In recent days, objector ES has been twisting the concept of Wickensian functionally specific information-bearing complex organisation into post-modernist deconstructionist subjectivist pretzels, in order to obfuscate the plain inductive argument at the heart of the design inference and/or explanatory filter.
For example, consider these excerpts from the merry go round thread:
ES, 41: . . . If a conscious observer connects some observed object to some possible desired result which can be obtained using the object in a context, then we say that the conscious observer conceives of a function for that object . . . . In science, properties of the material just are, without purpose, because everybody knows purpose is subjective. Functionality comes in when you get engineerial, and then it’s more up to the “objective functionality” of the engineer than of the material . . .
KF, 42: When one puts together a complex composite such as a program or an electronic amplifier ckt or a watch or an auto engine or many other things, function is not projected to it by an observer. I wuk, or i nuh wuk, mon. Was that a bad starter motor, a run down battery, out of gas, dirty injector points and more. Was that a bug in syntax or in semantics. Was that a BJT miswired and fried, did you put in the wrong size load resistor so it sits in saturation when it was meant to be in the middle of the load line, did you put in an electrolytic cap the wrong way around, etc. Is this a heart attack triggered by a blood clot etc. Function is not a matter of imagination but observation. And you full well know that or should.
Joe, 44: Earth to E. Seigner- functionality, ie a function, is an OBSERVATION. We observe something performing some function and we investigate to try to figure out how it came to be the way it is. Within living organisms we observe functioning systems and subsystems. As for “information”, well with respect to biology ID uses the same definition that Crick provided decades ago. And we say it can be measured the same way Shannon said, decades ago.
ES, 46: To an observer it looks like cars take people to work and shopping. But most of the time cars stand in garage motionless, and sometimes they fail to start. If the observer is truly impartial, then it’s not up to him to say that the failure to start or mere standing is any less of the car’s function than the ability of being driven. The car’s function is what the car does and when the car fails to start then that’s what it does and this is its function. Of course this sounds silly, but it’s true . . .
BA, 48: It is clear to me now. You have drunk deeply from the post-modernist/constructivist Koolaid. Kairosfocus and gpuccio be advised — attempting to reason with such as E.Seigner is pointless.
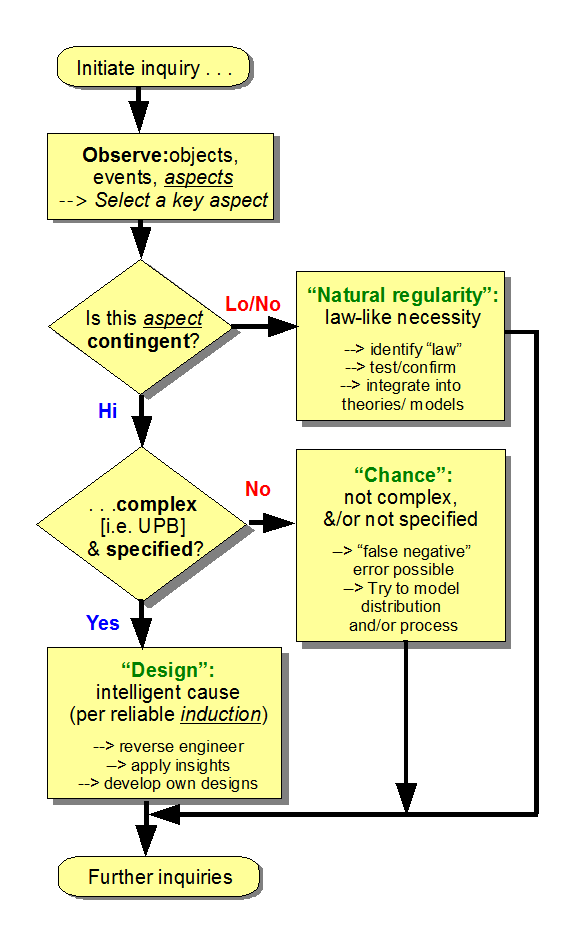
Let’s first remind ourselves as to what the glorified common-sense design inference process actually does as an exercise in inductive, inference to the best current explanation on empirically observed evidence:
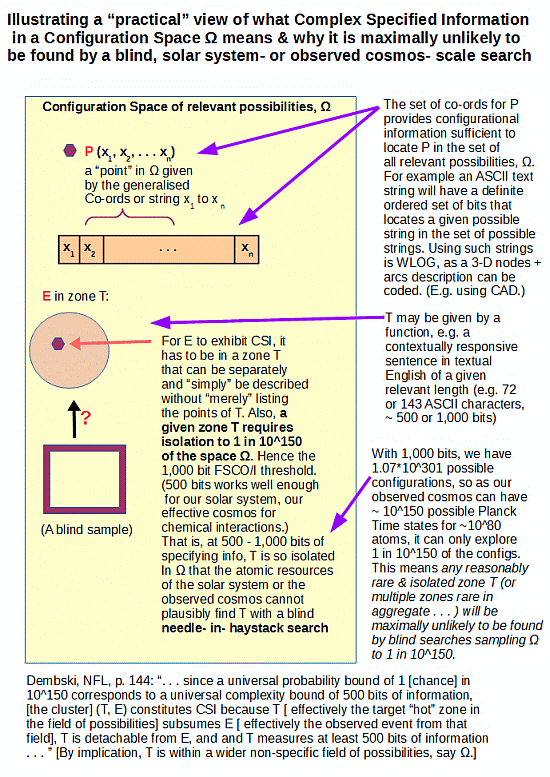
. . . and also, of the significance of Wickensian functionally specific, complex information and Orgellian informational specified complexity for a blind, needle in haystack search; as highlighted by Dembski et al:
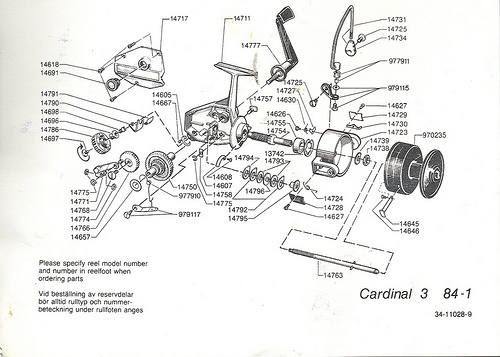
While we are at it, let us remind ourselves of what FSCO/I looks like in the form of functionally specific organisation in the technological world:
Fig 6: An exploded view of a classic ABU Cardinal, showing how functionality arises from a highly specific, tightly constrained complex arrangement of matched parts according to a “wiring diagram.” Such diagrams are objective (the FSCO/I on display here is certainly not “question-begging,” as some — astonishingly — are trying to suggest!), and if one is to build or fix such a reel successfully, s/he had better pay close heed.. Taking one of these apart and shaking it in a shoe-box is guaranteed not to work to get the reel back together again. (That is, even the assembly of such a complex entity is functionally specific and prescriptive information-rich.)
