A current rhetorical tack of objections to the design inference has two facets:
(a) suggesting or implying that by moving research focus to Active Information needle in haystack search-challenge linked Specified Complexity has been “dispensed with” [thus,too, related concepts such as FSCO/I]; and
(b) setting out to dismiss Active Information, now considered in isolation.
Both of these rhetorical gambits are in error.
However, just because a rhetorical assertion or strategy is erroneous does not mean that it is unpersuasive; especially for those inclined that way in the first place.
So, there is a necessity for a corrective.
First, let us observe how Marks and Dembski began their 2010 paper, in its abstract:
Needle-in-the-haystack problems look for small targets in large spaces. In such cases, blind search stands no hope of success. Conservation of information dictates any search technique will work, on average, as well as blind search. Success requires an assisted search. But whence the assistance required for a search to be successful? To pose the question this way suggests that successful searches do not emerge spontaneously but need themselves to be discovered via a search. The question then naturally arises whether such a higher-level “search for a search” is any easier than the original search. We prove two results: (1) The Horizontal No Free Lunch Theorem, which shows that average relative performance of searches never exceeds unassisted or blind searches, and (2) The Vertical No Free Lunch Theorem, which shows that the difficulty of searching for a successful search increases exponentially with respect to the minimum allowable active information being sought.
That is, the context of active information and associated search for a good search, is exactly that of finding isolated targets Ti in large configuration spaces W, that then pose a needle in haystack search challenge. Or, as I have represented this so often here at UD:
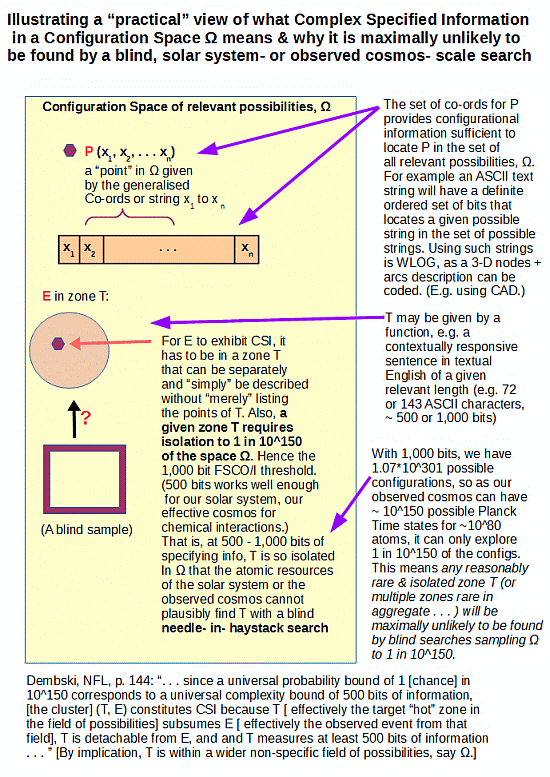 Updating to reflect the bridge to the origin of life challenge:
Updating to reflect the bridge to the origin of life challenge:
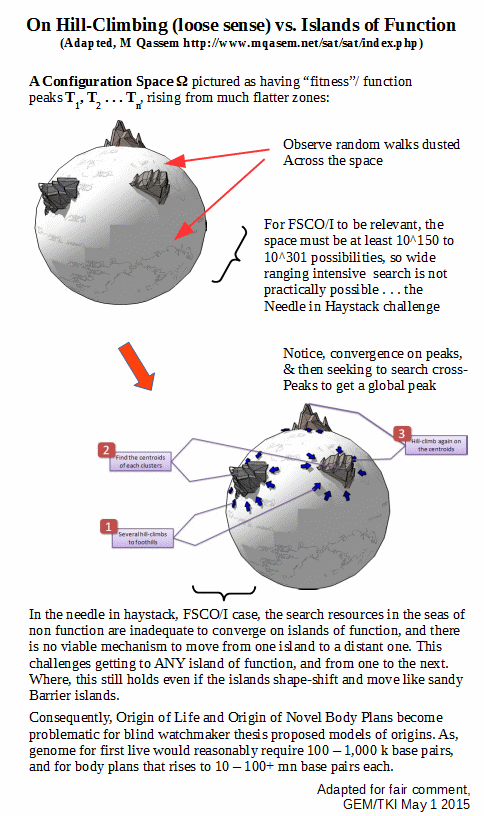
In this model, we see how researchers on evolutionary computing typically confine their work to tractable cases where a dust of random walk searches with drift due to a presumably gentle slope on what looks like a fairly flat surface is indeed likely to converge on multiple zones of sharply rising function, which then allows identification of likely local peaks of function. The researcher in view then has a second tier search across peaks to achieve a global maximum.
