New UD contributor HeKS notes:
The evidence of purposeful design [–> in the cosmos and world of life] is overwhelming on any objective analysis, but due to Methodological Naturalism it is claimed to be merely an appearance of purposeful design, an illusion, while it is claimed that naturalistic processes are sufficient to achieve this appearance of purposeful design, though none have ever been demonstrated to be up to the task. They are claimed to be up to the task only because they are the only plausible sounding naturalistic explanations available.
He goes on to add:
The argument for ID is an abductive argument. An abductive argument basically takes the form: “We observe an effect, x is causally adequate to explain the effect and is the most common [–> let’s adjust: per a good reason, the most plausible] cause of the effect, therefore x is currently the best explanation of the effect.” This is called an inference to the best explanation.
When it comes to ID in particular, the form of the abductive argument is even stronger. It takes the form: “We observe an effect, x is uniquely causally adequate to explain the effect as, presently, no other known explanation is causally adequate to explain the effect, therefore x is currently the best explanation of the effect.”
Abductive arguments [–> and broader inductive arguments] are always held tentatively because they cannot be as certain as deductive arguments [–> rooted in known true premises and using correct deductions step by step], but they are a perfectly valid form of argumentation and their conclusions are legitimate as long as the premises remain true, because they are a statement about the current state of our knowledge and the evidence rather than deductive statements about reality.
Abductive reasoning is, in fact, the standard form of reasoning on matters of historical science, whereas inductive reasoning is used on matters in the present and future.
And, on fair and well warranted comment, design is the only actually observed and needle in haystack search-plausible cause of functionally specific complex organisation and associated information (FSCO/I) which is abundantly common in the world of life and in the physics of the cosmos. Summing up diagramatically:
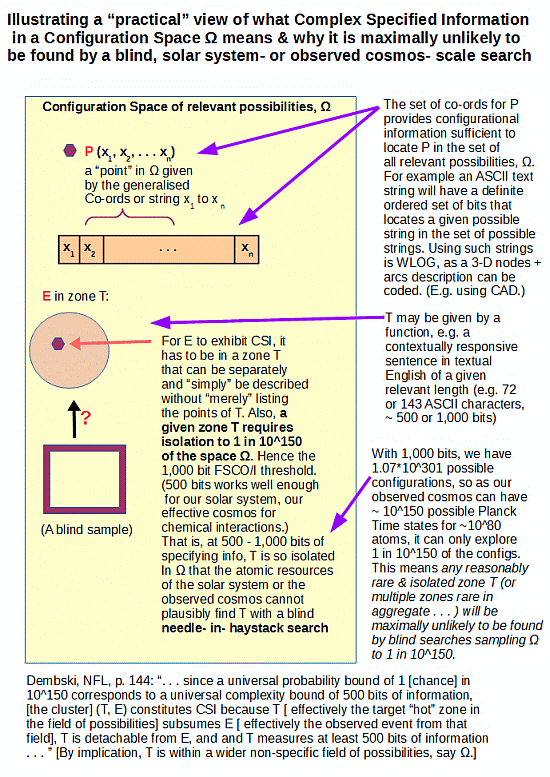
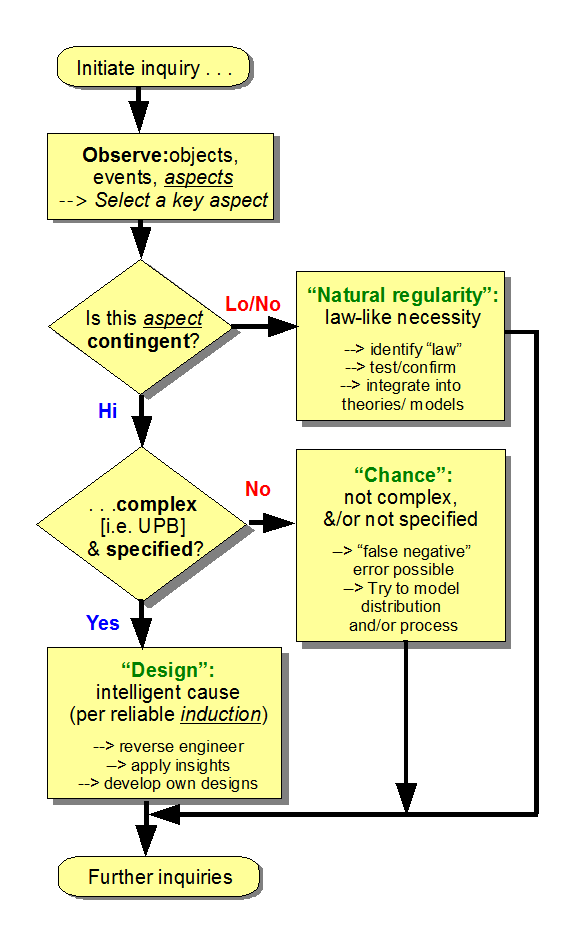
Similarly, we may document the inductive, inference to best current explanation logic of the design inference in a flow chart:
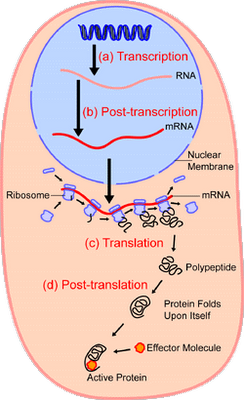
Also, we may give an iconic case, the protein synthesis process (noting the functional significance of proper folding),
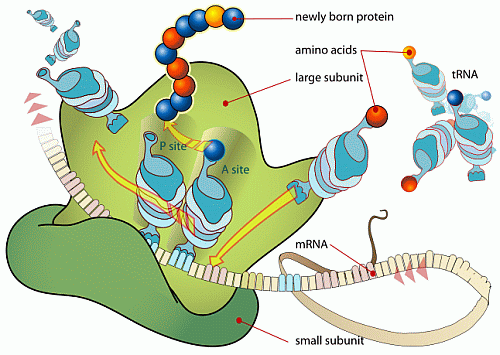
. . . especially the part where proteins are assembled in the ribosome based on the coded algorithmic information in the mRNA tape threaded through the Ribosome:
And, for those who need it, an animated video clip may be helpful:
So, instantly, we may ask: what is the only actually — and in fact routinely — observed causal source of codes, algorithms, and associated co-ordinated, organised execution machinery?
ANS: intelligently directed contingency, aka design, where there is no good reason to assume, imply or constrain such intelligence to humans.