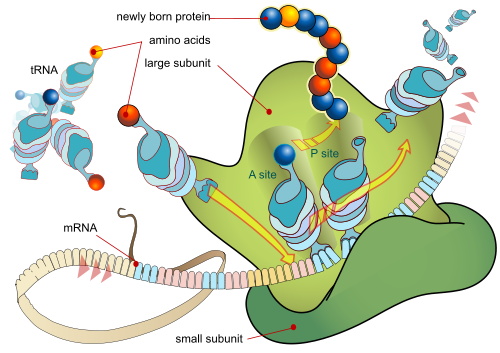
. . . and, in the life of the cell, as the Ribosome constructs a protein (which is a functionally specific string structure) based on the coded algorithmic information in the mRNA tape:
Step by step protein synthesis in action, in the ribosome, based on the sequence of codes in the mRNA control tape (Courtesy, Wikipedia and LadyofHats)
. . . not to mention, the parallel in the punched paper tape reader used for older computers and NC machines:
Punched paper Tape, as used in older computers and numerically controlled machine tools (Courtesy Wiki & Siemens)
(When things have been strawmannised and twisted into pretzels, it helps to straighten them back out again. Where also, a picture is worth a thousand words.)
However, Mr Arrington has a point.
While those caught up in po mo deconstructionist schemes are hardly likely to have a sudden change of heart on the strength of a mere blog comment or even a headlined post, the rest of us can draw lessons from what we see laid out before us. I therefore crave the indulgence of a promoted comment to headlined status, including a snippet of intensely personal history of my homeland. For, comments get buried and forgotten within hours, but a headlined post is for the record:
It may be entertaining to play semantics games with terms like function, but that simply reveals that your problem is not with science, it is with common sense reality tracing to some of the sillier bits of post-modernist radical subjectivism and deconstructionism.
Perhaps, it has not dawned on you that survival of the fittest or hill-climbing algorithms or natural selection or the like pivot on the objectivity of function. Have you gone to Panda’s Thumb, TSZ, ATBC or the like Darwinist agitator sites to challenge the core concepts of evolution based on differential reproductive success pivoting on functional differences of life-forms? I safely bet not, you are reserving such talking-points for those you object to, regardless of inconsistencies or outright incoherence.
[Ill-]Logic with a swivel.
Patently, revealingly, sadly, you have indulged in incoherent selective hyperskepticism.
And if you genuinely imagine that a stalled car with a dead engine, or a leaky roof, or a crashed computer, or a PA system that distorts sounds horribly are functionally distinct as a mere matter of subjective opinion, your problem is a breach of common sense.
Do you — or a significant other — have a mechanic? Are you a shade-tree mechanic? Do you have even one tool for maintenance? Do you recognise the difference between sugar, salt and arsenic in your cup of coffee? Between an effective prescription correctly filled and faithfully carried out when you get sick and a breakdown of that process? Etc?
I put it to you that you cannot and do not live consistent with your Lit class seminar-room talking points.
And, your evasive resort to clinging to such absurdities to obfuscate the issue of functionally specific, complex organisation and associated information, speaks loudest volumes for the astute onlooker.
Own-goal, E-S.
The bottom-line of the behaviour of several objectors over the past few days, speaks inadvertent volumes on the real balance on the merits of the core design theory contention that there are such things as reliable empirical markers — such as Wickensian FSCO/I — that are strong signs of design as key causal process.
But, many are so wedded to the totalising metanarrative of a priori Lewontinian evolutionary materialism that they refuse to heed the 2350 year old warning posed by Plato on where cynical radical relativism, amorality opening the door to might makes right nihilism and ruthless factions points to for a civilisation. Refusing to learn the hard-bought, paid for in blood lessons of history, they threaten to mislead our civilisation into yet another predictably futile and bloody march of folly. As the ghosts of 100 million victims of such demonically wicked deceptions over the past century warn us.
The folly on the march in our day is so arrogantly stubborn that it refuses to learn living memory history or the history passed on first hand to our grand parents.
Here is Sophia (personification of Wisdom), in the voice of Solomon echoing hard-bought, civil war triggered lessons in Israel c 1,000 BC:
Prov 1:20 Wisdom [Gk, Sophia] cries aloud in the street,
in the markets she raises her voice;
21 at the head of the noisy streets she cries out;
at the entrance of the city gates she speaks:
22 “How long, O simple ones, will you love being simple?
How long will scoffers delight in their scoffing
and fools hate knowledge?
23 If you turn at my reproof,[a]
behold, I will pour out my spirit to you;
I will make my words known to you.
24 Because I have called and you refused to listen,
have stretched out my hand and no one has heeded,
25 because you have ignored all my counsel
and would have none of my reproof,
26 I also will laugh at your calamity;
I will mock when terror strikes you,
27 when terror strikes you like a storm
and your calamity comes like a whirlwind,
when distress and anguish come upon you.
28 Then they will call upon me, but I will not answer;
they will seek me diligently but will not find me.
29 Because they hated knowledge
and did not choose the fear of the Lord,
30 would have none of my counsel
and despised all my reproof,
31 therefore they shall eat the fruit of their way,
and have their fill of their own devices.
32 For the simple are killed by their turning away,
and the complacency of fools destroys them;
33 but whoever listens to me will dwell secure
and will be at ease, without dread of disaster.”
A grim warning, bought at the price of a spoiled, wayward son who fomented disaffection and led rebellion triggering civil war and needless death and destruction, ending in his own death and that of many others.
Behind the Proverbs lies the anguished wailing of a father who had to fight a war with his son and in the end cried out, Oh Absalom, my son . . .
History sorts out the follies of literary excesses, if we fail to heed wisdom in good time.
Often, at the expense of a painful, bloody trail of woe and wailing that leads many mothers and fathers, widows and orphans to wail the loss of good men lost to the fight in the face of rampant folly.
But then, tragic history is written into my name, as George William Gordon’s farewell to his wife written moments before his unjust execution on sentence of a kangaroo court-martial, was carried out:
My beloved Wife, General Nelson has just been kind enough to inform me that the court-martial on Saturday last has ordered me to be hung, and that the sentence is to be executed in an hour hence; so that I shall be gone from this world of sin and sorrow.
I regret that my worldly affairs are so deranged; but now it cannot be helped. I do not deserve this sentence, for I never advised or took part in any insurrection. All I ever did was to recommend the people who complained to seek redress in a legitimate way; and if in this I erred, or have been misrepresented, I do not think I deserve the extreme sentence. It is, however, the will of my Heavenly Father that I should thus suffer in obeying his command to relieve the poor and needy, and to protect, as far as I was able, the oppressed. And glory be to his name; and I thank him that I suffer in such a cause. Glory be to God the Father of our Lord Jesus Christ; and I can say it is a great honour thus to suffer; for the servant cannot be greater than his Lord. I can now say with Paul, the aged, “The hour of my departure is at hand, and I am ready to be offered up. I have fought a good fight, I have kept the faith, and henceforth there is laid up for me a crown of righteousness, which the Lord, the righteous Judge shall give me.” Say to all friends, an affectionate farewell; and that they must not grieve for me, for I die innocently. Assure Mr. Airy and all others of the truth of this. Comfort your heart. I certainly little expected this. You must do the best you can, and the Lord will help you; and do not be ashamed of the death your poor husband will have suffered. The judges seemed against me, and from the rigid manner of the court I could not get in all the explanation I intended . . .
Deconstruct that, clever mocking scorners of the literary seminar room.
Deconstruct it in the presence of a weeping wife and mother and children mourning the shocking loss of a father and hero to ruthless show-trial injustice ending in judicial murder.
Murder that echoes the fate of one found innocent but sent to Golgotha because of ruthless folly-tricks in Jerusalem c. 30 AD.