This of course contrasts with the FSCO/I [= functionally specific, complex organisation and/or associated information] case where
a: due to a need for multiple well-matched parts that
b: must be correctly arranged and coupled together
c: per a functionally specific wiring diagram
d: to attain the particular interactions that achieve function, and so
e: will be tied to an information-rich wiring diagram that
f: may be described and quantified informationally by using
g: a structured list of y/n q’s forming a descriptive bit string
. . . we naturally see instead isolated zones of function Ti amidst a much larger sea of non-functional clustered or scattered arrangements of parts.
This may be illustrated by an Abu 6500 C3 fishing reel exploded view assembly diagram:
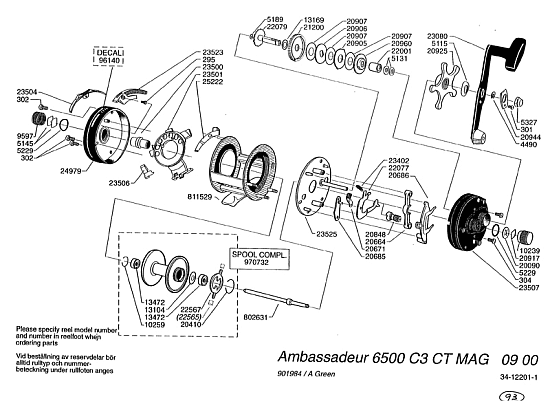
. . . which may be compared to the organisation of a petroleum refinery:

. . . and to that of the cellular protein synthesis system:
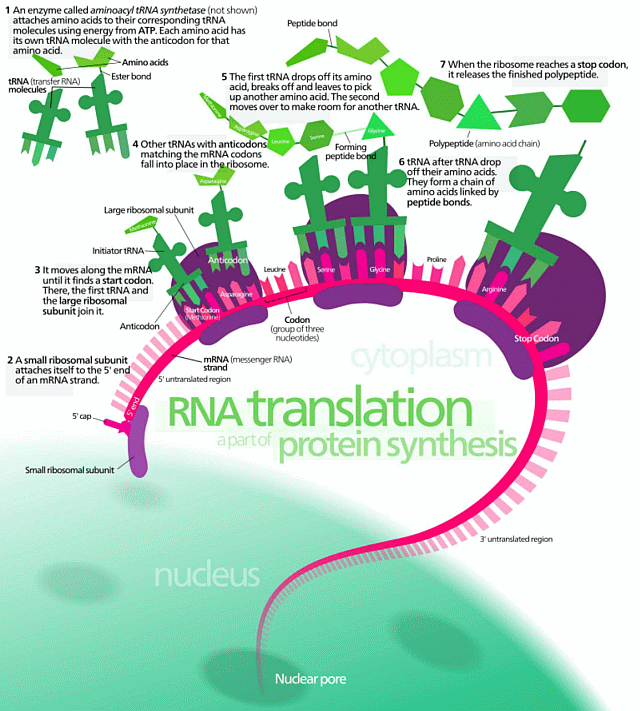
. . . and onward the cellular metabolic process network (with the above being the small corner top left):
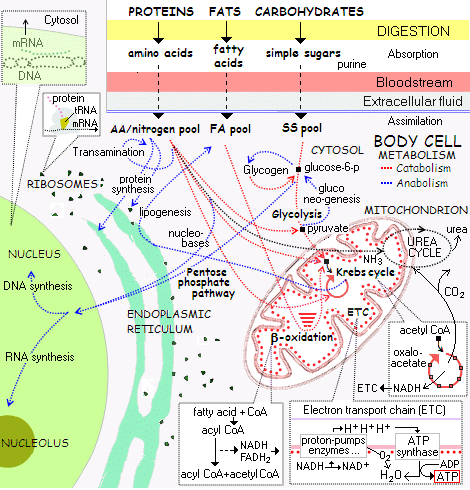
(NB: I insist on presenting this cluster of illustrations to demonstrate to all but the willfully obtuse, that FSCO/I is real, unavoidably familiar and pivotally relevant to origin of cell based life discussions, with implications onward for body plans that must unfold from an embryo or the like, OOL and OOBP.)