Where also, FSCO/I or even the wider Complex Specified Information is not an incoherent mish-mash dreamed up by silly brainwashed or machiavellian IDiots trying to subvert science and science education by smuggling in Creationism while lurking in cheap tuxedos, but instead the key notions and the very name itself trace to events across the 1970’s and into the early 1980’s as eminent scientists tried to come to grips with the evidence of the cell and of cosmology, as was noted in reply to a comment on the UD Weak Argument Correctives:
. . . we can see across the 1970′s, how OOL researchers not connected to design theory, Orgel (1973) and Wicken (1979) spoke on the record to highlight a key feature of the organisation of cell based life:
ORGEL, 1973: . . . In brief, living organisms are distinguished by their specified complexity. Crystals are usually taken as the prototypes of simple well-specified structures, because they consist of a very large number of identical molecules packed together in a uniform way. Lumps of granite or random mixtures of polymers are examples of structures that are complex but not specified. The crystals fail to qualify as living because they lack complexity; the mixtures of polymers fail to qualify because they lack specificity. [The Origins of Life (John Wiley, 1973), p. 189.]
WICKEN, 1979: ‘Organized’ systems are to be carefully distinguished from ‘ordered’ systems. Neither kind of system is ‘random,’ but whereas ordered systems are generated according to simple algorithms [ –> i.e. “simple” force laws acting on objects starting from arbitrary and common- place initial conditions] and therefore lack complexity, organized systems must be assembled element by element according to an [ –> originally . . . ] external ‘wiring diagram’ with a high information content . . . Organization, then, is functional complexity and carries information. It is non-random by design or by selection, rather than by the a priori necessity of crystallographic ‘order.’ [“The Generation of Complexity in Evolution: A Thermodynamic and Information-Theoretical Discussion,” Journal of Theoretical Biology, 77 (April 1979): p. 353, of pp. 349-65.]
At the turn of the ’80′s Nobel-equivalent prize-holding astrophysicist and lifelong agnostic, Sir Fred Hoyle, went on astonishing record:
Once we see that life is cosmic it is sensible to suppose that intelligence is cosmic. Now problems of order, such as the sequences of amino acids in the chains which constitute the enzymes and other proteins, are precisely the problems that become easy once a directed intelligence enters the picture, as was recognised long ago by James Clerk Maxwell in his invention of what is known in physics as the Maxwell demon. The difference between an intelligent ordering, whether of words, fruit boxes, amino acids, or the Rubik cube, and merely random shufflings can be fantastically large, even as large as a number that would fill the whole volume of Shakespeare’s plays with its zeros. So if one proceeds directly and straightforwardly in this matter, without being deflected by a fear of incurring the wrath of scientific opinion, one arrives at the conclusion that biomaterials with their amazing measure or order must be the outcome of intelligent design. No other possibility I have been able to think of in pondering this issue over quite a long time seems to me to have anything like as high a possibility of being true.” [Evolution from Space (The Omni Lecture[ –> Jan 12th 1982]), Enslow Publishers, 1982, pg. 28.]