(How ever so many fail to see the deep lesson about folly-tricks in the heart of the Gospel, escapes me. New Atheists and fellow travellers, when you indict the Christian Faith as the fountain-head of imagined injustice, remember the One who hung between thieves on a patently unjust sentence, having been bought at the price of a slave through a betrayer blinded by greed and folly. If you do not hear a cry for just government and common decency at the heart of the Gospel you would despise, you are not worth the name, literary scholar or educated person.)
And in so doing, learn a terrible, grim lesson of where your clever word games predictably end up in the hands of the ruthless.
For, much more than science is at stake in all of this.
GEM of TKI >>
_________________
I trust that the astute onlooker will be inclined to indulge so personal a response, and will duly draw on the hard-bought lessons of history (and of my family story . . . ) as just outlined. END
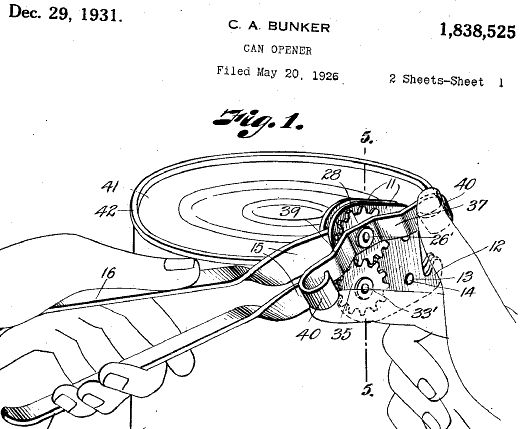
PS, Sept 30: ES has been making heavy weather over the idea of a primitive tribe encountering a can opener for the first time and not understanding its function (which he then wishes to project as subjective):
A rotating cutter can opener in action
And, a modern development showing meshing serrated gears:
modern rotary action can opener with meshing gears (Both images HT Wiki)
However, this is both incorrect and irrelevant to recognising from aspects of the can opener that exhibit FSCO/I, that it is designed:
1 –> Whether or not the primitive seeing an opener for the first time can recognise its purpose and contrivance that integrates materials, forces of nature and components into a functioning whole, that functionally specific, complex organisation for a purpose exists and is embedded in how the opener is designed.
2 –> Just by looking at the evident contrivance manifested in FSCO/I that is maximally unlikely to obtain by blind chance and mechanical necessity — as with the fishing reel above, the primitive is likely to perceive design.
3 –> The rotating gears with matched teeth set to couple together alone implies highly precise artifice to build centred disks, cut matching gearing, mount them on precisely separated and aligned centred axes, with other connected parts already demonstrates design to a reasonable onlooker.
4 –> The precisely uniformly thick handles joined in a pivot, and reflecting rectangle-based shapes would be equally demonstrative.
5 –> Where, actual intended function has not been brought to bear. (And note, we see here again the implicit demand that the design inference be a universal decoder/ algorithm identifier. That is a case of setting up and knocking over a strawman, where . . . just on theory of computation, such a universal decoder/detector is utterly implausible. The point of the design inference is that on inductively confirmed reliable signs such as FSCO/I we may confidently identify design — purposefully directed contingency or contrivance — as key causal factor. It seems that any number of red herrings are led away from this point to convenient strawman caricatures that are then knocked over as though the actual point has been effectively answered on the merits. It has not.)
6 –> But of course, that functionality dependent on specific components and an arrangement otherwise vanishingly improbable, reeks of design and the function can be readily demonstrated, as the patents diagram shows.
7 –> Where, again, it must be underscored that, per my comment 49 to ES:
[the] ultra-modernist, ugly- gulch- between- the- inner- world- and- the outer- one [of] sophomorised Kantianism fails and needs to be replaced with a sounder view. As F H Bradley pointd out over a century ago, to pretend to know that the external world is un-knowable due to the nature of subjectivitiy . . . the denial of objective knowledge . . . is itself a claim to objective knowledge of the external world and a very strong one too. Which therefore is self-referentially incoherent. Instead, it is wiser to follow Josiah Royce’s point that we know that error exists, undeniably and self evidently. Thus, there are certain points of objective knowledge that are firm, that ground that objective truth, warrant and knowledge exist, and that schemes of thought that deny or denigrate such fail. Including post modernism, so called. Of course, that we know that error exists means we need to be careful and conservative in knowledge claims, but the design inference is already that, it is explicitly inductive on inference to best explanation on observed patterns and acknowledges the limitations of inductive knowledge including scientific knowledge. [A Po-Mo] selectively hyperskeptical focus on the design inference while apparently ignoring the effect of that same logic on science as a whole, on history, on common sense reality and on reason itself, simply multiplies the above by highlighting the double standard on warrant.
8 –> In short, we have here a case of clinging to an ideological absurdity in the teeth of accessible, well-warranted correction.
Comments
Mark:
By the way, as you can see REC is already there trying the card of necessity (NS, intermediates, and so on). That is significant.
The truth is, neo darwinists always try to play the card of random variation as far as they can. When they are in a position where the cannot do that any more, they try to play the card of necessity and NS. And they stick to the few pitiful papers that they think can support a position which is supported by no facts at all.
Obviously, when they can do that no more, they are ready to play again the card of random variation.
In the same way, some of our interlocutors are all neutral variation as far as they can. When reminded that neutral variation is completely useless to explain functional information, they "awaken" for a moment and go back to the old reassuring NS. Not for long. When NS remains unsupported by facts, the neutral theory is there again, to lend credibility to a theory which has none.gpuccio
October 12, 2014
October
10
Oct
12
12
2014
01:57 PM
1
01
57
PM
PDT
Mark:
I understand that. And, as I have said, I maintain that in design detection we can dismiss H0 (the hypothesis that the functional information can be explained by random variance) even if we have no idea of how to explain the functional information in other ways.
Once we have rejected H0 (intrinsic probabilistic variation) as an explanation of the functional organization we observe, we are left, as far as I can judge, with two alternatives:
a) Some explanation based on necessity, IOWs non conscious laws and regularities.
b) The intervention of a conscious purposeful agent (design).
As I have explained many times, I don't say that because I believe a priori that design is the complement of chance and necessity. My point of view is entirely empirical, not logical. If a random explanation is rejected, I really am not aware of other possible explanations except necessity or design. If you know of other alternatives, I am ready to consider them.gpuccio
October 12, 2014
October
10
Oct
12
12
2014
01:49 PM
1
01
49
PM
PDT
221 REC
As biochemists reveal the simple molecular pathways that give new functions,…
What are the simple molecular pathways that give the functionality seen in the few research examples posted in the thread pointed to by this link?
https://uncommondescent.com/evolution/a-third-way-of-evolution/#comment-519017
Thank you.Dionisio
October 12, 2014
October
10
Oct
12
12
2014
01:44 PM
1
01
44
PM
PDT
REC:
You are really trying your best, but you are wrong.
I have always used the term superfamily in all my discussion on this blog for years. Go and check.
The functional information in beta lactamase, the 336 bits measured by Durston, refer to the whole functional information in the molecule: its folding, structure and active site.
In the paper they have engineered a new substrate specificity starting from an existing protein with the appropriate fold and structure (same family). That is protein engineering starting from a lot of functional information (the existing proteins) and and adding the new specificity to the active site by a lot of engineering.
In my procedure, you have obviously to consider the information that already is in the system. Even Durston's paper deals with the case of measuring functional information in a transition, which is a completely different scenario. In my discussions here I have always specified that we were measuring a random walk from an unrelated state. Can you read?
It is typical of those who have no real argument to try to play tricks. Either you don't understand the concept of functional information, or you don't want to understand it.