Now, in their 2013 paper on generalising their analysis, Marks, Dembski and Ewert begin:
All but the most trivial searches are needle-in-the-haystack problems. Yet many searches successfully locate needles in haystacks. How is this possible? A success-ful search locates a target in a manageable number of steps. According to conserva-tion of information, nontrivial searches can be successful only by drawing on existing external information, outputting no more information than was inputted [1]. In previous work, we made assumptions that limited the generality of conservation of information, such as assuming that the baseline against which search perfor-mance is evaluated must be a uniform probability distribution or that any query of the search space yields full knowledge of whether the candidate queried is inside or outside the target. In this paper, we remove such constraints and show that | conservation of information holds quite generally. We continue to assume that tar-gets are fixed. Search for fuzzy and moveable targets will be the topic of future research by the Evolutionary Informatics Lab.
In generalizing conservation of information, we first generalize what we mean by targeted search. The first three sections of this paper therefore develop a general approach to targeted search. The upshot of this approach is that any search may be represented as a probability distribution on the space being searched. Readers who are prepared to accept that searches may be represented in this way can skip to section 4 and regard the first three sections as stage-setting. Nonetheless, we sug-gest that readers study these first three sections, if only to appreciate the full gen-erality of the approach to search we are proposing and also to understand why attempts to circumvent conservation of information via certain types of searches fail. Indeed, as we shall see, such attempts to bypass conservation of information look to searches that fall under the general approach outlined here; moreover, conservation of information, as formalized here, applies to all these cases . . .
So, again, the direct relevance of FSCO/I and linked needle in haystack search challenge continues.
Going further, we may now focus:
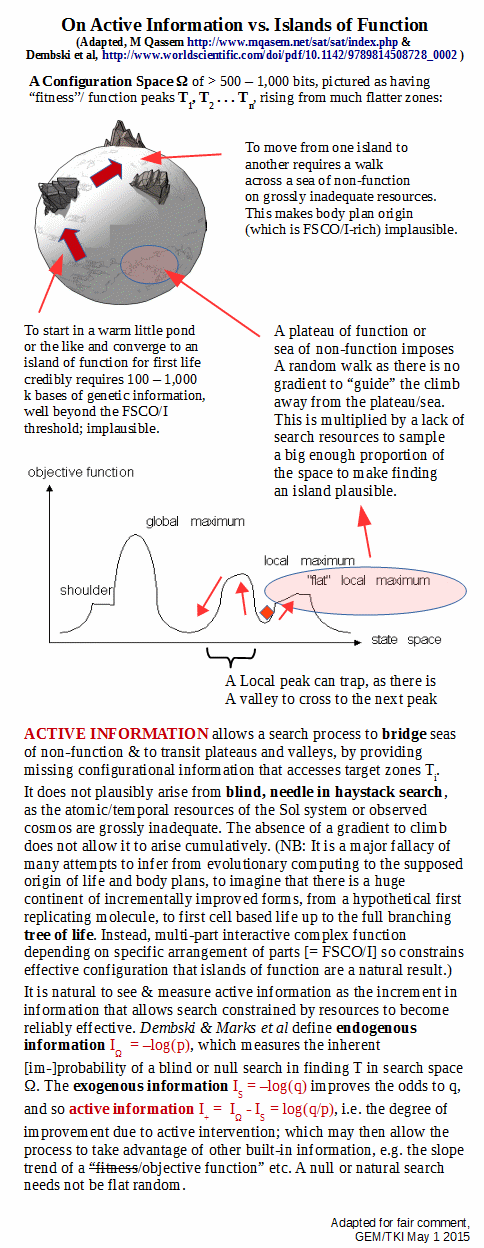
In short, active information is a bridge that allows us to pass to relevant zones of FSCO/I, Ti, and to cross plateaus and intervening valleys in an island of function that does not exhibit a neatly behaved objective function. And, it is reasonable to measure it’s impact based on search improvement, in informational terms. (Where, it may only need to give a hint, try here and scratch around a bit: warmer/colder/hot-hot-hot. AI itself does not have to give the sort of detailed wiring diagram description associated with FSCO/I.)