Based on things I have seen, this usage of the term Intelligent Design may in fact be the historical source of the term for the theory.
The same worthy also is on well-known record on cosmological design in light of evident fine tuning:
From 1953 onward, Willy Fowler and I have always been intrigued by the remarkable relation of the 7.65 MeV energy level in the nucleus of 12 C to the 7.12 MeV level in 16 O. If you wanted to produce carbon and oxygen in roughly equal quantities by stellar nucleosynthesis, these are the two levels you would have to fix, and your fixing would have to be just where these levels are actually found to be. Another put-up job? . . . I am inclined to think so. A common sense interpretation of the facts suggests that a super intellect has “monkeyed” with the physics as well as the chemistry and biology, and there are no blind forces worth speaking about in nature. [F. Hoyle, Annual Review of Astronomy and Astrophysics, 20 (1982): 16]
A talk given to Caltech (For which the above seems to have originally been conclusive remarks) adds:
The big problem in biology, as I see it, is to understand the origin of the information carried by the explicit structures of biomolecules. The issue isn’t so much the rather crude fact that a protein consists of a chain of amino acids linked together in a certain way, but that the explicit ordering of the amino acids endows the chain with remarkable properties, which other orderings wouldn’t give. The case of the enzymes is well known . . . If amino acids were linked at random, there would be a vast number of arrange-ments that would be useless in serving the pur-poses of a living cell. When you consider that a typical enzyme has a chain of perhaps 200 links and that there are 20 possibilities for each link,it’s easy to see that the number of useless arrangements is enormous, more than the number of atoms in all the galaxies visible in the largest telescopes. This is for one enzyme, and there are upwards of 2000 of them, mainly serving very different purposes. So how did the situation get to where we find it to be? This is, as I see it, the biological problem – the information problem . . . .
I was constantly plagued by the thought that the number of ways in which even a single enzyme could be wrongly constructed was greater than the number of all the atoms in the universe. So try as I would, I couldn’t convince myself that even the whole universe would be sufficient to find life by random processes – by what are called the blind forces of nature . . . . By far the simplest way to arrive at the correct sequences of amino acids in the enzymes would be by thought, not by random processes . . . .
Now imagine yourself as a superintellect working through possibilities in polymer chemistry. Would you not be astonished that polymers based on the carbon atom turned out in your calculations to have the remarkable properties of the enzymes and other biomolecules? Would you not be bowled over in surprise to find that a living cell was a feasible construct? Would you not say to yourself, in whatever language supercalculating intellects use: Some supercalculating intellect must have designed the properties of the carbon atom, otherwise the chance of my finding such an atom through the blind forces of nature would be utterly minuscule. Of course you would, and if you were a sensible superintellect you would conclude that the carbon atom is a fix.
These words in the same talk must have set his audience on their ears:
I do not believe that any physicist who examined the evidence could fail to draw the inference that the laws of nuclear physics have been deliberately designed with regard to the consequences they produce within stars. [“The Universe: Past and Present Reflections.” Engineering and Science, November, 1981. pp. 8–12]
So, then, why is the design inference so often so stoutly resisted?
LEWONTIN, 1997: . . . to put a correct view of the universe into people’s heads we must first get an incorrect view out . . . the problem is to get them to reject irrational and supernatural explanations of the world, the demons that exist only in their imaginations, and to accept a social and intellectual apparatus, Science, as the only begetter of truth [–> NB: this is a knowledge claim about knowledge and its possible sources, i.e. it is a claim in philosophy not science; it is thus self-refuting] . . . .
It is not that the methods and institutions of science somehow compel us to accept a material explanation of the phenomenal world, but, on the contrary, that we are forced by our a priori adherence to material causes [–> another major begging of the question . . . ] to create an apparatus of investigation and a set of concepts that produce material explanations, no matter how counter-intuitive, no matter how mystifying to the uninitiated. Moreover, that materialism is absolute [–> i.e. here we see the fallacious, indoctrinated, ideological, closed mind . . . ], for we cannot allow a Divine Foot in the door. [Billions and billions of demons, NYRB Jan 1997. If you imagine that the above has been “quote mined” kindly read the fuller extract and notes here on, noting the onward link to the original article.]