Let's say that I have a Shakespeare sonnet and I change by a random search only one word, changing a little the meaning. The transition is simple. I am using most of the information which is already there.
So, stop paying tricks, and discuss seriously and with respect for what others say.
Regarding the family/superfamily problem, I have always discussed superfamilies as the best tradeoff which guarantees that the functional islands are unrelated. There are 2000 superfamilies and 4000 families. The choice of what grouping one uses can differ, but the concept remains. Basic foldings are about 1000.
Durston uses families, but in SCOP classification beta lactamases and D-Ala peptidases are part of the same family, not only of the same superfamily.
I don't know if Durston has included only forms of beta lactamase in his computation. Maybe if he had included D-Ala peptidases, the computation would have been lower, but it is also true that the shift in substrate affinity needs functional information too. However you put it, the computation of functional specification is an approximation, and it is perfectly normal that there are technical problems that must be faced. In no way that invalidates the concept and the procedure.
There is more. According to the big bang theory of protein evolution, new superfamilies appear at some time, and after that they traverse their functional space, by neutral variation and negative selection. So, the diversity that we observe in a superfamily or family at sequence level if generated after the appearance of the functional molecule. That's how the fold and structure can be retained even in front of big sequence deviations.
There is more. In many proteins (probably not all) part of the diversity in a protein family can be functional, and not only due to neutral variation. In different species the same molecule can certainly adapt to different context, of localization, of protein interaction, of regulation. That kind of functional variation will be read by the Durston method as non functional diversity. Therefore, it is very likely that the Durston method, in general, uderestimates the true functional complexity.
By the way, if you want some stronger example, let's go back to the alpha and beta subunits of ATP synthase, with its hundreds of AA identities from LUCA to humans, through 4 billion years. Or to dynein, with its highly conserved 4000 plus AAs. Or to the Photosystem 2 in cyanobacteria, already there and functioning before the integration in the plant plastids, and highly conserved too? Must I go on with the examples?
Can you please show the simple molecular pathways that lead to those molecules?gpuccio
October 12, 2014
October
10
Oct
12
12
2014
01:42 PM
1
01
42
PM
PDT
Gpuccio
We seem to be passing each other by. I really did not want to revise the whole functional spec debate. I was only interested in the notion that you can dismiss H0 without having any idea what H1 is.
MarkMark Frank
October 12, 2014
October
10
Oct
12
12
2014
01:08 PM
1
01
08
PM
PDT
221 REC
As biochemists reveal the simple molecular pathways that give new functions,...
Since we got into this cut&paste thing a few posts ago, what is the simple molecular pathway that lead to the cut&paste functionality?Dionisio
October 12, 2014
October
10
Oct
12
12
2014
01:04 PM
1
01
04
PM
PDT
220 REC
How does that get lost during a cut and paste?
Is there some cut&paste* going on in cellular/molecular biology?
Do 'slash' characters get lost in those cases too? :)
Is that biological cut&paste functionality part of an open source app or proprietary software? :)
(*) splicing and that stuffDionisio
October 12, 2014
October
10
Oct
12
12
2014
12:56 PM
12
12
56
PM
PDT
220 REC
Yes, that was it. I did not notice the missing slash :)
Thanks.
No idea how that slash could have disappeared during a copy&paste operation. As you can see, there are few things we still don't understand. :)
BTW, your discussion with gpuccio is above my pay grade. All I can do is check if the links work. Nothing else. :)Dionisio
October 12, 2014
October
10
Oct
12
12
2014
12:42 PM
12
12
42
PM
PDT
Gpuccio,
I think the point is made: if "b-lactamase activity" was your chosen specification, then you'd get a big number, which you say indicates design. This specification also happens to be a 3-amino acid change from another pre-existing specification. This gap, I think everyone would admit, seems evolvable. You have stated: "The same procedure works for any complex function." Any complex function. Whatever specification. 100% specificity in detecting design.
So, we arrive at a new specification: Post 218 is the first use of "superfamily" as a functional specification in this thread.
In Durston's paper "super" doesn't appear. They are analyzing families, and hoping to correlating sequence information to a given function: "The functionality of the protein can be known and is consistent with the whole protein family." Although function is loosely defined, their examples hint at biochemical or cellular activity.
You should then, inform us that the function you are interested in is not B-lactamase activity, but what I assume is merely the fold? of the superfamily (as the superfamily itself appears to have maybe 20 different functions from transpeptidase to nuclease to esterase).
You also then need to stop using Durston's fits for the b-lactamase function, which from the number of sequences used in the paper, must reflects b-lactamase eznymes, not the whole superfamily. Redo the analysis with all 20,000+ member sequences of less than 20% identity and see what you get.
Also, a warning from Durston et al: "For example, if many sequences that do not share the same function f, are mistakenly included within an aligned set representing some particular function, we should expect the measure of FSC of that set to be degraded, possibly even to a very small value. However, when the specified functionality is chosen meaningfully (even in part), then FSC can be interpreted."
As biochemists reveal the simple molecular pathways that give new functions, retreating to the origins of superfamilies (of which there are very few, and which infrequently arise) seems natural. But I'm not sure this will last for you:
http://www.nature.com/nchembio/journal/v10/n9/full/nchembio.1579.htmlREC
October 12, 2014
October
10
Oct
12
12
2014
11:34 AM
11
11
34
AM
PDT
Dioniso-slash between the .com and chemistry:
http://www.cell.com/chemistry-biology/abstract/S1074-5521(96)90182-9
How does that get lost during a cut and paste?REC
October 12, 2014
October
10
Oct
12
12
2014
10:41 AM
10
10
41
AM
PDT
216 REC
Please, can you double check the first link? thanks.
http://www.cell.comchemistry-biology/abstract/S1074-5521(96)90182-9Dionisio
October 12, 2014
October
10
Oct
12
12
2014
10:35 AM
10
10
35
AM
PDT
REC:
Thank you for the congrats.
As you may know, my argument about design inference for proteins has always been about new protein superfamilies, exactly to avoid the problem of proteins which share part of the sequence and/or the structure and function.
The paper you refer to (the third one) is an example of èprotein engineering at the active site level to "evolve" an activity which is already potentially present in the superfamily. You can check that beta lactamases and D-Ala carboxy peptidases are part not only of the same superfamily, but also of the same family, in SCOP classification.
As I have said many times, transitions which imply a limited number of mutations at the active site in a same family/superfamily are perfectly possible, and some of them could in principle be in the theoretical range of what random variation can achieve. That has always been a clear point in my discussions.
That said, the artificial transition realized in that paper required a lot of complex protein engineering anyway.
The fact cremains that when I discuss new superfamilies, I discuss the appearance of new superfamilies, and not the minor transitions inside a superfamily or family.
So, when I say that beta lactamase has 336 bits of functional information, I am referring to the protein family, not to an individual member of it. The functional information implies the general fold and the general structure, and not only the active site, where we know well that transitions of a few aminoacids can shift the affinity for specific substrates, always in the context of that functional superfamily.
So, while I don't think that the artificial transition illustrated in the paper is proof of a real transition which happened in natural history (although I remain open to the possibility), it is in no way a case of a new superfamily (of the 2000 we know of) arising through some gradual pathway.
So yes, my procedure has 100% specificity.gpuccio
October 12, 2014
October
10
Oct
12
12
2014
10:34 AM
10
10
34
AM
PDT
Mark:
My7 reasoning is simple and explicit. You don't accept it, but I cannot do anything about that.