It must be deeply understood, that the dominant aspect of the situation is resource sparseness confronting a blind needle in haystack search. A reasonably random blind search will not credibly outperform the overwhelmingly likely failure of the yardstick, flat random search. Too much stack, too few search resources, too little time. And a drastically improved search, a golden search if you will, itself has to be found before it becomes relevant.
That means, searching for a good search.
Where, a search on a configuration space W, is a sample of its subsets. That is, it is a member of the power set of W, which has cardinality 2^W. Thus it is plausible that such a search will be much harder than a direct fairly random search. (And yes, one may elaborate an analysis to address that point, but it is going to come back to much the same conclusion.)
Further, consider the case where the pictured zones are like sandy barrier islands, shape-shifting and able to move. That is, they are dynamic.
This will not affect the dominant challenge, which is to get to an initial Ti for OOL then onwards to get to further islands Tj etc for OOBP. That is doubtless a work in progress over at the Evolutionary Informatics Lab, but is already patent from the challenge in the main.
To give an outline idea, let me clip a summary of the needle-to-stack challenge:
Our observed cosmos has in it some 10^80 atoms, and a good atomic-level clock-tick is a fast chem rxn rate of perhaps 10^-14 s. 13.7 bn y ~10^17 s. The number of atom-scale events in that span in the observed cosmos is thus of order 10^111.
The number of configs for 1,000 coins (or, bits) is 2^1,000 ~ 1.07*10^301.
That is, if we were to give each atom of the observed cosmos a tray of 1,000 coins, and toss and observe then process 10^14 times per second, the resources of the observed cosmos would sample up to 1 in 10^190 of the set of possibilities.
It is reasonable to deem such a blind search, whether contiguous or a dust, as far too sparse to have any reasonable likelihood of finding any reasonably isolated “needles” in the haystack of possibilities. A rough calc suggests that the ratio is comparable to a single straw drawn from a cubical haystack ~ 2 * 10^45 LY across. (Our observed cosmos may be ~ 10^11 LY across, i.e. the imaginary haystack would swallow up our observed cosmos.)
Of course, as posts in this thread amply demonstrate the “miracle” of intelligently directed configuration allows us to routinely produce cases of functionally specific complex organisation and/or associated information well beyond such a threshold. For an ASCII text string 1,000 bits is about 143 characters, the length of a Twitter post.
As just genomes for OOL start out at 100 – 1,000 k bases and those for OOBP credibly run like 10 – 100+ mn bases, this is a toy illustration of the true magnitude of the problem.
The context and challenge addressed by the active information concept is blind needle in haystack search challenge, and so also FSCO/I. The only actually observed adequate cause of FSCO/I is intelligently directed configuration, aka design. And per further experience, design works by injecting active information coming from a self-moved agent cause capable of rational contemplation and creative synthesis.
So, FSCO/I remains as best explained on design. In fact, per a trillion member base of observations, it is a reliable sign of it. Which has very direct implications for our thought on OOL and OOBP.
Or, it should. END