the bases—in these molecules as the result of deterministic chemical interactions . . . .
[[W]e now have a wealth of experience showing that what I call specified or functional information (especially if encoded in digital form) does not arise from purely physical or chemical antecedents [[–> i.e. by blind, undirected forces of chance and necessity]. Indeed, the ribozyme engineering and pre-biotic simulation experiments that Professor Falk commends to my attention actually lend additional inductive support to this generalization. On the other hand, we do know of a cause—a type of cause—that has demonstrated the power to produce functionally-specified information. That cause is intelligence or conscious rational deliberation. As the pioneering information theorist Henry Quastler once observed, “the creation of information is habitually associated with conscious activity.” And, of course, he was right. Whenever we find information—whether embedded in a radio signal, carved in a stone monument, written in a book or etched on a magnetic disc—and we trace it back to its source, invariably we come to mind, not merely a material process. Thus, the discovery of functionally specified, digitally encoded information along the spine of DNA, provides compelling positive evidence of the activity of a prior designing intelligence. This conclusion is not based upon what we don’t know. It is based upon what we do know from our uniform experience about the cause and effect structure of the world—specifically, what we know about what does, and does not, have the power to produce large amounts of specified information . . . .
[[In conclusion,] it needs to be noted that the [[now commonly asserted and imposed limiting rule on scientific knowledge, the] principle of methodological naturalism [[ that scientific explanations may only infer to “natural[[istic] causes”] is an arbitrary philosophical assumption, not a principle that can be established or justified by scientific observation itself. Others of us, having long ago seen the pattern in pre-biotic simulation experiments, to say nothing of the clear testimony of thousands of years of human experience, have decided to move on. We see in the information-rich structure of life a clear indicator of intelligent activity and have begun to investigate living systems accordingly. If, by Professor Falk’s definition, that makes us philosophers rather than scientists, then so be it. But I suspect that the shoe is now, instead, firmly on the other foot. [[Meyer, Stephen C: Response to Darrel Falk’s Review of Signature in the Cell, SITC web site, 2009. (Emphases and parentheses added.)]
Let me focus attention on the highlighted:
First, intelligent agents have demonstrated the capacity to produce large amounts of functionally specified information (especially in a digital form). Second, no undirected chemical process has demonstrated this power. Hence, intelligent design provides the best—most causally adequate—explanation for the origin of the information necessary to produce the first life from simpler non-living chemicals.
The only difference between this and what I have highlighted through the acronym FSCO/I, is that functionally specific organisation is similarly reducible to an informational string and is in this sense equivalent to it. Where, that is hardly news, AutoCAD has reigned supreme as an engineers design tool for decades now. Going back to 1973, Orgel in his early work on specified complexity, wrote:
. . . In brief, living organisms are distinguished by their specified complexity. Crystals are usually taken as the prototypes of simple well-specified structures, because they consist of a very large number of identical molecules packed together in a uniform way. Lumps of granite or random mixtures of polymers are examples of structures that are complex but not specified. The crystals fail to qualify as living because they lack complexity; the mixtures of polymers fail to qualify because they lack specificity . . . .
[HT, Mung, fr. p. 190 & 196:] These vague idea can be made more precise by introducing the idea of information. Roughly speaking, the information content of a structure is the minimum number of instructions needed to specify the structure. [–> this is of course equivalent to the string of yes/no questions required to specify the relevant “wiring diagram” for the set of functional states, T, in the much larger space of possible clumped or scattered configurations, W, as Dembski would go on to define in NFL in 2002, also cf here, here and here (with here on self-moved agents as designing causes).] One can see intuitively that many instructions are needed to specify a complex structure. [–> so if the q’s to be answered are Y/N, the chain length is an information measure that indicates complexity in bits . . . ] On the other hand a simple repeating structure can be specified in rather few instructions. [–> do once and repeat over and over in a loop . . . ] Complex but random structures, by definition, need hardly be specified at all . . . . Paley was right to emphasize the need for special explanations of the existence of objects with high information content, for they cannot be formed in nonevolutionary, inorganic processes. [The Origins of Life (John Wiley, 1973), p. 189, p. 190, p. 196.]
So, the concept of reducing functional organisation to a description on a string of y/n structured questions — a bit string in some description language — is hardly news, nor is it something I came up with. Where obviously Orgel is speaking to FUNCTIONAL specificity, so that is not new either.
Likewise, search spaces or config spaces is a simple reflection of the phase space concept of statistical thermodynamics.
Dembski’s remarks are also significant, here from NFL:
p. 148:“The great myth of contemporary evolutionary biology is that the information needed to explain complex biological structures can be purchased without intelligence. My aim throughout this book is to dispel that myth . . . . Eigen and his colleagues must have something else in mind besides information simpliciter when they describe the origin of information as the central problem of biology.
I submit that what they have in mind is specified complexity, or what equivalently we have been calling in this Chapter Complex Specified information or CSI . . . .
Biological specification always refers to function. An organism is a functional system comprising many functional subsystems. . . . In virtue of their function [[a living organism’s subsystems] embody patterns that are objectively given and can be identified independently of the systems that embody them. Hence these systems are specified in the sense required by the complexity-specificity criterion . . . the specification can be cashed out in any number of ways [[through observing the requisites of functional organisation within the cell, or in organs and tissues or at the level of the organism as a whole. Dembski cites:
Wouters, p. 148: “globally in terms of the viability of whole organisms,”
Behe, p. 148: “minimal function of biochemical systems,”
Dawkins, pp. 148 – 9: “Complicated things have some quality, specifiable in advance, that is highly unlikely to have been acquired by ran-| dom chance alone. In the case of living things, the quality that is specified in advance is . . . the ability to propagate genes in reproduction.”
On p. 149, he roughly cites Orgel’s famous remark from 1973, which exactly cited reads:
In brief, living organisms are distinguished by their specified complexity. Crystals are usually taken as the prototypes of simple well-specified structures, because they consist of a very large number of identical molecules packed together in a uniform way. Lumps of granite or random mixtures of polymers are examples of structures that are complex but not specified. The crystals fail to qualify as living because they lack complexity; the mixtures of polymers fail to qualify because they lack specificity . . .
And, p. 149, he highlights Paul Davis in The Fifth Miracle: “Living organisms are mysterious not for their complexity per se, but for their tightly specified complexity.”] . . .”
p. 144: [[Specified complexity can be more formally defined:] “. . . since a universal probability bound of 1 [[chance] in 10^150 corresponds to a universal complexity bound of 500 bits of information, [[the cluster] (T, E) constitutes CSI because T [[ effectively the target hot zone in the field of possibilities] subsumes E [[ effectively the observed event from that field], T is detachable from E, and and T measures at least 500 bits of information . . . ”
So, the problem of refusal to attend to readily available, evidence or even evidence put in front of objectors to design theory is significant and clear.
What it in the end reflects as a case of clinging to fallacies and myths in the teeth of correction for years on end, is the weakness of the case being made against design by its persistent objectors.
Which is itself highly significant.>>
Now, let us discuss, duly noting the highlighted and emphasised. END