The functional specification is the number of bits necessary to implement an explicitly defined function. There are a lot of functions which are simple, and could be implemented by many types of strings. Other functions are complex, and they require a lot of specific bits to be implemented.
Those functions are observably, always the result of conscious intentional design. That's what observed facts tell us. Only a conscious designer can achieve the intentional configuration of a high number of specific bits to implement a function.
The simple fact is that all complex functions are designed. That's why my procedure works.
So, the effect we observe in the scenario I have proposed is "a protein which can implement this complex function". And we compute the probability for that protein to arise as a result of random variation.
The same procedure works for any complex function.gpuccio
October 12, 2014
October
10
Oct
12
12
2014
10:11 AM
10
10
11
AM
PDT
gpucio, congrats on still quantifying design, where others here have casted doubt on quantification of information.
We could discuss how you determine the functional percentage of sequence space, when it is impossible to construct anything but a scant portion of all possible constructs.
We could also consider the "necessity" of evolving any given activity.
But I'll focus on one issue here: "expresses the probability of getting one functional string by a single variation event, in a random search/random walk, starting from an unrelated state" is precisely nobody's model of how life works.
B-lactamases, which you conclude have 2^336 (of whatever metric you're using today) are related in form and function to the peptidases that penicillin and related drugs inhibit. They carry out virtually the same reaction, except that the peptidases get stuck (dead bacteria) and the beta-lactamases recruit a water molecule to break the bond with the drug, destroying it.
How many mutations does this refinement of function take? Looks like a minimum of 3. How many bits is that?
Does your procedure have 100% specificity, and no risk of false positives?
http://www.cell.comchemistry-biology/abstract/S1074-5521(96)90182-9
http://www.ncbi.nlm.nih.gov/pmc/articles/PMC1220374/pdf/10393100.pdf
http://peds.oxfordjournals.org/content/16/1/27.longREC
October 12, 2014
October
10
Oct
12
12
2014
10:04 AM
10
10
04
AM
PDT
GP #214 Your response covers the whole of how you infer design.
Although, as you know, I disagree with your design inference, that is not the specific issue I was addressing. All I want to establish is that you cannot rationally reject the random variation hypothesis without having an H1 in mind. The proof is easy. You say beta lactamase has a functional specification of 336 bits and therefore the probability of reaching that string exceeds the probabilistic resources of the system. But so does every other possible string of that length. If a string of that length is generated by a random system than the resulting string must be a string “exceeds the probabilistic resources of the system.” We would not reject the random explanation if it were any string of that length. Why do we use it to reject H0 just because it is functional? Or to put it another way – on what basis do you ascribe a tiny p value to this string and not to all the others of that length? In the case of Fisherian hypothesis testing you did it on the basis of being at least as extreme – I don’t agree with this – but this example doesn’t even satisfy that criterion.Mark Frank
October 12, 2014
October
10
Oct
12
12
2014
09:59 AM
9
09
59
AM
PDT
Mark:
OK, here is the important point.
In my discussions about dFSCI, I have always made it clear that I deal with a specifically defined function, and I compute the probability of getting that functionality in an object by random variation in the system. You must, for now, accept this as a procedure. I am not, for the moment, inferring anything from it.
So, if I have an enzyme which catalyzes some specific reaction, I define the function (giving if necessary detailed ways to measure it in controlled conditions), and then I try to compute how many sequences of AAs of the same length can implement the function. I call functionally specified information (dFSI) in the observed object (the protein which implements the function) the ratio target space/search space (or better, -log2 of that ratio).
OK? These are definitions, nothing more. As you know, I believe that the values given in the Durston paper are good approximations of that measure.
As you can see, all my reasoning is specific to one functional definition. I am not considering all possible specifications. I am considering one definite functional specification. And I am computing the minimum number of bits necessary to implement it, at the best of our understanding.
OK?
So, I have a number. For example, for beta lactamase, according to Durston's data, I can say that the functional specification is 336 bits.
What does that number mean?
It expresses the probability of getting one functional string by a single variation event, in a random search/random walk, starting from an unrelated state. If no other non random factors intervene, and assuming an uniform distribution of the probability of all possible states in the random search/random walk.
OK?
Now, we know that the protein emerged in a system in a time span. We can grossly compute the probabilistic resources of the system in the time span. The total number of attempts (new states reached).
So we can compute the probability of obtaining at least one success in that system, only as the result of random variation, with those probabilistic resources: for beta lactamase, it is about 1e-62. That is the p value for our observed result (a protein which implements the defined function) in our system, if our H0 (only random variation) is true. This value is referred to the function: beta lactamase. Success is defined as the presence of that function, and the probability is computed by the binomial distribution.
OK?
Now, my point is, any time that any specific functional definition (you can define all the functions you like) requires a sufficiently high number of bits to be implemented (has a sufficiently high functional specification), IOWs exhibits dFSCI, so that the value of its dFSI is so big that it is vastly greater than the probabilistic resources of the system, and the p value computed in the way I have described is extremely small (1e-62 certainly qualifies), then we can safely reject random generation as an explanation, and, if no other credible explanation based on reasonable necessity "contributions" is available, we can safely infer design.
I know your objection. You say that we should consider "all possible functions" or "all possible specifications", and that my procedure does not work.
I have two different ways to counter that.
The first is that, even if it were true (and it is not) that there are so many possible functions (useful in the context, which means naturally selectable, for our context) that finding some functional sequence becomes reasonably likely, the specific sequences we observe remain however extremely unlikely.
So, let's say that we have a target space of many "naturally selectable functions" (!!!). OK, let's suppose that for a moment. The whole target space has a probability of being found, in one attempt, say of 150 bits, which would put it borderline with my proposed threshold for a biological system. OK, let's say that it is possible that in the course of natural history that target space may be hit a few times.
A subset of that target space is our beta lactamase, with its individual probability of 336 bits. Of course, as you can understand, that is really a tiny fraction of the whole target space. The target space, indeed, is made almost entirely of much simpler proteins, which are functional and much more likely.
So, even if the target space is luckily hit a few times in the course of natural history, what proteins will be found? Certainly the simpler ones, not certainly the "complex" beta lactamase, which is only a super-tiny part of the target space.
And I am not discussing proteins like ATP synthase, or dyneins, whose functional complexity ranges in the thousands of bits, and which would be a super-tiny part of any set of proteins as likely as beta lactamase!
And yet, those are exactly the proteins which we found abundantly represented in the existing proteome.
IOWs, if a functional result is really unlikely, it is perfectly correct to reason about the probability of getting that specific result. The fact that some simpler functional results, with different and simpler functions, may certainly exist, is no help in explaining that we find that specific complex function implemented in the proteome.
My second type of answer is much more simple and empiric: the procedure works.
If we apply exactly my procedure to any possible functional sequence which is designed, and has enough functional specification, I will detect design correctly in all cases in which I detect it, without any false positive (and possibly with many false negatives). I am always ready to accept that challenge. You simply cannot offer any example of a false positive.
So, I will recognize any passage in correct English of sufficient length, and I will never be fooled by randomly generated sequences of characters. Even if in theory some sequence of characters could be specified in who know what way, that does not change the simple fact that I will recognize the designed English passages of sufficient length, and I will never be wrong.