NSTA BOARD, 2000: The principal product of science is knowledge in the form of naturalistic concepts and the laws and theories related to those concepts [–> as in, Phil Johnson was dead on target in his retort to Lewontin, science is being radically re-defined on a foundation of a priori evolutionary materialism from hydrogen to humans] . . . .
Although no single universal step-by-step scientific method captures the complexity of doing science, a number of shared values and perspectives characterize a scientific approach to understanding nature. Among these are a demand for naturalistic explanations [–> the ideological loading now exerts censorship on science] supported by empirical evidence [–> but the evidence is never allowed to speak outside a materialistic circle so the questions are begged at the outset] that are, at least in principle, testable against the natural world [–> but the competition is only allowed to be among contestants passed by the Materialist Guardian Council] . . . .
Science, by definition, is limited to naturalistic methods and explanations and, as such, is precluded from using supernatural elements [–> in fact this imposes a strawman caricature of the alternative to a priori materialism, as was documented since Plato in The Laws, Bk X, namely natural vs artificial causal factors, that may in principle be analysed on empirical characteristics that may be observed. Once one already labels “supernatural” and implies “irrational,” huge questions are a priori begged and prejudices amounting to bigotry are excited to impose censorship which here is being insitutionalised in science education by the national science teachers association board of the USA.] in the production of scientific knowledge. [[NSTA, Board of Directors, July 2000. Emphases added.]
MAHNER, 2011: This paper defends the view that metaphysical naturalism is a constitutive ontological principle of science in that the general empirical methods of science, such as observation, measurement and experiment, and thus the very production of empirical evidence, presuppose a no-supernature principle . . . .
Metaphysical or ontological naturalism (henceforth: ON) [“roughly” and “simply”] is the view that all that exists is our lawful spatiotemporal world. Its negation is of course supernaturalism: the view that our lawful spatiotemporal world is not all that exists because there is another non-spatiotemporal world transcending the natural one, whose inhabitants—usually considered to be intentional beings—are not subject to natural laws . . . .
ON is not part of a deductive argument in the sense that if we collected all the statements or theories of science and used them as premises, then ON would logically follow. After all, scientific theories do not explicitly talk about anything metaphysical such as the presence or absence of supernatural entities: they simply refer to natural entities and processes only. Therefore, ON rather is a tacit metaphysical supposition of science, an ontological postulate. It is part of a metascientific framework or, if preferred, of the metaparadigm of science that guides the construction and evaluation of theories, and that helps to explain why science works and succeeds in studying and explaining the world. Now this can be interpreted in a weak and a strong sense. In the weak sense, ON is only part of the metaphysical background assumptions of contemporary science as a result of historical contingency; so much so that we could replace ON by its antithesis any time, and science would still work fine. This is the view of the creationists, and, curiously, even of some philosophers of science (e.g., Monton 2009). In the strong sense, ON is essential to science; that is, if it were removed from the metaphysics of science, what we would get would no longer be a science. Conversely, inasmuch as early science accepted supernatural entities as explainers, it was not proper science yet. It is of course this strong sense that I have in mind when I say that science presupposes ON. [In, his recent Science and Education article, “The role of Metaphysical Naturalism in Science” (2011) ]
In short, there is strong evidence of ideological bias and censorship in contemporary science and science education on especially matters of origins, reflecting the dominance of a priori evolutionary materialism.
To all such, Philip Johnson’s reply to Lewontin of November 1997 is a classic:
For scientific materialists the materialism comes first; the science comes thereafter. [Emphasis original.] We might more accurately term them “materialists employing science.” And if materialism is true, then some materialistic theory of evolution has to be true simply as a matter of logical deduction, regardless of the evidence. That theory will necessarily be at least roughly like neo-Darwinism, in that it will have to involve some combination of random changes and law-like processes capable of producing complicated organisms that (in Dawkins’ words) “give the appearance of having been designed for a purpose.”
. . . . The debate about creation and evolution is not deadlocked . . . Biblical literalism is not the issue. The issue is whether materialism and rationality are the same thing. Darwinism is based on an a priori commitment to materialism, not on a philosophically neutral assessment of the evidence. Separate the philosophy from the science, and the proud tower collapses. [Emphasis added.] [The Unraveling of Scientific Materialism, First Things, 77 (Nov. 1997), pp. 22 – 25.]
Please, bear such in mind when you continue to observe the debate exchanges here at UD and beyond. END