The procedure works, and it has 100% specificity. All your "doubts" cannot change that simple fact.gpuccio
October 12, 2014
October
10
Oct
12
12
2014
09:13 AM
9
09
13
AM
PDT
Mark:
"There is a probability of 0.01 of seeing a result as least as extreme if the two variables are really independent."
OK, that is more correct. :)
So, I think that we agree enough on the statistical details, after our clarifications. Now, I will try to answer your #211 about the application to ID.gpuccio
October 12, 2014
October
10
Oct
12
12
2014
08:33 AM
8
08
33
AM
PDT
GP at #210
You say:
H0 is an intrinsically statistical explanation, …..
My point was not that H0 is not statistical – just that H1 is also statistical – so this paragraph is irrelevant.
Let’s say that we have a sample of 100 males and a sample of 100 females, and we measure a continuous variable A in both groups. We find that A is higher in males, both its mean and its general distribution.
So, is A dependent on sex?
Our H0 is that the two variables are independent, and that the higher values in males are simply explained by the normal variance of the variable in the original population, and by the random variance in sampling.
OK, if our p is 0.01, we can discuss. After all there is one probability in 100 that the two variables are really independent.
I hope that was careless error. There is a probability of 0.01 of seeing a result as least as extreme if the two variables are really independent. That is quite a different thing. But I assume you know that.
But if our p is 10e-20, who would still believe that the two variables are really independent? Not I.
It depends on how the rejection region was defined. I have already shown that the rejection region can be defined in different ways depending on your H1. However, I admit that if the region was defined as “more extreme” and it was this low a probability I would reject H0. But the important thing is to understand why. Otherwise you may transfer the same logic to other situations such as ID where it does not follow (see previous comment). There are an infinite number of other rejection regions with just as low a probability. Why is the extreme region grounds for rejection and not say the very thing slice around zero which is just as low a probability? The reason is very straightforward. The extreme value is more likely if the variables are dependent than if they are independent, while that is not true of the central slice. There is nothing difficult about this but you must recognise the logic before you can transfer it to another case or you will go badly wrong.Mark Frank
October 12, 2014
October
10
Oct
12
12
2014
08:24 AM
8
08
24
AM
PDT
GP at #209 Let's get straight to the ID example. This relates directly to my #199.
Can the effect we observe be reasonably explained as the result of random variation in the system? IOWs, given the system, the time span, and the probabilistic variation in the system, what are the probabilities of having such an effect?
The rejection region can be easily defined as the probability of having at least one success in n attempts (the total number of new states tested in the time span), each of them with probability p of success. In this case, success is the appearance of a protein coding gene for the specific functional protein we are observing.
So, as you can see, our H0 and our rejection region are well defined, without any detail about alternative hypotheses.
Let as assume that we are talking about a string of DNA 100 base pairs long and the effect is one particular configuration. “Random variation” presumably means any of the four base pairs is equally likely at any point in the string and are independent of each other – which is our H0. Your problem, as you well know, is that every possible string is equally likely under H0. They each have a probability of 4^100 in one trial (I will ignore multiple trials for the moment). So you have to explain why some strings are justification for rejecting H0 and others are not.
The classic ID response is that the strings that justify rejection are specified (in your case functionally specified). But for any given string:
* You don’t know for certain that it is not specified in some way (maybe not functionally but perhaps it is a coded representation of a Sanskrit poem)
* If you think of all the different ways string can be specified it is reasonable to suppose that most, if not all, strings are specified in some way
So now you have to explain why your particular specification is grounds for rejection while other specifications are not. If there was a plausible alternative explanation why that particular string was created (e.g. it was the result of combining two existing strings) then that would clearly be a justification for rejecting H0 – but that would be an H1. Your challenge is to explain why H0 would be rejected for that particular string without using an alternative explanation.Mark Frank
October 12, 2014
October
10
Oct
12
12
2014
08:12 AM
8
08
12
AM
PDT
Mark at #208:
You say:
"I don’t see at all why H0 is statistical and H1 are not. It is extremely common for H1 to be an explanation in its own right with its own pdf e.g. it might just be an alternative population mean."
What do you mean?
H0 is an intrinsically statistical explanation, because it assumes that the effect we observe has no other cause than random events in the system which are not causally connected to the effect. IOWs, we observe the effect only because, by chance, many independent variables which have no cause and effect relationship with the observed effect happened to generate a configuration which simulates the effect.
Let's say that we have a sample of 100 males and a sample of 100 females, and we measure a continuous variable A in both groups. We find that A is higher in males, both its mean and its general distribution.
So, is A dependent on sex?
Our H0 is that the two variables are independent, and that the higher values in males are simply explained by the normal variance of the variable in the original population, and by the random variance in sampling.
OK, if our p is 0.01, we can discuss. After all there is one probability in 100 that the two variables are really independent.
But if our p is 10e-20, who would still believe that the two variables are really independent? Not I.
WE may have no idea of why A is higher in males, but anybody in a sane mind will be empirically sure that it is higher in males, whatever the explanation.
It's as simple as that.gpuccio
October 12, 2014
October
10
Oct
12
12
2014
04:48 AM
4
04
48
AM
PDT
Mark:
I agree with some of the things you say in your post #207 (not all). Anyway, I think they are really irrelevant, especially if applied to ID.
Let's begin with the two tailed/one tailed problem. That is essentially a problem of methodology, and it depends on what we are interested in, what we consider relevant, rather than on our explanation of what we observe.
As I have said, we have to decide in advance what effect size we consider relevant. That is valid both for the size of the effect and for its direction. It is a problem of what we are interested in, not of how we explain it. It has nothing to do with H1.
In general, if our purpose is to understand, and we have no pre-commitments, a two tailed test will give the highest guarantees.
Regarding your discussion about "detecting fraud in the trials", I don't know, I am not an expert in detecting trials, and I suppose a specific methodology is needed, but again the problem is not in H1, but in the question we have when we approach the problem.
You say:
"There is a very low probability that the two sample means should be extremely close to zero even if they are drawn from the same population."
I suppose you are saying that there is a very low probability that the difference between two sample means should be extremely close to zero. Of course, it would be very suspicious if, say, two sample means of two samples with 100 values each and some reasonable variance were exactly the same, up to the tenth decimal digit. That would smell, very simply, of a strange stupidity in the author of the fraud! So, if we want to detect stupid frauds, that would be a good method. For normal frauds, we need something better.
However, what has that to do with design detection? In design detection, our question when we decide if we reject H0 is very clear and very simple. I repeat it for you:
Can the effect we observe be reasonably explained as the result of random variation in the system? IOWs, given the system, the time span, and the probabilistic variation in the system, what are the probabilities of having such an effect?
The rejection region can be easily defined as the probability of having at least one success in n attempts (the total number of new states tested in the time span), each of them with probability p of success. In this case, success is the appearance of a protein coding gene for the specific functional protein we are observing.
So, as you can see, our H0 and our rejection region are well defined, without any detail about alternative hypotheses.gpuccio
October 12, 2014
October
10
Oct
12
12
2014
04:38 AM
4
04
38
AM
PDT
GP
A very quick response to #206. I don't see at all why H0 is statistical and H1 are not. It is extremely common for H1 to be an explanation in its own right with its own pdf e.g. it might just be an alternative population mean.
More importantly - you write:
An explanation where what we observe has only 10e-62 probabilities of happening by chance is not an explanation at all.
As explained in #207 what we observe can have any probability depending on the rule we use to define the rejection region. It is not an observation that has a probability but a range defined by the observation. That range is often (but not always) "more extreme". The choice of that range can only justified by assuming an alternative hypothesis.Mark Frank
October 12, 2014
October
10
Oct
12
12
2014
04:07 AM
4
04
07
AM
PDT
Gpuccio
I will try to explain this as concisely as I can but it the comment will be a lot longer than I would like.
First let me explain the rather strange test statistic that I used. I wanted to create a test statistic that was an ordered set of Bernoulli trials to make it as close as possible to the kind of “string” that is routinely discussed in ID. I admit that the usual way of testing if a treatment works would be to simply give the treatment to one population and the placebo to another and use something like a chi squared test.
Now let me try to explain the problem with classic Fisherian hypothesis testing. This is very hard to do without a picture so bear with me.
Take a simple Student’s t-test for comparing the means of two unmatched samples. The value of the test statistic (what you call the effect size) could vary from minus infinity to plus infinity. H0 is: the two samples are drawn from the same population and therefore the two samples have the same population mean. Suppose we get fairly large positive effect size x (I can’t be bothered to do the maths). It makes no sense to talk of the probability of that particular value. It is single point in an infinite range. So we have to use it define a rejection region – an interval in the range of possible effect sizes – and calculate the probability of the effect size falling into the rejection region – we call that probability the p-value. Typically we define the rejection region, as you did, as any value more extreme than x. But in this case there are two extremes – very low and very high. Sometimes we use both (a two-tailed test) and sometimes we use just one (a one-tailed test). We will get different p-values according to which choice we make. How do we justify the choice? By deciding what H1 is. Is H1: population X has a greater mean than population Y? Or is it: population X is different from population Y. So under one H1 we may reject H0 and under another we may not. That is why every good statistics text book insists you make H1 explicit as well as H0.
But it goes further than this. Why should the rejection region be extremes at all? The observed effect size will fall into infinitely many different intervals with widely varying p-values. What if our interest is in detecting fraud in the trials - we think the experimenter might have been trying to show that the treatment has no effect. In this case we will be looking to see if the effect size is suspiciously close to zero. There is a very low probability that the two sample means should be extremely close to zero even if they are drawn from the same population. So you might define a rejection of region of “at least as close to zero as the effect size”. What if the effect size is measured in days to recovery from diagnosis and the treatment under test is administered two days after diagnosis. We might well reject H0 if the sample effect size were suspiciously close to two days even if this is not a particularly extreme value. So we might define a rejection region of “at least as close to 2 days as the sample effect size”. And so on. In all these cases the justification of the rejection region is determined by H1.
Please understand that I fully accept that in the vast majority of cases we will reject H0 based on a rejection region “at least as extreme as”. I just want to argue that in doing so we are implicitly assuming a certain H1 which in odd cases may be different. This assumption becomes key when you extend the argument to ID.
This all deals with a continuous case because most of the examples you offered were continuous. Of more relevance to ID is where the test statistic is a discrete value such as the number of times the Democratic candidate comes top of the polling list (to use Dembski’s example). But I will offer this for the moment and if time allows extend it to the discrete case later.Mark Frank
October 12, 2014
October
10
Oct
12
12
2014
03:11 AM
3
03
11
AM
PDT
Mark:
While I wait for your clarifications, I will try to sum up the key points (IMO):
H0 is a null hypothesis. Its essence is that some effect that we observe (in general, some form of apparent regularity or rule) is not true: it can be explained by some kind of random fluctuation on the system, which has no real causal relationship with the supposed regularity or rule that we believe we are observing.
IOWs, as what we observe is only a pseudo-effect, it is not a reproducible aspect of reality. That means that we cannot make any prediction based on it, because in a different sample it will disappear.
To be credible as an explanation (IOWs, to accept that there is no other explanation needed for what we observe) the null hypothesis must have explanatory power: that means that the random variance in the system must be great enough to be able to generate the observed configuration with some probability. We are discussing a random explanation, and the key of randomness is probability. A random explanation which is utterly improbable has no explanatory power. IOWs, it is not an explanation at all.
Therefore, the rejection of H0 depends exclusively on its lack of any credible explanatory power. An explanation where what we observe has only 10e-62 probabilities of happening by chance is not an explanation at all. IOWs it must be rejected, and other explanations, not based on random events, must be searched.
H1 (or any alternative hypothesis) is all another matter. The rejection of H0 is never in itself an affirmation of H1, unless H1 is formulated as the logical alternative to H0 (for, example, in very general terms, as "What we observe is not the result of random variation in the system").
If H1 is a specific explanation (for example, A is the cause of what we observe) it must be evaluated on its own merits and explanatory power. Here, probability is no more the measure, because H1 is not a probabilistic explanation. While you, as a Bayesian, can certainly attribute some probability to H1, H2 and so on, the fact remains that even those probabilities depend on the specific explanatory merits of the different hypotheses, and not on their probabilistic properties, because they are not explanations based on probability distributions.
For example, I may offer as explanation that A is the cause of what we observe. Then, I must ask:
a) Is it logically consistent that A can cause what we observe? IOWs, are there logic contrdictions in my explanation?
b) Is it empirically credible that A is the cause of what we observe? IOWs, is there some empirical support to my explanation?
c) Are there better non random explanations fpr what we observe?
All those questions are not in themselves probabilistic, although you can, if you like, assign probabilities to the answers (I would not do that, because as you know I am not a Bayesian).
For me, those questions are methodological and cognitive questions, which require answers based on cognition and intuition, and not on probability.
So, to sum up:
1) H0 is an intrinsically probabilistic explanation, and it is rejected (or not rejected) according to its intrinsically probabilistic explanatory powers.
2) H1, H2 and so on are alternative, causal explanations for what we observe. They are evaluated for their own explanatory merits, and we choose what is the best explanation (in the present context) according to that evaluation.
Of course, that choice is in some measure a personal choice, but it can certainly be shared and be a matter of intellectual confrontation.
[--> ED: minor typo cleanup, KF]gpuccio
October 12, 2014
October
10
Oct
12
12
2014
01:35 AM
1
01
35
AM
PDT
Stephen,
Thank you! I am so happy that we understand each other well. :)gpuccio
October 12, 2014
October
10
Oct
12
12
2014
01:03 AM
1
01
03
AM
PDT
GPuccio, just in case my earlier message got lost in the shuffle, I wanted to thank you again for clarifying your approach and the reasons for it. It makes perfect sense to me. I understand now why you define function in subjective terms and why you differentiate it from objective functionality. I make the same distinction with different words for different reasons. You are right. It is simply a difference in methodologies (and temporary objectives)StephenB
October 11, 2014
October
10
Oct
11
11
2014
06:00 PM
6
06
00
PM
PDT
Mark:
I think according to what I see. If you say wrong things, I think that you have a wrong understanding (I have full confidence in your good faith and seriousness).
I have tried to explain clearly my points. I do believe they are correct and they work. You say you did not explain well your points, and you will do that tomorrow. I am waiting.gpuccio
October 11, 2014
October
10
Oct
11
11
2014
03:13 PM
3
03
13
PM
PDT
Gpuccio
Do you really think I don't understand basic statistical methods? What you need to understand is the fundamental assumptions underlying these methods - why they work (and sometimes don't). I clearly did not explain it well at my first attempt. I will try again tomorrow.Mark Frank
October 11, 2014
October
10
Oct
11
11
2014
02:56 PM
2
02
56
PM
PDT
Mark:
I am afraid that you misunderstand many things.
You say:
"First – let’s not confuse sampling and the underlying hypothesis. H0 is not “due to random sampling”."
You don't understand.
Let's suppose that we have, for example, two samples, and that we do observe a difference between them in the values of some measured variable.
We call the observed difference "the effect size", and quantify it in some ways. It can be a difference in mean and distribution.
Or, if we compare two continuous variables, the effect is their correlation, and the effect size can be measured, for example, by the R square value in linear regression.
If we observe no relevant effect, there is no game.
But, if we observe an effect whose size is relevant for our purposes (clinical, methodological, or whatever), then we wonder:
"Is the effect we observe a real effect, that we have to explain in some way, or is it only the result of random variance?"
Usually, in clinical experiments, the random variance we refer too is the random variance in the original population from which the samples were taken.
So, our H0 is that the two samples are from some homogeneous population (for the variable we are considering), and that other factors do not make any difference.
So, any difference observed in our two samples is due to the random variance of the original population. That is H0. It is the hypothesis that what we observe is explained by random variation.
The p value is a blending of the effect size and of the numerosity of the samples. It tells us how likely it is to observe the effect that we are observing (or a greater one) if H0 is true.
If the p value is very low, and the effect size is relevant for us, we can rather safely reject H0 (the lower the p value, the safer the rejection).
That has nothing to do with H1, H2, and so on.
If we reject H0, we know that we are (most likely) observing a true effect, and not only a pseudo effect. That effect we must try to explain. And there may be many possible explanations for it. The choice between explanations is usually not so much a question of probability, but a methodological evaluation: how well does our explanation explains, given all that we know? It is a cognitive choice, and not a probability.
In your example of the RCT, I really don't understand what you are saying. What has the string to do with it? In that case, we are interested in how many patients have a sense of improvement when they take the treatment, compared with how many patients have it when tehy take placebo. It is a very easy evaluation, just a 2x2 table which can be evaluated by a chi square test for independence: is the binary variable treatment/no treatment independent from the binary variable improvement/no improvement? Again, a very low p value will tell us that the two variables are most likely connected. The effect size here is simply a comparison between proportions.
What has that to do with design detection?
In design detection, our effect is the functionality in the string, and our effect size is measured by the bits of functional information linked to that function.
Our H0 is that the particular string we observe, with its functional sequence, arose as the result of random variation in the system.
If our p value for that hypothesis is really low (like in the example of beta lactamase), we can very safely reject H0.
It's as simple as that.gpuccio
October 11, 2014
October
10
Oct
11
11
2014
10:57 AM
10
10
57
AM
PDT
MF: In relevant cases there are often many ways for an object to be in relevant functional clusters of states. The problem is, there may be far, far more for it not to be; as is so for FSCO/I -- relatively few ways for reel parts to make a viable reel, many more for them to not. As a consequence, a blindly sampled state or set of states up to the atomic capacity of the solar system or observed cosmos, can only sample so small a fraction that the outcomes will reliably reflect the bulk of the pattern. And the classic Fisherian testing typically identifies a far skirt as a zone of interest then asks in effect, for reasonable sampling tries, what will we likely see. Answer the bulk, and it becomes so unlikely to pick up the far skirt that way that with a relevant degree of confidence, we may suggest whether or no the null hyp --we are in the far skirt by chance typically -- is not credibly true. As is a commonplace. KFkairosfocus


It may be entertaining to play semantics games with terms like function, but that simply reveals that your problem is not with science, it is with common sense reality tracing to some of the sillier bits of post-modernist radical subjectivism and deconstructionism.
Perhaps, it has not dawned on you that survival of the fittest or hill-climbing algorithms or natural selection or the like pivot on the objectivity of function. Have you gone to Panda’s Thumb, TSZ, ATBC or the like Darwinist agitator sites to challenge the core concepts of evolution based on differential reproductive success pivoting on functional differences of life-forms? I safely bet not, you are reserving such talking-points for those you object to, regardless of inconsistencies or outright incoherence.
[Ill-]Logic with a swivel.
Patently, revealingly, sadly, you have indulged in incoherent selective hyperskepticism.
And if you genuinely imagine that a stalled car with a dead engine, or a leaky roof, or a crashed computer, or a PA system that distorts sounds horribly are functionally distinct as a mere matter of subjective opinion, your problem is a breach of common sense.
Do you — or a significant other — have a mechanic? Are you a shade-tree mechanic? Do you have even one tool for maintenance? Do you recognise the difference between sugar, salt and arsenic in your cup of coffee? Between an effective prescription correctly filled and faithfully carried out when you get sick and a breakdown of that process? Etc?
I put it to you that you cannot and do not live consistent with your Lit class seminar-room talking points.
And, your evasive resort to clinging to such absurdities to obfuscate the issue of functionally specific, complex organisation and associated information, speaks loudest volumes for the astute onlooker.
Own-goal, E-S.
The bottom-line of the behaviour of several objectors over the past few days, speaks inadvertent volumes on the real balance on the merits of the core design theory contention that there are such things as reliable empirical markers — such as Wickensian FSCO/I — that are strong signs of design as key causal process.
But, many are so wedded to the totalising metanarrative of a priori Lewontinian evolutionary materialism that they refuse to heed the 2350 year old warning posed by Plato on where cynical radical relativism, amorality opening the door to might makes right nihilism and ruthless factions points to for a civilisation. Refusing to learn the hard-bought, paid for in blood lessons of history, they threaten to mislead our civilisation into yet another predictably futile and bloody march of folly. As the ghosts of 100 million victims of such demonically wicked deceptions over the past century warn us.
The folly on the march in our day is so arrogantly stubborn that it refuses to learn living memory history or the history passed on first hand to our grand parents.
Here is Sophia (personification of Wisdom), in the voice of Solomon echoing hard-bought, civil war triggered lessons in Israel c 1,000 BC:
A grim warning, bought at the price of a spoiled, wayward son who fomented disaffection and led rebellion triggering civil war and needless death and destruction, ending in his own death and that of many others.
Behind the Proverbs lies the anguished wailing of a father who had to fight a war with his son and in the end cried out, Oh Absalom, my son . . .
History sorts out the follies of literary excesses, if we fail to heed wisdom in good time.
Often, at the expense of a painful, bloody trail of woe and wailing that leads many mothers and fathers, widows and orphans to wail the loss of good men lost to the fight in the face of rampant folly.
But then, tragic history is written into my name, as George William Gordon’s farewell to his wife written moments before his unjust execution on sentence of a kangaroo court-martial, was carried out:
Deconstruct that, clever mocking scorners of the literary seminar room.
Deconstruct it in the presence of a weeping wife and mother and children mourning the shocking loss of a father and hero to ruthless show-trial injustice ending in judicial murder.
Murder that echoes the fate of one found innocent but sent to Golgotha because of ruthless folly-tricks in Jerusalem c. 30 AD.
(How ever so many fail to see the deep lesson about folly-tricks in the heart of the Gospel, escapes me. New Atheists and fellow travellers, when you indict the Christian Faith as the fountain-head of imagined injustice, remember the One who hung between thieves on a patently unjust sentence, having been bought at the price of a slave through a betrayer blinded by greed and folly. If you do not hear a cry for just government and common decency at the heart of the Gospel you would despise, you are not worth the name, literary scholar or educated person.)
And in so doing, learn a terrible, grim lesson of where your clever word games predictably end up in the hands of the ruthless.
For, much more than science is at stake in all of this.
GEM of TKI >>